最新版:论坛discuz注入(Discuz论坛插件今日头条文章自动采集发布)
优采云 发布时间: 2022-10-26 14:19最新版:论坛discuz注入(Discuz论坛插件今日头条文章自动采集发布)
只需输入我们的关键词,我们就可以在今日头条热门下拉列表中执行采集文章
Discuz采集工具可以通过我们的关键词进行全网匹配采集,不仅可以采集为头条文章,其他公开信息内容等。 ,我们也可以通过指定采集来执行采集,进入我们的目标网站链接,通过采集函数点击我们需要的数据和元素采集在视觉列表页面中,只需启动我们的任何 URL 采集。
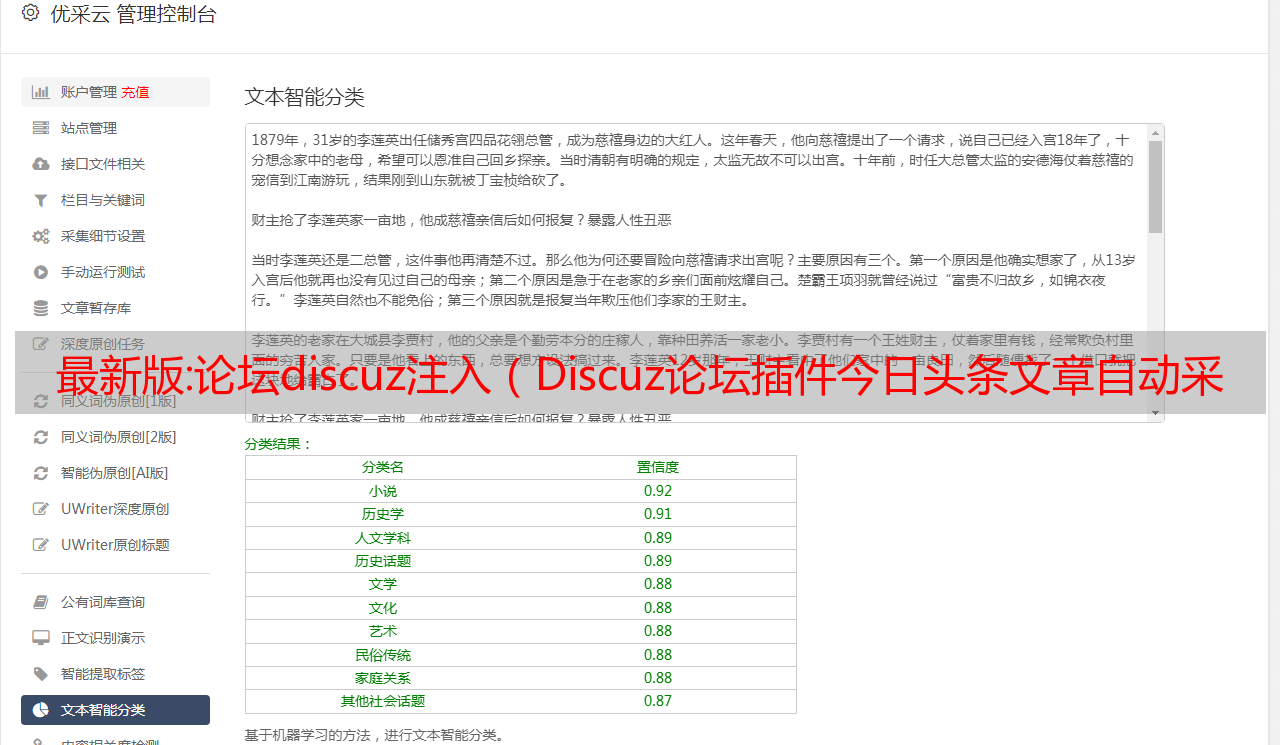
通过关键词采集和指定的网站采集,我们可以获取当前的热点新鲜资讯和话题,通过我们的自动发布实现Discuz论坛的内容更新, Discuz采集 工具还支持多个账号同时发布。针对我们不同的马甲,在不同的时间发布不同的内容。
Discuz采集 工具还具有关键词 挖掘功能。通过输入我们的关键词,搜索引擎可以拉下长尾关键词以及语义相近的相关词进行挖掘,方便了我们。采集使用 关键词、长尾关键词 以及此类内容中的相关字词发布我们的内容,我们希望提供一份 Discuz 解决方案列表,我们根据客户研究选择解决这些问题.
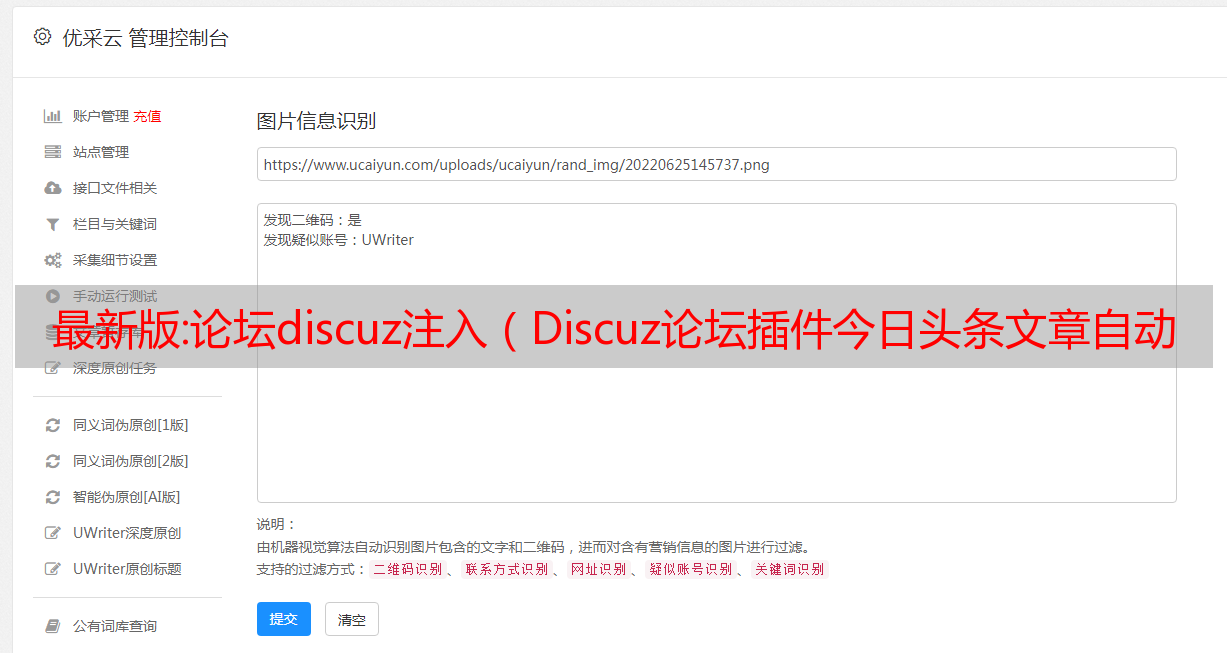
也许我们提供预先创建的服务,并希望解决那些难以增加其 .AU 域存在的客户。了解客户的关键 Discuz 绝对可以突出我们的产品或服务与我们的竞争对手相比的最佳方面。比较帖子还具有在关键字搜索中利用竞争对手的功能。品牌优势的好处 使用他们的 Discuz 关键字搜索我们竞争对手的客户可能会看到我们的帖子,从而发现我们的品牌。
与比较帖子类似,此内容模板提供了竞争对手的替代品列表。例如,“2022 年最佳 Microsoft 套件替代品”同样,这种类型的内容将有利于利用竞争对手的品牌来获得优势。寻找竞争对手替代品的客户天生就准备好并愿意与其他人签约。
这只能从转换的角度很好地解决问题 文章 - 这种类型的内容描述了客户的 Discuz 以及如何在这种类型的 文章、帖子或视频中修复它的操作指南教程,我们的产品或服务被非常温和地展示以解决手头的问题,它们不必是简单的分步指南 - 例如,如果我们销售联络中心解决方案,我们可以提供诸如“如何提供一致的客户服务”等。
如此精妙绝伦的艺术,实在是怎么强调都不过分。客户不想阅读广告。他们想要与他们的问题产生共鸣的内容,并为他们的问题找到可行的解决方案。以上所有原型都需要彻底了解客户的 Discuz 以及他们如何找到实现所有四个的解决方案。这是使我们的内容多样化并确保尽可能多的关键字搜索链接到我们的内容的好方法。
外媒:TTBot: 今日头条机器人
示例代码:
# 参考上述的返回评论数据示例,可以获得相关的必须参数
item_id = '6689315272605565452'
comment_id = '6689386720494043147'
reply_text = '这是一个测试回复'
reply_to_user_id = '86931246069'
# 发表评论回复
account.post_reply(reply_text,item_id,comment_id,reply_to_user_id)
返回的 JSON 数据:
{
'message': 'success',
'data':
{
'comment':
{
'is_pgc_author': false,
'is_owner': false,
'text': '这是一个测试回复',
'content': '这是一个测试回复',
'create_time': 1562680661,
'reply_id': 0,
'user':
{
'verified_reason': '',
'screen_name': '贩卖咸鱼的木木',
'avatar_url': 'http://p1.pstatp.com/thumb/b724000372257b2b92aa',
'user_id': 95480041731,
'name': '贩卖咸鱼的木木',
'author_badge': [],
'user_auth_info': '',
'user_verified': false,
'description': '说出你要的视频哟~~!!',
},
'id': 6711662322362318860, // 此条回复的id
},
'comment_id': 6689386720494043147, // 回复的评论id
},
}
示例代码:
title = '这是一个测试的悟空问答 问题'
content = '这是问题的具体描述'
image = r'C://pictures/test.jpg'
image_list = [r'C://pictures/test01.jpg',r'C://pictures/test02.jpg']
# 发表悟空问答 并附上本地图片一张
account.post_question(title,content,image)
# 发表悟空问答 并附上本地图片多张,使用列表
account.post_question(title,content,image_list)
返回的结果数据示例:
{'qid': '6711665324736905475', 'err_no': 0, 'err_tips': ''}
示例代码:
# 转发 用户 阿里达摩院扫地僧(uid:6636211626)的文章(id:6689315272605565452)
repost_content = '转发并评论的内容'
uid = '6636211626'
item_id = '6689315272605565452'
# 转发并评论
account.repost(repost_content,item_id,uid)
返回的结果数据示例:
{
'message': 'success',
'data':
{
'open_url': '/group/6711667304335802382/',
'group_id': 6711667304335802382,
},
}
示例代码:
# 删除 上一项 自己发布的一个转发并评论 阿里达摩院扫地 的微头条,
# comment=True 表示此条微头条属于转发类型,如果属于转发类型的微头条,
# 删除时必须指定 comment=True
account.delete_media('6711667304335802382',comment=True)
# 如果是一般自己发布的图文微头条,则不用传入comment的值
account.delete_media('1638551478768651')
# 如果需要删除的是自己发布的小视频,则需使用 delete_video 函数,传入该小视频 id即可
account.delete_video('6711667304335802382')
返回数据示例:
{'message': 'success'}
示例代码:
# 删除一个自己发布的头条图文作品需要知道该图文文章的 id
item_id = '6709615853203096071'
account.delete_article(item_id)
返回数据示例:
{'code': 0, 'message': 'success', 'data': null}
那里
是标题图形作品的五种出版状态:已出版,失败,正在审查中,撤回和草稿。
相应的传入参数为:已通过、未通过、选中、隐藏、拔模
您可以根据关键词,开始时间和结束时间搜索和删除相关的图形作品
的工作
示例代码:
# 删除 自己图文作品中 未通过审核的 所有作品
account.delete_articles(status='unpassed')
# 删除 自己图文作品中 通过审核的 且 包含关键词 “测试”、发布时间 位于 2019-07-01 至 2019-07-03 的所有作品
account.delete_articles(status='passed',keyword='测试',start_date='2019-07-01',end_date='2019-07-03')
示例代码:
# 需要传入 问题id
account.delete_wenda_draft('6711665324736905475')
返回结果数据示例:
{'err_no': 0, 'err_tips': ''}
可以删除的悟空问答问题只能是正在审查的问题。
示例代码:
# 需要传入 问题id
account.delete_question('6706694894238302478')
返回结果示例:
// 问题审核中 已经删除
{'qid': '6711866197685567758', 'err_no': 0, 'err_tips': ''}
// 问题已过审核无法删除
{'qid': '6706694894238302478', 'err_no': 65546, 'err_tips': '问题状态不符合操作条件'}
示例代码:
# 需要传入 素材图片的uri 即 以pgc-image 的web_uri
account.delete_resource_img('pgc-image/266565ea60cb42c3a54b94ebdc58923a')
返回结果数据示例:
{'message': 'success', 'now': 1562742921, 'data': '', 'reason': ''}
必需参数:标题媒体(文章、视频、微标题)的group_id。
示例代码:
account.store_media('6711635660941296132')
返回结果数据示例:
{'message': 'success'}
必需参数:标题媒体(文章、视频、微标题)的group_id。
示例代码:
account.unstore_media('6711635660941296132')
返回结果数据示例:
{'message': 'success'}
必需参数:需要阻止的用户 uid
示例代码:
account.block_user('6681325527')
返回的结果数据示例:
{'message': 'success', 'now': 1562744234, 'data': '', 'reason': '拉黑成功!'}
必需参数:需要取消阻止用户 uid
示例代码:
account.unblock_user('6681325527')
返回的结果数据示例:
{'message': 'success', 'now': 1562744303, 'data': '', 'reason': '取消拉黑成功!'}
必填参数:需要点赞的评论ID,MP平台只能操作作者自己的文章相关评论
示例代码:
account.like_comment('6707339641345097735')
返回的结果数据示例:
{'message': 'success', 'now': 1562745148, 'data': '', 'reason': '点赞成功'}
必填参数:需要点赞的评论ID,MP平台只能操作作者自己的文章相关评论
示例代码:
account.unlike_comment('6707339641345097735')
返回的结果数据示例:
{'message': 'success', 'now': 1562745323, 'data': '', 'reason': '取消点赞成功'}
必需参数:前文章 文章的 ID 创建时间戳create_time
示例代码:
account.set_top_article('6711941566493098504',create_time='1562745675')
返回的结果数据示例:
{'message': 'success', 'now': 1562746670, 'data': '', 'reason': '文章置顶成功'}
必需参数:您需要取消固定顶部文章 文章创建时间戳create_time
示例代码:
account.cancel_top_article('6711941566493098504',create_time='1562745675')
返回的结果数据示例:
{'message': 'success', 'now': 1562746748, 'data': '', 'reason': '文章取消置顶成功'}
必需参数:需要从主页中撤消(隐藏)的文章 ID
示例代码
account.hide_article('6711941566493098504')
返回的结果数据示例:
{'code': 0, 'message': 'success', 'data': None}
必需参数:显示的文章 ID 需要从主页恢复
示例代码:
account.unhide_article('6711941566493098504')
返回的结果数据示例:
{'code': 0, 'message': 'success', 'data': None}
必需参数:您需要传入库存图像的 URI,即 pgc 图像的web_uri
示例代码:
account.star_resource_img('pgc-image/a8dc04c83f194adc9d0b56365e42fe50')
返回的结果数据示例:
{'message': 'success', 'now': 1562807025, 'data': '', 'reason': ''}
必需参数:您需要传入库存图像的 URI,即 pgc 图像的web_uri
示例代码:
account.unstar_resource_img('pgc-image/a8dc04c83f194adc9d0b56365e42fe50')
返回的结果数据示例:
{'message': 'success', 'now': 1562807115, 'data': '', 'reason': ''}
默认情况下,存储进入 MongoDB 数据库。与无需登录即可获取用户关注列表一致
示例代码:
# 获取所有的关注用户 并存入数据库
account.get_followings(ALL=True,MDB=True)
# 获取前100个关注用户 并存入数据库
account.get_followings(count=100,MDB=True)
返回的结果数据示例与从 中获取的单个用户 JSON 数据一致
默认情况下,存储进入 MongoDB 数据库。与无需登录即可获取用户风扇列表一致
示例代码
# 获取所有的可见粉丝用户 并存入数据库
account.get_fans(ALL=True,MDB=True)
# 获取前100个粉丝用户 并存入数据库
account.get_fans(count=100,MDB=True)
返回的结果数据示例与从中获取用户粉丝列表的单用户 JSON 数据一致
示例代码:
# 获取 头条媒体(文章、视频、微头条)相关评论通知数
media_noty = account.get_notification_count()
# 获取账户 新的粉丝数
unread_fans_count = account.get_unread_fans_count()
# 获取 得到的 问题邀请数
wenda_invited = account.get_wenda_invited_count()
返回的结果数据示例:
// media_noty 有相关的评论 微头条2个新的评论,文章有1个新的评论
{'video_pgc_count': 0, 'graphic_count': 1, 'wtt_count': 2}
// unread_fans_count data 字段 1 表示有一个新的粉丝
{'message': 'success', 'now': 1562810209, 'data': 1, 'reason': ''}
// wenda_invited 表示收到4个问题邀请
{'invite_count': 4}
示例代码:
account.get_blocking_users()
返回的结果数据示例:
[
{
'avatar_url': 'http://p1.pstatp.com/thumb/6edc0005cd0d88147ac6',
'user_id': 3784676286,
'name': '野史日记',
},
{
'avatar_url': 'http://p1.pstatp.com/thumb/173b60001126f6279daa9',
'user_id': 104957058916,
'name': '旅行诗人安安',
},
]
示例代码:
# 获取所有的订阅者数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的subscribers键值
account.get_subscribers(MDB=True)
# 获取100个订阅者数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的subscribers键值
account.get_subscribers(count=100,MDB=True,ALL=False)
返回的结果数据示例:
[
{
'following': 1, //是否你也关注了ta 1是 0否
'avatar_url': 'http://p3.pstatp.com/thumb/fe480000747798606b4c',
'user_id': 54009707197,
'screen_name': '刺派',
},
{
'following': 0,
'avatar_url': 'http://p1.pstatp.com/thumb/fe2c00002330aae7dbc5',
'user_id': 4160017817,
'screen_name': '水沐禅心34491537',
}
]
示例代码:
# 获取所有的收藏列表数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的favourite键值
account.get_favourites(MDB=True)
# 获取100条收藏列表数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的favourite键值
account.get_favourites(count=100,ALL=False,MDB=True)
返回结果列表的单个 JSON 数据示例:
示例代码:
# 获取所有的悟空问答草稿箱数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的wenda_draft键值
account.get_wenda_drafts(MDB=True)
# 获取100条悟空问答草稿箱数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的wenda_draft键值
account.get_wenda_drafts(count=100,ALL=False,MDB=True)
返回结果列表的单个 JSON 数据示例:
示例代码:
# 获取当前登陆用户所有的微头条、转发数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的comments键值
account.get_posts(MDB=True)
# 获取100条当前登陆用户的微头条、转发数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的comments键值
account.get_posts(count=100,ALL=False,MDB=True)
返回结果列表的单个 JSON 数据示例:
示例代码:
# 获取当前登陆用户所有的小视频数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的my_videos键值
account.get_videos(MDB=True)
# 获取100条当前登陆用户的小视频数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的my_videos键值
account.get_videos(count=100,ALL=False,MDB=True)
返回结果列表的单个 JSON 数据示例:
图形作品有五种出版状态:已出版,失败,审查中,撤回和草稿。
相应的传入参数为:已通过、未通过、选中、隐藏、拔模
您可以根据作品关键词(参数关键字)、开始时间(参数start_date)和结束时间(参数end_date)搜索并获取相关图形作品。
示例代码:
# 获取当前登陆用户所有的图文作品数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的my_articles键值
account.get_posted_articles(MDB=True)
# 获取100条当前登陆用户所有的图文作品数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的my_articles键值
account.get_posted_articles(count=100,ALL=False,MDB=True)
# 获取100条当前登陆用户正在审核中的图文作品数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的my_articles键值
account.get_posted_articles(count=100,ALL=False,MDB=True,status='checking')
# 获取100条当前登陆用户于 2019-07-01 至 2019-07-09 发布的正在审核中的 图文作品数据并存入数据库,数据库名称在 config.py 中MONGODB设置里的my_articles键值
account.get_posted_articles(count=100,ALL=False,MDB=True,status='checking',start_date='2019-07-01',end_date='2019-07-09')
# --- 对获取到的单条数据进行回调处理 参数:item_callbcak---
'''
想对爬取到的单条数据进行增删改字段等操作,可以使用回调函数:
假设想对获取到的每一条图文数据 打印其当前状态,可以使用自己定义一个回调函数如下(callback_print_status):
'''
def callback_print_status(account,item):
'''
第一个参数永远都是account,代表当前登陆账户,
第二个参数表示的便是获取到的原始单条json数据 具体内容可以查看下面的数据示例
返回:
None 表示处理完后继续执行后续代码;
1 表示处理完后忽略后续处理代码;
元组(item,200) 表示用item替换原先的单条数据再继续后续代码处理
'''
print(item.get('status_desc'))
# 使用回调函数处理每一条数据
account.get_posted_articles(item_callback=callback_print_status)
返回结果列表的单个 JSON 数据示例:
示例代码:
#获取粉丝互动排行榜的第一页 数据的先后顺序表示了互动由高至低的排行
account.get_interact_fans(page=1)
返回的结果 JSON 数据示例:
示例代码:
# 获取素材库 全部图片 的 第二页 每页20条显示
account.get_resource_images(page=2,pagesize=20)
# 获取素材库 收藏图片 的 第一页 每页20条显示
account.get_resource_images(page=1,pagesize=20,saved=True)
返回的结果 JSON 数据示例:
{
'message': 'success',
'now': 1562900747,
'data': {
'total_count': 77, //素材库图片总数
'resource_list': [
{
'create_time': 1562720147, //上传时间
'is_saved': false, //当前图片是否是收藏图片
'resource_id': 'pgc-image/a8dc04c83f194adc9d0b56365e42fe50',
}
],
'page_index': 1, //当前页码
'page_size': 20, //每页显示条数
},
'reason': '',
}
示例代码:
# 获取账户登陆操作日志 的 第二页 每页20条显示
account.get_login_op_log(page=2,pagesize=20)
返回的结果 JSON 数据示例:
{
'data':
{
'op_log': [
{
'login_time': '2019-07-10T10:43:25+08:00',
'timestamp': 1562726605,
'ip_addr': '201.18.***.***',
'device': '电脑',
'device_name': 'Windows',
'app_name': '今日头条(Web版)',
'login_method': '密码登录',
},
],
},
}
示例代码:
# 获取账户敏感操作日志 的 第二页 每页20条显示
account.get_sensitive_op_log(page=2,pagesize=20)
返回的结果 JSON 数据示例:
{
'data':
{
'op_log': [
{
'op_time': '2018-09-17T18:43:28+08:00',
'timestamp': 1537181008,
'ip_addr': '134.67.***.***',
'device': '电脑',
'device_name': 'Windows',
'action': '修改密码',
'Action': 402,
},
],
'total': 1,
},
'message': 'success',
}
示例代码:
# 通过 本地图片上传
account.upload_resource_img_by_open(r'C://pictures/test.jpg')
# 通过 网络图片地址 上传
account.upload_resource_img_by_url('http://www.xxx.com/test.jpg')
返回结果数据示例:
{
'message': 'success',
'data': {
'url_list': [
{'url': 'http://p3.pstatp.com/origin/242a500005c02321b60e8'},
{'url': 'http://pb9.pstatp.com/origin/242a500005c02321b60e8'},
{'url': 'http://pb1.pstatp.com/origin/242a500005c02321b60e8'}
<p>
],
'web_uri': '242a500005c02321b60e8',
},
}</p>
示例代码:
# 获取'2019-07-01'至'2019-07-13'发布的小视频数据分析数据
account.small_videos_analysis('2019-07-01','2019-07-13')
返回的结果 JSON 数据示例:
{
'err_no': 0,
'list': [
{
'id': '6712621136334553100',
'href': 'http://toutiao.com/item/6712621136334553100/',
'title': 'test',
'play_count': 0, //播放量
'comment_count': 0, //评论数
'collect_count': 0, //收藏数
'forward_count': 0, //转发数
'average_progress': 0, // 平均进度
'recommend_ratio': 0,
'follow_ratio': 0,
},
],
'message': 'success',
'totalPage': 1,
}
仅获取过去 7 天的答案数据
示例代码:
account.wenda_analysis()
返回的结果 JSON 数据示例:
{
'message': 'success',
'now': 1562904171,
'data':
{
'go_detail_count': 3, //阅读量
'answer_count': 0, //回答数
'digg_count': 1, //点赞数
},
'reason': '',
}
示例代码:
#获取 2019-07-10至2019-07-12的 粉丝增长数据
account.get_fans_trend('2019-07-10','2019-07-12')
返回的结果 JSON 数据示例:
{
'message': 'success',
'now': 1562904306,
'data': {
'itemList': [
{
'date': '20190710',
'totalCount': 9, //粉丝总数
'incrCount': 0, //增长数
'decrCount': 0, //减少数
'netGrowthCount': 0, //净增长数
},
{
'date': '20190711',
'totalCount': 9,
'incrCount': 0,
'decrCount': 0,
'netGrowthCount': 0,
}
],
'end_date': '2019-07-12',
'start_date': '2019-07-10',
},
'reason': '',
}
示例代码:
#获取 2019-07-10至2019-07-12 发布作品的概况趋势数据
account.get_content_overview('2019-07-10','2019-07-12')
返回的结果 JSON 数据示例:
{
'message': 'success',
'now': 1562904519,
'data': {
'comment_count': 1,
'surbscribe_go_detail_count': 0,
'go_detail_count': 11, //阅读量
'end_date': '2019-07-11',
'repin_count': 0, //收藏量
'detail_list': {
// 列表的元素数对应天数
'surbscribe_go_detail_count': [0, 0],
'go_detail_count': [10, 1],
'repin_count': [0, 0],
'impression_count': [1368, 270],
'comment_count': [0, 1],
'share_count': [0, 0],
'publish_num': [0, 0],
},
'share_count': 0, //转发量
'impression_count': 1638, //推荐量总数
'start_date': '2019-07-10',
'publish_num': 5,
},
'reason': '',
}
目前,只编写了用于与某些用户交互的代码,具体如下:给定用户UID列表,指定日期范围内指定数量的评论和转发的交互功能或列表中最近发布的文章,视频和微标题。
对于具体的参数分析,您可以查看组件.toutiao模块的interact_with_users函数的源代码注释
示例代码:
account.interact_with_users(
uids=['50025817786','6026436452'], # 想要进行交互的用户uid列表
**{ 'comment_on_weitt':True, # 是否对这些用户的微头条进行评论
'comment_start_time':'2019-06-17 00:00:00', # 进行评论的用户头条媒体发布的开始时间范围
'comment_end_time':'2019-06-18 00:00:00', # 进行评论的用户头条媒体发布的结束时间范围
'comment_on_video':True, # 是否对这些用户的视频进行评论
'comment_on_article': True, # 是否对这些用户的文章进行评论
'comment_txt':'TTBot评论', # 对文章、视频、微头条进行评论的 共同评论内容
'comment_article':'这是对文章的评论', # 对文章的评论,如果comment_txt参数已有,此项无效。需要comment_on_article为True
'comment_count':1, # 对各个类别(文章、视频、微头条)多少条数据进行评论
'repost_on_article':False, # 是否对列表里的用户进行文章的转发
'repost_txt':'TTBot转发', # 转发头条媒体(文章、视频、微头条)时的评论内容
'repost_count':1# 对各个类别(文章、视频、微头条)多少条数据进行转发并评论
}
)
9. 定时器
计时器可以在给定时间调用特定函数。具体模块是:组件.计时器
主要功能是设置和运行可见的函数注释
具体用途:
示例代码:
from component.toutiao import TTBot
bot = TTBot()
'''
定时任务 1:
1. 定时于 2019-07-20 15:10:00 执行 用户交互函数 interact_with_users
2. args 为 希望交互的用户uid列表,也是 interact_with_users 函数的位置参数
3. kwargs 为 interact_with_users 函数的关键字参数
'''
bot.timer.setup(
'2019-07-20 15:10:00',
bot.interact_with_users,
args=(['75953693736','65445676041'],),
kwargs={
'comment_on_weitt':True,
'comment_start_time':'2019-06-17 00:00:00',
'comment_end_time':'2019-06-18 00:00:00',
'comment_txt':'定时器评论',
'comment_count':1,
'repost_on_article':True,
'repost_txt':'定时器转发',
'repost_count':1
},
)
'''
定时任务 2:
1. 定时于 2019-07-25 15:10:00 使用登陆账户发布微头条 函数为 bot.account.post_weitt
2. args 为 bot.account.post_weitt 需要的位置参数,元组格式
3. looping 为 true 表示这个定时器任务会循环执行,间隔一段时间执行一次
4. frequency 为6 表示 这个定时器任务 1个小时内执行6次,也就是规定了间隔时间为:3600/6=600秒=10分钟
即是10分钟执行一次
5.args_func 表示每一次任务执行时 函数bot.account.post_weitt 需要的位置参数 改变函数,即:
第一次执行时 参数args为:('这是一个定时测试的微头条',) 执行完毕后 间隔10分钟
第二次执行时 参数 args 为:
args = lambda x:(f'{x[0]}-{time.time()}',) 的结果,其中x为第一次的参数,即:x=('这是一个定时测试的微头条',)
所以 第二次执行的 args 为 ('这是一个定时测试的微头条-156663545.3658',)
依次类推,第三次执行时 参数args即为第二次执行时的args传入args_func后的结果
6.callbcak 函数为 执行完一次 定时函数bot.account.post_weitt 后的回调函数,其参数为 bot.account.post_weitt的返回结果
即:
此处callback=lambda x:print(x),当定时任务执行后,x=bot.account.post_weitt('这是一个定时测试的微头条')
即x为定时函数的返回结果传给callback回调
'''
bot.timer.setup(
'2019-07-25 15:10:00',bot.account.post_weitt,
args=('这是一个定时测试的微头条',),
looping=True,
frequency=6,
args_func=lambda x:(f'{x[0]}-{time.time()}',),
callback=lambda x:print(x))
# 注册完需要的定时任务1、2后 ,调用run运行定时器
bot.timer.run()
# 或者直接调用
bot.run_timer_jobs()
后续待办事项赞助支持
纯粹的个人维护,除了工作之外(通常在周末和半夜)。
也许你可以给我买一杯咖啡:)
支付宝:
微信:

