解决方案:网站自动采集文章中一段话的原理:使用post请求
优采云 发布时间: 2022-10-24 09:18解决方案:网站自动采集文章中一段话的原理:使用post请求
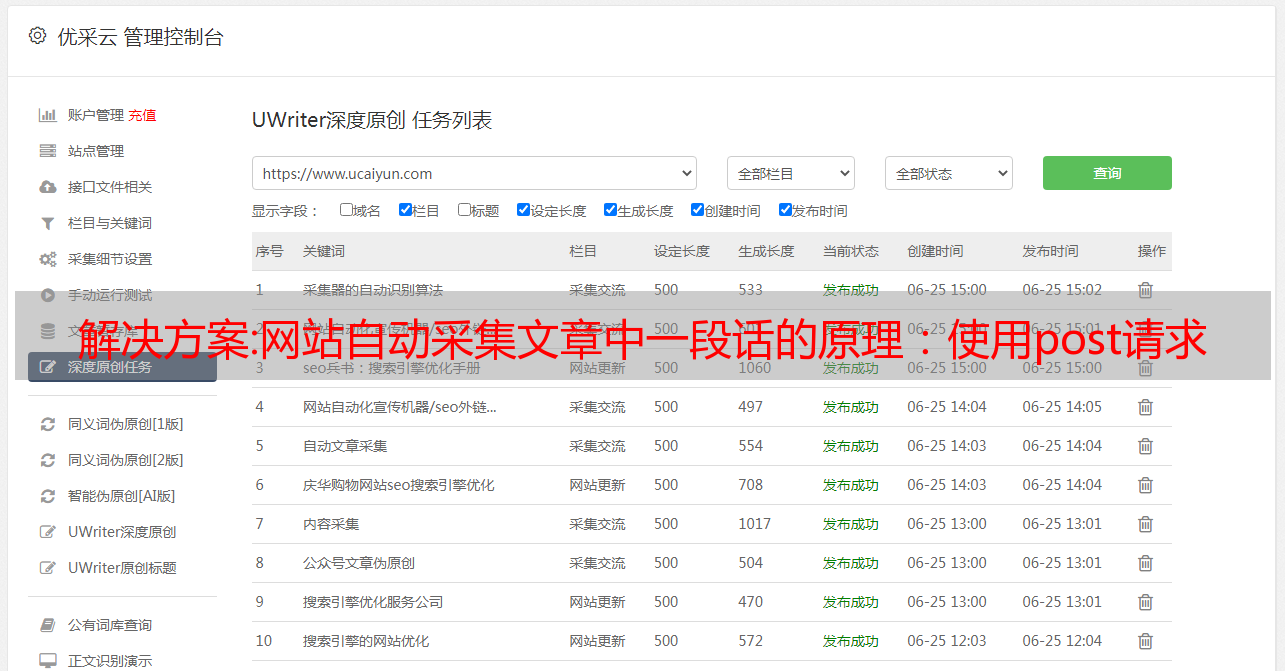
网站自动采集文章中一段话的原理:post请求将文章内容提交给google等搜索引擎服务器,google服务器自动按照某一格式将这一段话反编译成目标网页,即可拿到这一段话的采集页面。而当前很多电子书等都可以直接卖给当当网等网站,更多是反向代理而不是劫持,即你不用真的反编译服务器,服务器也无法提供你要的内容。
如果要采取这种方式,可以参考一下我之前写的帖子:python爬虫获取微信qq微博豆瓣书城电子书名网站爬虫(2)使用post请求我的代码如下:#下载图书和书城网页版mon.exceptionsimportexceptiondefparse_content(url):'''反编译txt格式文件的方法。
<p>'''pdf=text(urllib2.urlopen(url))withopen(pdf,'wb')asf:pdf=pdf.read()pdf.write(""+str(str(pdf.text()))+">"+str(str(pdf.text()))+">"+str(str(pdf.text()))+">

