总结:自动采集编写自动脚本,将关键词抓取下来解析合并文本文件
优采云 发布时间: 2022-10-24 23:12总结:自动采集编写自动脚本,将关键词抓取下来解析合并文本文件
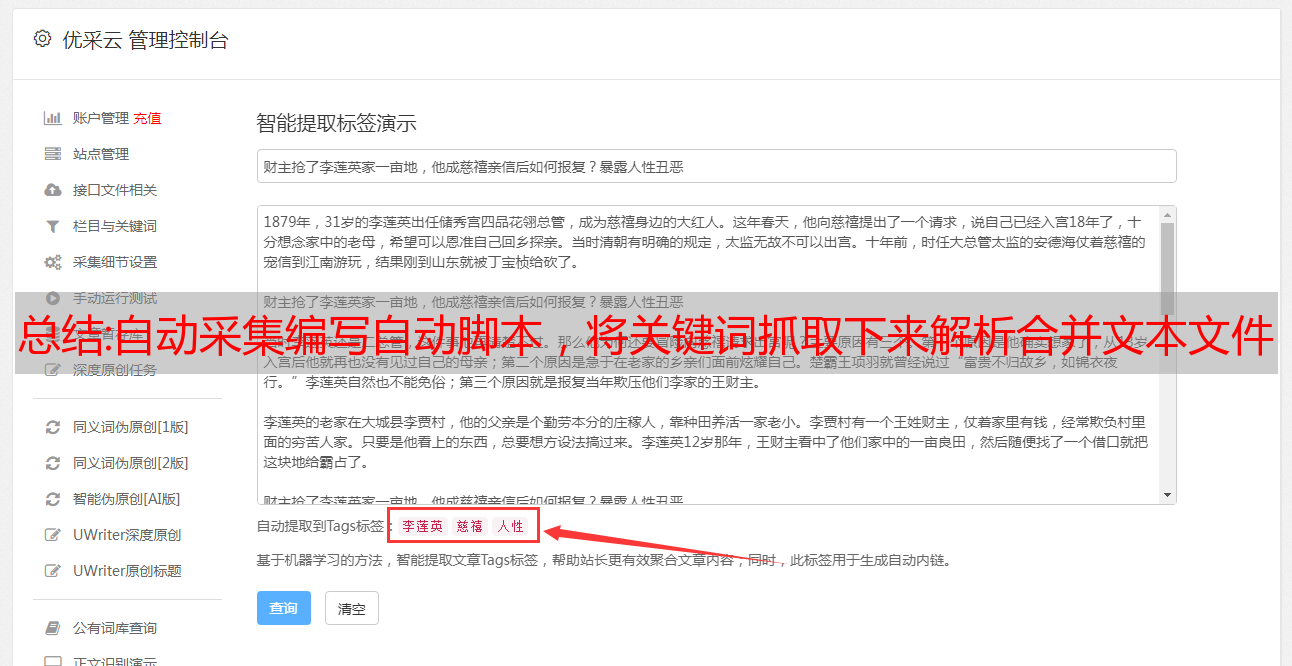
自动采集编写自动采集脚本,将关键词抓取下来解析合并文本文件将数据抓取下来,合并成json合并到数据库关键词采集想扩展功能,想写脚本,咋办?采集页限制太多咋办?关键词抓取下来后,怎么处理?好多老手在处理页限制的问题,第一时间采取的办法是清空数据,方便后续处理,但是对于新手来说,又不知道该怎么办。我将在文章后面会有一步步详细说明,并录制gui过程。
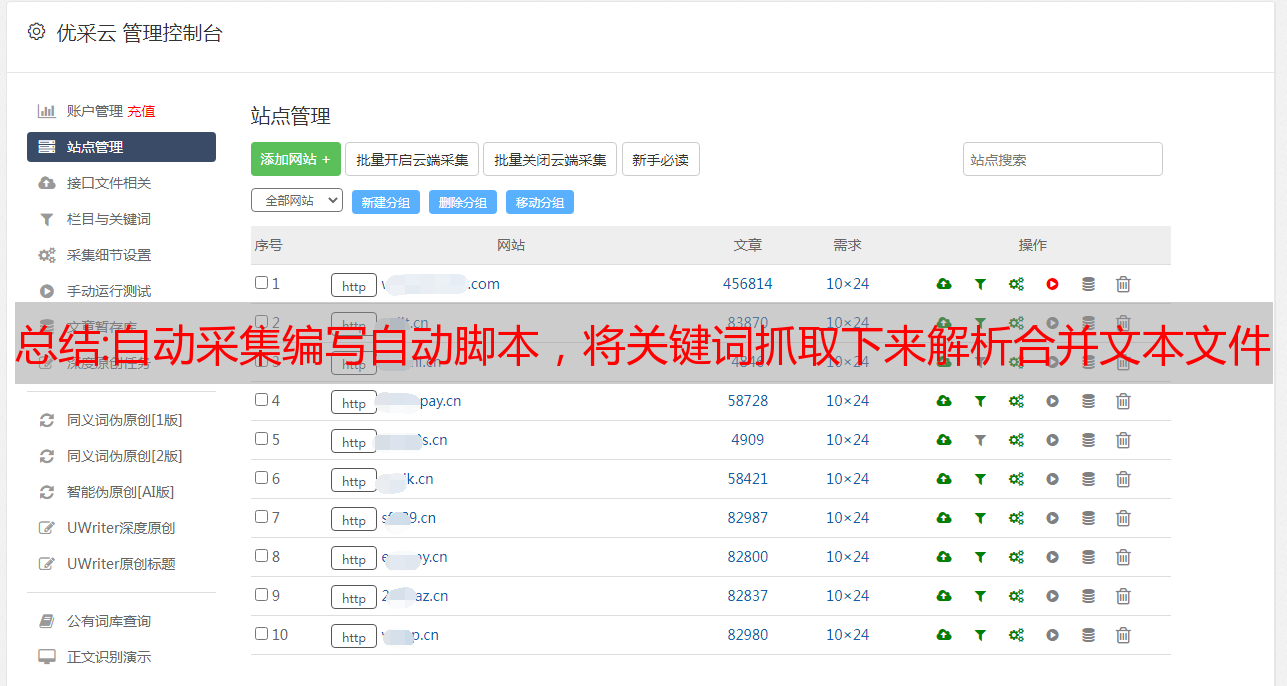
文章首发,先录制一部分看看效果关键词抓取这个工作相信是java开发者非常熟悉的工作,但是实际运用起来应该怎么做呢?本节课,我们直接从页限制抓取开始吧!页限制抓取大家在刚刚学习网页爬虫的时候,肯定接触过pagecontainer对象,非常方便我们在一个页面后台接收所有页面的数据。例如你爬取淘宝的购物车的时候,用pagecontainer创建了一个新的页面,你会新增500条购物车数据接收。
那如果数据增加了怎么办呢?该怎么办呢?刚刚我已经说过,pagecontainer对象有个特点,当你增加页限制时候,页限制会清空掉,所以我们可以这样做:清空页限制请求新页面,页限制清空通过特殊手段将页限制找回root页面,页限制清空我们直接看代码,请求淘宝(去重后):我们通过某个方法找回页限制:同样的,我们也要采用一些特殊的代码才能达到效果:代码1#openurl.html#openurl.htmlmypagecontainer=openurl("d:\users\administrator\username\downloads\");step1:去重step2:去重之后,数据再次去重step3:将页限制找回,返回=[]step4:遍历d:\users\administrator\username\downloads\"java\tomcat-jre-8.0.170\protocols\tomcat7-4.0.30\conf\tomcat8\server\"java\tomcat-jre-8.0.170\protocols\tomcat7-4.0.30\conf\tomcat7-4.0.30\shadowsocket\");step5:页限制清空step6:访问10000000:8000000;step7:所有页限制代码详解(等下,还有难点)1.加载包importjava.util.arraylist;importjava.util.list;importjava.util.dictionary;/***网页去重后,页限制清空**@author罗天笑*liuxianwen263*/publicclasstest123456截图清空2.利用到模块:finishdatamanager框架importjava.util.list;importjava.util.dictionary;/***进程锁*进程锁存储模块*/publicclass进程锁{/***进程锁状态*thread.status显示进程锁。

