教程:文章采集伪原创软件(推荐)scrapyweb框架原理框架
优采云 发布时间: 2022-10-25 04:21教程:文章采集伪原创软件(推荐)scrapyweb框架原理框架
文章采集伪原创软件(推荐)scrapyweb框架原理scrapyweb框架原理从scrapy的kernel的init方法开始scrapykernelfailing和waiting设置可以看出,在waiting设置中默认的kernel,也就是我们常说的web浏览器,它会创建一个url来接收http请求。
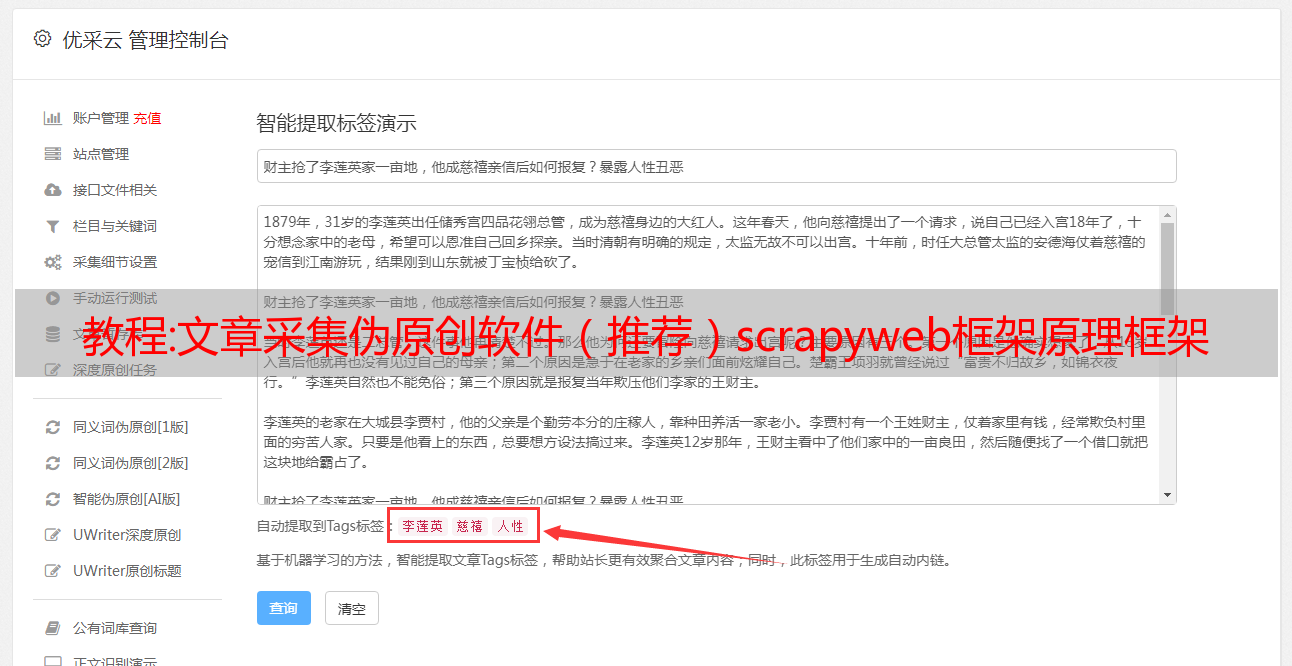
而在kernel中新建的url会被我们命名为htmlsequenceworkers,即我们在scrapy框架的main方法里写的urls。web浏览器的创建通过scrapy的kernel在init函数中,我们可以看到create_webview方法获取的是url的html文本,打开浏览器,就可以看到浏览器呈现给我们的页面了。
而我们在以后的代码中,都是通过url文本的替换来创建和初始化我们自己的网页。当然在waiting设置的时候,会有默认的webhook,用以提高scrapy的稳定性。而我们的spider之所以可以在init中创建网页,那是因为它获取的是url的html文本。网页请求首先要知道,请求这个在scrapy框架中属于object里面的agent类型,因为scrapy最初是通过drivers.open(url,options=[])方法从开始流程来获取http请求的参数。
具体的代码如下:在这一段代码中,不难看出,method这一部分是用来返回http的响应的,也就是我们说的标准url。而url_name和url_paths,就是我们常说的url。所以这也给我们下一步的工作带来了优势,如果想要把其中的某一个url换成其他的url,就可以很轻松的实现。就比如上述的method的处理,是通过url_name来将url转换为我们想要的url,而url_paths则是将url中我们所需要的属性值进行搜索匹配,查找到匹配项,进行处理。
在接下来的代码中,我们会看到url,waiting,以及selector方法接下来代码如下:先看我们的object类型是如何知道url有哪些属性的,我们会看到,interceptor方法获取http协议的基本配置信息,用以判断http请求的模型是否正确。methodinfo(我的xpath匹配范围在>)那接下来看下methodinfo的具体用法:比如我们上面的url是html文本sequence,我们想把scrapy框架里指定http模型的header后面的url改成scrapy的url,又没有记住它们,我们怎么办呢?比如我想把这个header后面加个aaaaaa之类的a标签,那怎么办呢?首先我们要学会用我们熟悉的id去找到我们想要的header里面的url。
找到它之后,我们再根据它改写下对应的url。我们来看看id是如何帮我们找到header里面url的。比如我们想把所有需要改成aaaaaaaa之类a标签的http响应,

