解决方案:迅睿cms系统企业建站站群管理开源系统源码下载(CI4框架)
优采云 发布时间: 2022-10-24 21:47解决方案:迅睿cms系统企业建站站群管理开源系统源码下载(CI4框架)
迅锐cms产品开源免费,VIP版和免费版代码相同,源代码永久免费开源,免费二次开发软件属于所有PHPer和编程爱好者
多终端,站群管理
电脑网站、手机网站、APP界面等多种方式实现数据展示和采集;分站数据独立,不影响系统性能,会员系统共享,同步登录注册
会员用户系统,单点登录
自定义用户群模型,微信、微博,直接登录或绑定账号,一个用户可以同时拥有多个用户群;单点登录访问其他 网站 帐户以同步注册和登录
多元化内容,自定义字段
内置多种常用模型,开发者也可以自定义模块以满足网站的需求;自定义字段可应用于系统模块、表单、成员、评论等渠道
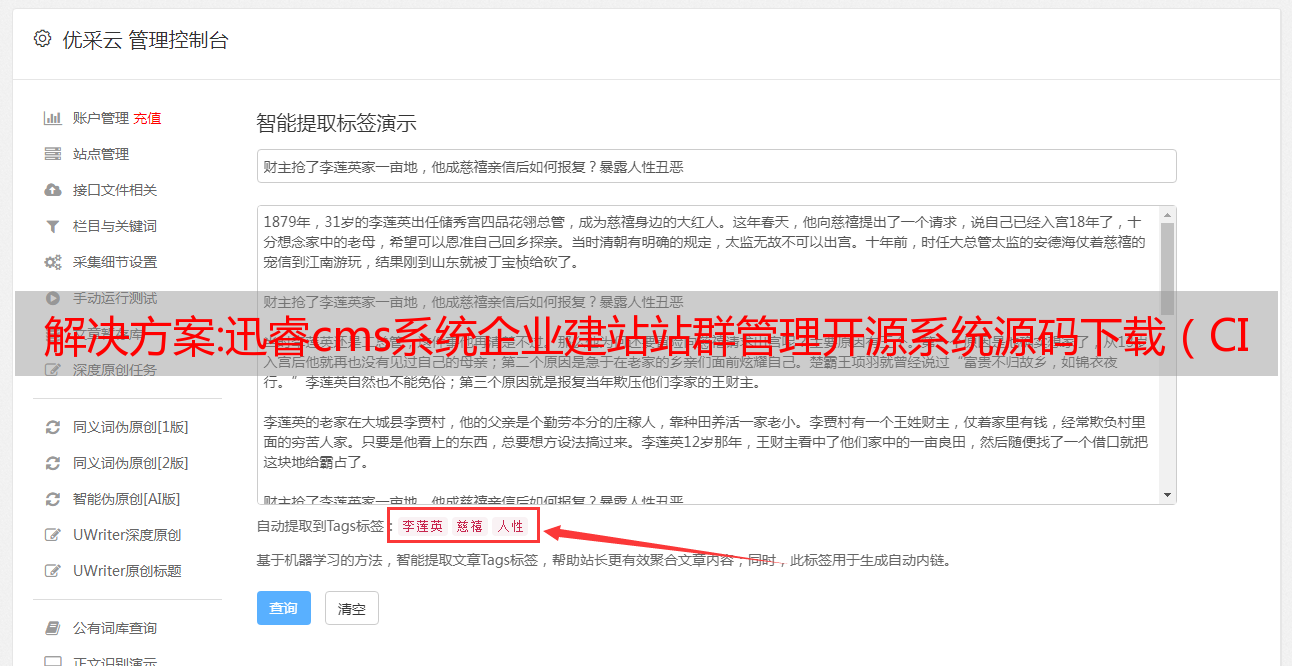
电子商务支付功能、商品交易功能
微信、支付宝、*敏*感*词*支付、银行汇款等多种支付方式,支持余额提取;通用交易系统,任何内容模块都有购买功能,支持SKU型号定价
自定义通用表格
传统的网站表单用于消息、反馈、注册、调查等功能;模块表单是依赖于内容的自定义表单,用于文章反馈、文章注册、子文章、小节等。
自定义 URL,智能伪静态
自由灵活的URL定义方式,使模块、内容、列表、搜索的自定义地址系统自动将定义的URL转换为对应的伪静态代码并智能解析
操作环境
PHP7.2以上 MySQL5以上 5.7+ Apache, Nginx, IIS 推荐
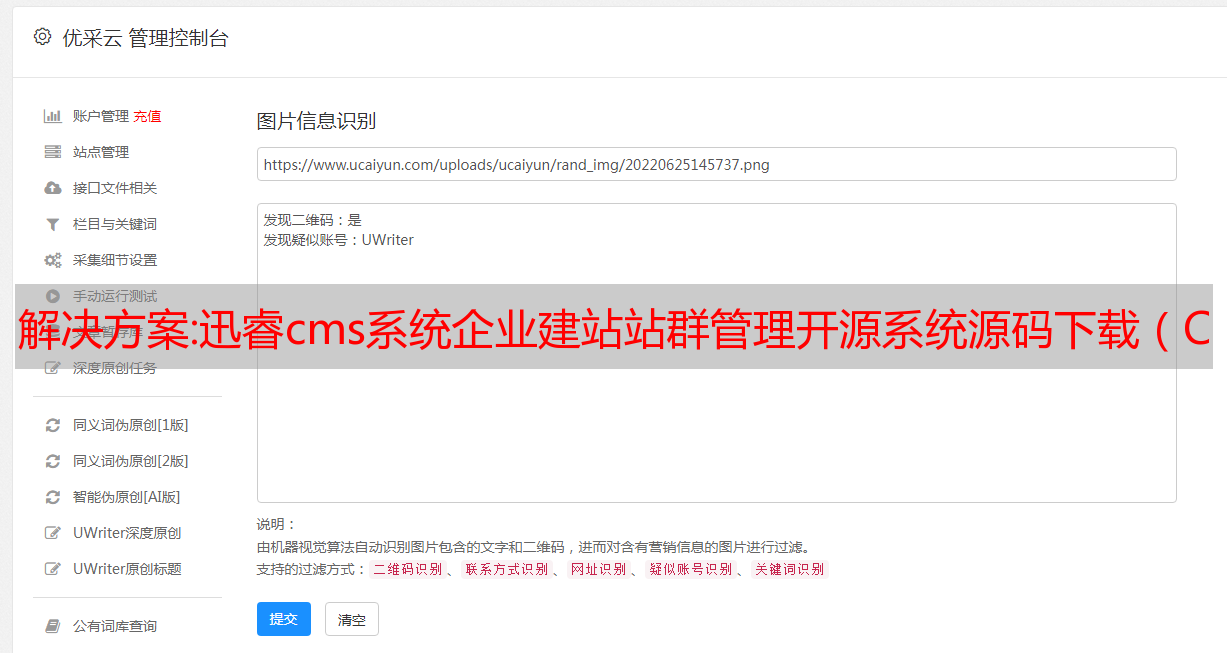
安装教程 将代码下载到网站根目录运行安装文件/install.php 不要安装在子目录下
解析
转载请注明出处:游鱼资源网 » 迅锐cms系统企业搭建站站群管理开源系统源码下载(CI4框架)
本文永久地址:
解决方案:基于Golang的云原生日志采集服务设计与实践
<p style="white-space: normal;color: rgb(62, 62, 62);letter-spacing: 0.544px;font-size: 15px;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;background-color: rgb(255, 255, 255);text-size-adjust: auto;word-spacing: 2px;text-align: center;">点击上方"云时代架构"右上角选择“设为星标”
精品技术文章准时送上!</p>
1. 背景
云原生技术的浪潮已经到来,技术变革迫在眉睫。
在这一技术趋势下,网易推出了青州微服务云平台,集微服务、Servicemesh、容器云、DevOps等于一体,在公司集团内部得到广泛应用,也支持众多外部客户的云原生转型。和迁移。
其中,日志是很容易被忽视的部分,但却是微服务和DevOps的重要组成部分。没有日志,就无法解决服务问题。同时,日志采集的统一也是很多业务数据分析、处理、审计的基础。
但是在云原生容器化环境中,采集 的日志有点不同。
2、容器日志的痛点采集
传统主机模式
对于部署在传统物理机或虚拟机上的服务,日志采集工作清晰明了。
业务日志直接输出到主机,服务运行在固定节点上。手动或使用自动化工具,在节点上部署日志采集代理,添加代理配置,然后启动采集日志。同时,为了方便后续的日志配置修改,也可以引入配置中心,发布代理配置。
Kubernetes 环境
在 Kubernetes 环境中,情况并非如此简单。
一个 Kubernetes 节点上运行着很多不同服务的容器,容器的日志存储方式也有很多种,例如 stdout、hostPath、emptyDir、pv 等。由于频繁的主动或被动迁移,频繁的销毁和在 Kubernetes 集群中创建 Pod,我们不能像传统方式那样手动向每个服务发出 log采集 配置。另外,由于日志数据会集中存储在采集之后,所以根据namespace、pod、container、node等维度,甚至是环境变量和标签等维度对日志进行检索和过滤是非常重要的。容器。
以上都不同于传统log采集配置方式的需求和痛点。究其原因,传统方式与Kubernetes脱节,无法感知Kubernetes,无法与Kubernetes集成。
随着近年来的快速发展,Kubernetes 已经成为容器编排的事实标准,甚至可以被视为新一代的分布式操作系统。在这个新的操作系统中,控制器的设计思想驱动着整个系统的运行。控制器的抽象解释如下图所示:
由于 Kubernetes 良好的可扩展性,Kubernetes 设计了自定义资源 CRD 的概念。用户可以自己定义各种资源,在一些框架的帮助下开发控制器,用控制器把我们的期望变成现实。
基于这个思路,对于日志采集,记录一个服务需要采集,需要什么样的日志配置,是用户的期望,而这一切都需要我们开发一个日志采集 的控制器来实现。
3. 探索与建筑设计
有了上面的方案,除了开发一个控制器,剩下的就是围绕这个思路做一些选型分析了。
记录采集代理选择
log采集controller只负责连接Kubernetes和生成采集配置,不负责真正的log采集。目前市面上有很多log采集代理,比如传统ELK技术栈的Logstash、CNCF*敏*感*词*项目Fluentd、最近上线的Loki、beats系列的Filebeat等。下面进行简要分析。
代理集成
对于log采集agent,在Kubernetes环境中一般有两种部署方式。
一种 sidecar 方法,即与业务容器部署在同一个 Pod 中。这样Filebeat只需要采集业务容器的日志,只需要配置容器的日志配置,简单隔离。很好,但是最大的问题是每个服务必须有一个Filebeat才能去采集,通常一个节点上的Pod很多,加起来内存等开销并不乐观。
另一种也是最常见的方法是在每个节点上部署一个 Filebeat 容器。相比之下,内存占用一般要小很多,而且对 Pod 没有侵入性,更符合我们平时的使用习惯。
同时普遍采用Kubernetes的DaemonSet部署,省去了Ansible等传统自动化运维工具,部署和运维效率大幅提升。
所以我们优先使用 Daemonset 来部署 Filebeat。
整体结构
选择Filebeat作为日志采集代理,集成自研日志控制器后,从节点的角度来看,我们看到的架构如下:
日志平台下发特定的 CRD 实例到 Kubernetes 集群,日志控制器 Ripple 负责 List&Watch Pods 和来自 Kubernetes 的 CRD 实例。
通过Ripple的过滤和聚合,最终生成一个Filebeat输入配置文件。配置文件描述了服务的采集Path路径、多行日志匹配等配置,还默认配置了PodName、Hostname等到日志。在元信息中。
Filebeat 会根据 Ripple 生成的配置自动重新加载并采集 登录节点,并发送到 Kafka 或 Elasticsearch。
由于 Ripple *敏*感*词* Kubernetes 事件,它可以感知 Pod 的生命周期。无论 Pod 被销毁还是调度到任何节点,它仍然可以自动生成相应的 Filebeat 配置,无需人工干预。
Ripple 可以感知 Pod 挂载的日志卷。无论是docker Stdout的日志,还是HostPath、EmptyDir、Pv存储的日志,都可以在节点上生成日志路径,告诉Filebeat去采集。
Ripple 可以同时获取 CRD 和 Pod 信息,所以除了默认在日志配置中添加 PodName 等元信息外,还可以结合容器环境变量、Pod 标签、Pod Annotation 等对日志进行标记,以方便后续的日志过滤、检索和查询。另外,我们在Ripple中加入了定期清理日志等功能,保证日志不丢失,进一步增强了日志采集的功能和稳定性。
四、基于Filebeat的实践
功能扩展
总的来说,Filebeat 可以满足大部分 log采集 的需求,但是还是有一些特殊的场景需要我们自定义 Filebeat。当然,Filebeat 本身的设计也提供了很好的扩展性。Filebeat目前只提供了elasticsearch、Kafka、logstash等几种类型的输出客户端,如果我们想让Filebeat直接发送到其他后端,需要自定义自己的输出。同样,如果您需要过滤日志或添加元信息,您也可以制作自己的处理器插件。不管是加输出还是写处理器,Filebeat提供的大体思路基本一致。一般来说,有3种方式:
直接fork Filebeat,在已有源码上开发。
无论是输出还是处理器都提供了类似Run、Stop等接口,你只需要实现这类接口,然后在init方法中注册对应的插件初始化方法即可。
当然,由于Golang中的init方法是在导入包的时候调用的,所以需要在初始化Filebeat的代码中手动导入。
复制一份Filebeat的main.go,导入我们自研的插件库,重新编译。
本质上,它与方法1没有太大区别。
Filebeat 还提供了基于 Golang 插件的插件机制。需要将自研插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库的路径。
然而,事实上,一方面,Golang 插件还不够成熟和稳定。另一方面,自研插件仍然需要依赖同版本的libbeat库,也需要用同版本的Golang编译。可能坑比较多,不推荐。
如果想了解更多关于 Filebeat 的设计,可以参考我们的文章文章。
()
为了支持各业务方的对接,我们扩展了grpc输出的开发,支持多个Kafka集群的输出。
立体监控
但真正的难点在于,业务方实际使用后,出现采集无法登录、日志配置多行或采集二进制大文件导致Filebeat oom和其他问题随之而来。我们在 Filebeat 和日志采集 的综合监控上投入了更多的时间,例如:
接入青州监控平台,包括磁盘io、网络流量传输、内存使用、cpu使用、pod事件告警等,保证基础监控的完善。
新增日志平台数据全链路延迟监控。
采集Filebeat自己的日志,通过自己的日志开始采集上报哪些日志文件,当采集结束时,避免每次ssh到各个节点查看日志配置和解决问题。
自研Filebeat导出器,连接prometheus,采集报告自己的metrics数据。
通过三维监控增强,极大的方便了我们的问题排查,降低了运维和人工成本,也保证了服务的稳定性。
五、Golang的性能优化与调优
从 Docker 到 Kubernetes,从 Istio 到 Knative,基于 Golang 的开源项目已经成为云原生生态的主力军。Golang 的简单性和效率不断吸引新项目将其用作开发语言。
我们青州微服务平台除了使用Golang编写Filebeat插件和控制器开发日志采集外,还有很多基于Golang的组件。其中,我们踩过很多坑,积累了一些Golang优化经验。
但是很多时候,我们看到了太多的GC原理、内存优化、性能优化,却往往在写完代码、完成一个项目后就无从下手。实践是检验真理的唯一标准。因此,通过自己检查和探索来提高姿势水平,找到关键问题是捷径。
对于性能优化,Golang 为我们提供了三个键:
这是一个简单的例子。
以sync.Pool为例,sync.Pool一般用于保存和复用临时对象,减少内存分配,降低GC压力。应用场景很多。比如号称比Golang官方Http快10倍的FastHttp,就大量使用了sync.Pool。Filebeat 使用 sync.Pool 将批处理日志数据聚合成 Batch 并分批发送。在 Nginx-Ingress-controller 渲染生成 nginx 配置的时候,也要使用 sync.Pool 来优化渲染效率。我们的日志控制器 Ripple 还使用 sync.Pool 来优化渲染 Filebeat 配置时的性能。
首先,使用 go benchmark 测试不使用 sync.Pool 时通过 go 模板渲染 Filebeat 配置的方法。
您可以看到结果中显示的方法每次执行的时间,以及分配的内存。
然后使用 go pprof 查看 go benchmark 生成的 profile 文件,观察整体性能数据。
其实go pprof有很多数据供我们观察,这里只展示内存分配信息。可以看出,在基准测试期间总共申请了超过 5 GB 的内存。
接下来,我们使用 go trace 查看压测过程中的 goroutine、堆内存、GC 等信息。
这里只截取600ms到700ms的时间段。从图中可以清楚地看到,100ms 内发生了 170 次 GC。
使用相同的方法和步骤,使用sync.Pool后测试结果。
分配的内存总量减少到了160MB,同一时间段内的GC次数也减少到了5次,差距非常明显。
总结与展望
在云原生时代,日志作为可观察性的一部分,是我们排查问题和解决问题的基础,也是后续大数据分析处理的开始。
在这个领域,虽然有很多开源项目,但仍然没有强大统一的log采集agent。或许这种绽放的景象会永远持续下去。因此,我们在自主研发的日志代理 Ripple 的设计中也提出了更多的抽象,保留了与其他日志采集代理接口的能力。未来,我们计划支持更多的日志采集代理,打造更丰富、更健壮的云原生日志采集系统。

