汇总:如何收集|采集数据1
优采云 发布时间: 2022-10-25 18:18汇总:如何收集|采集数据1
之前圆圆发过一篇关于数据分析的文章文章,里面提到了如何根据数据做分析,分析的具体思路是什么。这次我想谈谈我们如何捕获更多数据,它使用的方法和工具。
我们使用的工具是优采云。这一次,我们将解释获取大量产品标题和获取这么多标题文本的过程。目的是分析最佳标题以优化我们自己的标题。
优采云 是采集数据的工具,但数据仅限于文本信息。比如各个平台的商品标题文字信息的采集,方便我们从大量的数据中分析出我们想要的信息,降低了采集信息的时间成本和人力成本。
但是优采云是一个机器人,我们需要按照它的逻辑输入我们的指令。每一步点击搜索都需要再次点击“优采云”指令才能成功完成信息采集。
优采云的页面介绍:左边是功能区。点击新建,导入任务,可以导入别人发来的命令任务,也可以输入自己想要的命令任务,规则文件为 . 您还可以创建一个新的任务组来存储导入的任务)。
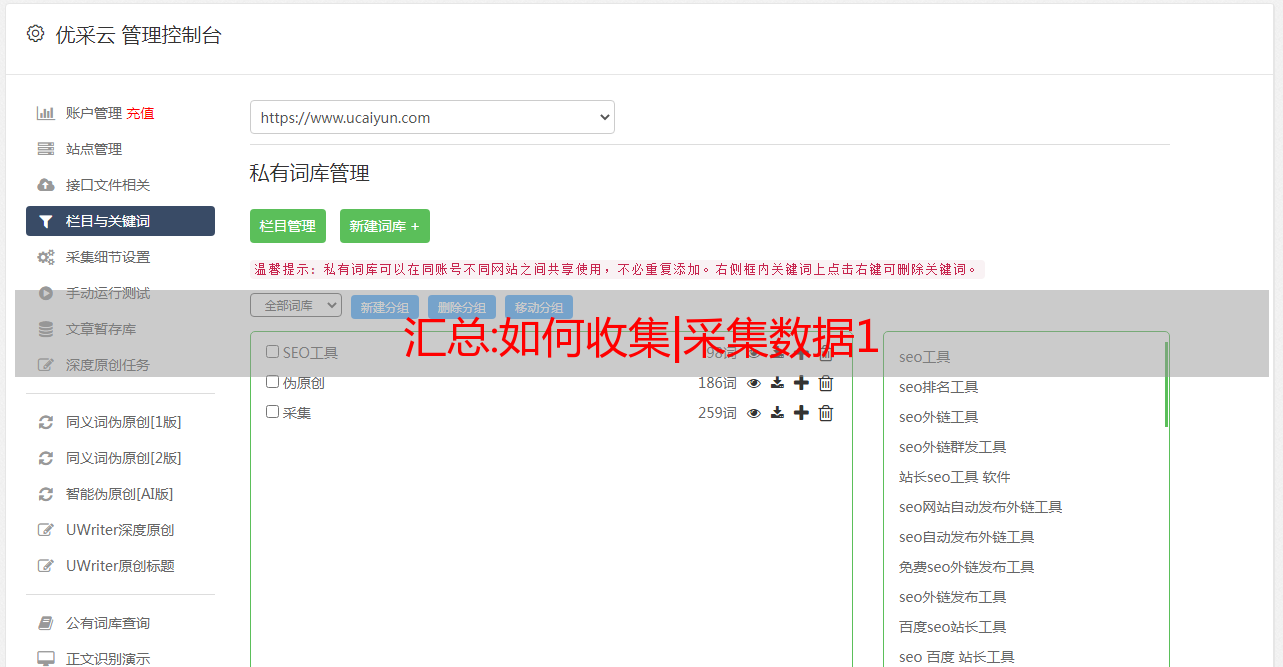
优采云页
标题信息采集可以选择单页信息采集,一般适用于采集某页的数据。只有“打开网页”和“提取数据”两个步骤,这是最基本的流程。
步:
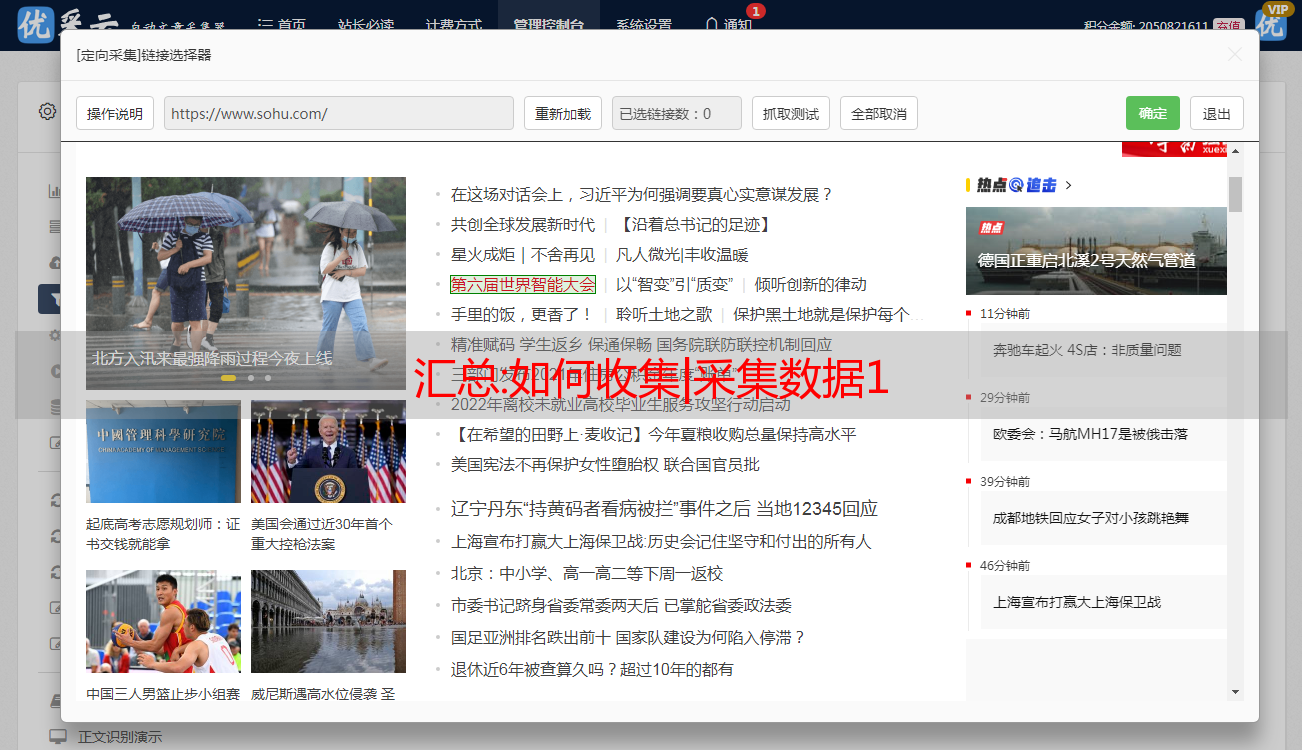
1、打开优采云,点击“新建”,选择自定义任务,手动输入导入URL,保存设置。系统会自动进入网址页面
2、进入信息采集,在右侧提示的“文本框”中输入要搜索的内容。然后在搜索结果页面点击产品标题,点击二,标题变为绿色,表示选择成功,点击采集
3、点击采集后,选择“本地采集”进行第一步数据导出
4.填写信息采集后,可以选择导出方式
汇总:如何高效的进行数据采集
随着人工智能和大数据技术的飞速发展,数据作为智能商业时代的重要生产要素,不仅受到互联网企业的重视,也受到众多希望通过数据实现转型升级的传统企业的重视。 . 互联网现在可以说是一个庞大的数据库资源,是一个杂乱无章、无组织的大型数据库。商业智能时代,如何有效提取数据价值,在竞争中脱颖而出?也正因为如此,今天出现了一个更专业的名词——网络爬虫。
网络爬虫是一种自动获取网页内容的程序,也是搜索引擎的重要组成部分。只要网站可以正常访问,爬虫也可以轻松访问和爬取。所谓数据抓取,其实就是模拟普通人批量访问目标网站获取有价值的信息,自动采集,减少人工干预。
简单来说,如果你在从事一些文章的编辑工作,手稿的参考文献量非常大,但是手动查找既费时又费力。熬夜加班找信息效率低下很不方便。如果你有爬虫技术,就不会那么麻烦了。选择几大搜索网站,提取你需要的文章关键词全网搜索并自动保存,然后自己休眠获取同类型<从@k7@中选择优质的> . 该爬虫在互联网数据的抓取、处理、分析和挖掘方面专业可靠,为大数据的发展提供了强有力的支持。
为了让爬虫更高效,多线程的爬虫程序也是必不可少的。多线程意味着同时处理多个任务,可以大大提高资源利用效率,提高信息采集的工作效率。
多线性爬虫代码如下:
import requests
<p>
import threading
def fetch(url):
response = requests.get(url)
print('Get %s: %s' % (url, response))
h1 = threading.Thread(target = fetch, args = ("http://jshk.com.cn/",))
h2= threading.Thread(target = fetch, args = ("https://v.duoip.cn/",))
h3= threading.Thread(target = fetch, args = (" https://www.taobao.com/",))
h1.start()
h2.start()
h3.start()
h1.join()
h2.join()
h3.join()
</p>

