解决方案:6CMS采集发布之文章批量采集发布工具
优采云 发布时间: 2022-10-27 00:22解决方案:6CMS采集发布之文章批量采集发布工具
最近有很多站长朋友问我网站有必要做cms采集发布吗?有没有好用的软件cms采集在一个发布,批量监控采集+batch伪原创+batch多站发布cms在同时。
1、为什么要发布cms采集
对于站长来说,为了更好的提升网站的收录,提升网站的排名,需要更频繁的丰富网站的内容。这需要使用各种采集 工具来采集 所需的文章 资源。
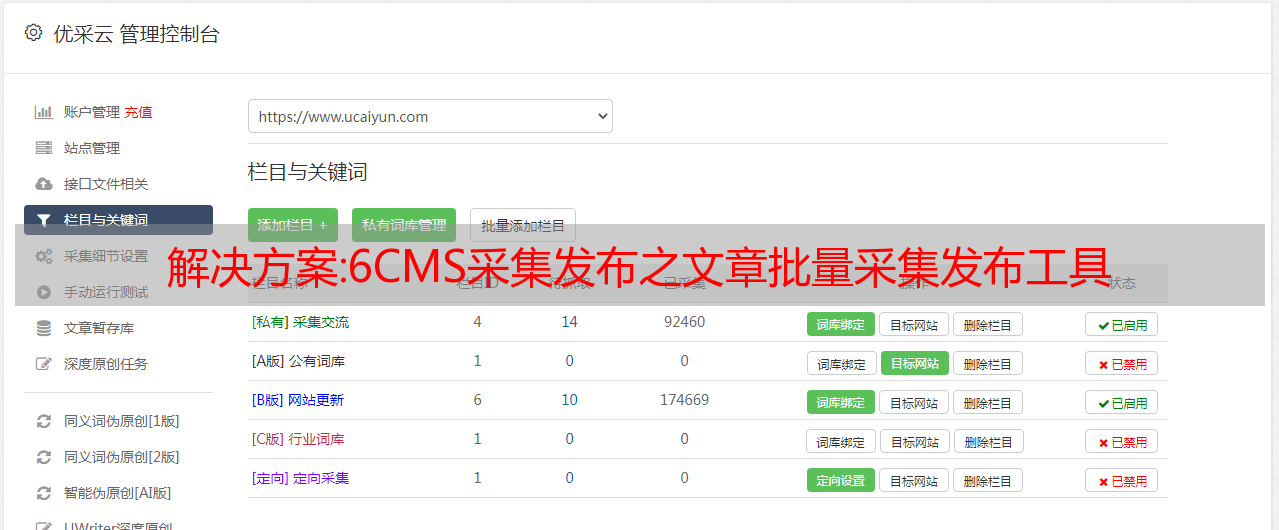
然后这些站长有很多cms网站(Empirecms、WordPress、DEDEcms、易友cms等)cms背景不一样,每次采集 到本地,要使用不同的发布软件发布,每次对每个伪原创 再发布。如果我想有一个可以批量管理不同cms的软件,市面上还没有找到这样的工具,而且定制开发的成本太贵了。更多的是使用插件,招募更多的人。
例如,公司有 100 个 网站,所有这些都由 SEO 优化器维护和优化。网站类型有 Empirecms、WordPress、织梦、ThinkPHP 等。如果使用优采云采集发布这样的工具,首先每个站需要大量的采集文章,针对不同的cms发布,这样日常的工作就是检查是否所有的站采集都已经发布了。不说复杂的配置过程,还要分心观察发布是否成功。耗费大量人力财力,效率极低!
2、cms采集发布会会影响网站的质量吗?
首先要知道什么是质量文章。什么才是高质量的内容?标题要与内容一致,内容要流畅易读,文章内容要丰富完整,文章图片要清晰,每一个都要写ALT属性图片。尽量减少弹出窗口和广告的使用。文章没有关键词叠加等作弊。如果这样做了,然后用 cms采集文章 发布,那么我们可以称之为高质量的 文章。这不会影响 网站 的质量。
3. 如何为cms采集发布制作高质量的网站内容?
cms采集发布的内容是为了用户的需要。cms采集发布的文章应尽快提交给搜索引擎。采集这是百度等搜索引擎的严厉打击,严重的甚至是K站。使用 cms采集 在 文章 和其他过度优化的行为中发布尽可能少的穿插锚文本。并且不要欺骗用户通过 cms采集 发布一些相关性差、质量低的 文章。不要乱用 H 标签。
SEO全平台cms批量发布工具特点:
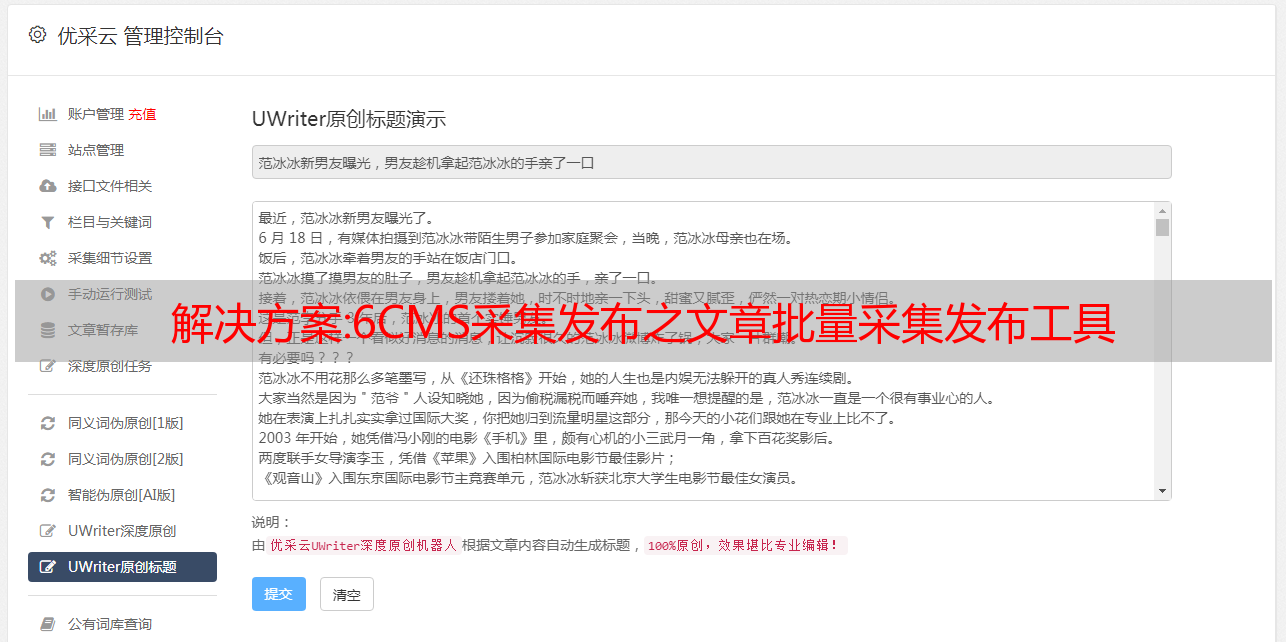
伪原创工具:无缝连接优采云、优采云等采集软件,支持本地批处理伪原创+支持网站API接口
cms发布:支持Empire、Yiyou、ZBLOG、织梦、WP、PB、Apple、搜外等主流cms,可同时管理和发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发布一篇文章
监控数据:已发布、待发布、是否伪原创、发布状态、URL、节目等。
并且发布完成后,百度、搜狗、360、神马可以在同一个软件平台上直接推送,实现全平台发布管理cms,批量伪原创,自动批量推送全平台,软件强大,不止一点点!
操作方法:jspXCMS用户采集管理的方法是什么
本篇文章主要介绍jspXcms用户采集管理方法的相关知识。内容详细易懂,操作简单快捷,具有一定的参考价值。相信你已经看完了这篇文章。文章jspXcmsuser采集什么是管理方式文章会有收获,一起来看看吧。
采集您可以将其他网站的文章、新闻采集转移到自己的系统中。在将旧系统迁移到新系统时,也可以使用采集将旧系统采集的数据转移到新系统。
系统自带了一些网站采集规则,但是如果相关的网站页面发生变化,可能会导致采集不正确。
原则
采集主要分析两类页面:栏目列表页面和文章详情页面。网站的文章一般按栏目分类,先找到栏目列表页面为采集,分析页面源码找到文章列表代码,然后分析获取文章的URL地址;然后分析文章详情页的源码,解析出标题、发布日期、文字等数据。
如何查看网页的 HTML 源代码
在浏览器页面空白处右键(不要右键图片或文字),会弹出一个菜单(个别网站会屏蔽右键),点击“查看页面源代码" 在菜单中(每个浏览器的名称会略有不同),将显示页面的 HTML 源代码。
采集列表
点击后台功能导航中的“生成”-“采集管理”,进入采集列表页面。
采集添加
在“采集管理列表”页面点击“添加”。
转到 采集添加页面。
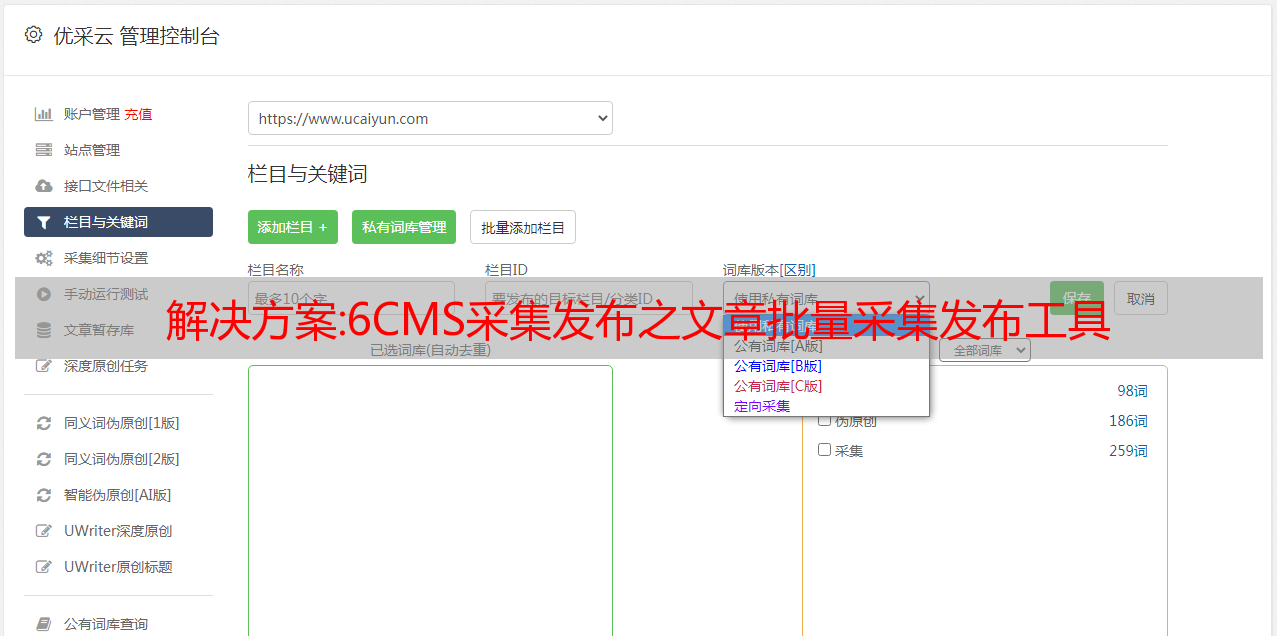
名称:采集 的名称。
保存到列:采集的数据保存到哪一列。
页面编码:采集的页面编码。通常是 UTF-8 或 GBK。如果编码设置不正确,会出现乱码。查看页面源代码为采集确认编码格式,如:. 如果页面显示的编码是GB2312,也可以设置为GBK,因为GBK收录GB2312。
是否提交:“否”,采集收到的数据为“采集”状态,审核后显示在网站上;“是”是 采集 的用户对于提交的数据,如果 采集 用户具有最终审核权限,则 采集 收到的数据处于“已发布”状态,将被直接显示在 网站 上。
间隔时间:采集上一个数据到下一个数据的间隔时间,取最小值和最大值之间的随机数。一些网站会阻塞频繁访问的请求,在采集数据期间随机间隔,可以模拟普通用户浏览网站的行为。
User Agent:User Agent,模拟浏览器访问的User Agent信息,通常默认为“Mozilla/5.0”。浏览器访问网站时会携带User Agent信息,包括浏览器版本、操作系统版本等信息。有的网站会根据User Agent信息判断是普通用户浏览还是机器爬虫访问。如果机器爬虫访问 网站,网站 可能会拒绝访问或返回不同的页面。如果遇到此类问题,可以设置一个更像浏览器访问的User Agent。
列表地址:采集 的列表页地址。您可以填写多个条目,每行一个。可以使用占位符(*),将其替换为“页数”,例如:(*).shtml,页数为2到10,相当于...。
倒序采集:如果页数为2到10,则从第10页开始采集。
文章URL地址:从列列表页解析文章详情页的地址。区域HTML,选择列表页中文章列表的区域;项目 HTML,从区域 HTML 中选择 文章 详细页面的 URL 地址。是否正则表达式:是否通过正则表达式匹配。
文章URL地址设置
设置“列表地址”后,点击“文章URL地址”处的“设置”进入设置页面。设置页面可以测试匹配规则,验证匹配规则是否正确。
这里有一些乱码,是新浪的列表页编码(GB2312)和详情页编码(UTF-8)不同造成的。因为采集的内容主要是在详情页,UTF-8作为采集的页面编码,不影响采集的效果。同一个网站的列表页和详情页很少有不同的代码。可能在修改过程中,只改了一半,另一半还没改。
URL地址集:顶部的下拉框显示采集新页面“List Page Address”的URL地址集。如果每个列表页面不完全相同,可以选择不同的页面来验证匹配规则是否通用。
HTML源代码:左侧区域为采集的栏目列表页面的HTML源代码,点击“获取”重新加载当前URL地址的HTML源代码。
区域HTML:首先匹配列表页的详情页列表区域。(*) 是匹配内容的占位符。匹配规则对空格和换行很敏感,可以用来更好地匹配。设置好匹配规则后,点击“匹配”,左侧“HTML源代码”会显示匹配结果,如果没有达到效果,可以点击“获取”,修改匹配规则,重新匹配。对于复杂的页面,可以勾选“正则表达式”来应用java正则表达式。
项目HTML:确定区域HTML后,点击区域HTML的“匹配”按钮,左侧“HTML源代码”显示匹配结果,然后设置入口HTML匹配规则,点击“匹配”,从匹配结果区域HTML,页面的匹配详情URL。(*) 是匹配内容的占位符。此时可以看到详情页的URL地址显示在左侧的“HTML源代码”中,说明匹配规则设置成功。点击“确定”按钮,设置的内容将被写回采集新页面。
正则表达式匹配
对于复杂的页面,占位符(*)的方法可能无法达到匹配的效果。在这种情况下,可以使用万能的正则表达式。勾选“正则表达式”开启正则表达式模式,正则表达式用括号()匹配。
由于 html 收录换行符,因此您不能直接使用 . 匹配任何字符,但使用 [\d\D] 匹配任何字符。
采集字段列表
采集新增列表页,定义列表页为采集,解析列表页详情页的URL地址。
保存“采集添加”后,点击“字段列表”。
转到“采集字段列表”页面。此时没有设置任何字段,列表中也没有数据。
采集已添加字段
在“采集管理 - 字段列表”页面上单击“添加字段”。
转到 采集 字段添加页面。
此处显示的字段与文档模型相关。不必添加所有字段。常用的字段是标题、正文和发布时间。检查所需的新字段,然后单击“保存”。
采集字段设置

