专业知识:[百度SEO]巧妙利用百度站长工具获取准确数
优采云 发布时间: 2022-10-24 02:43专业知识:[百度SEO]巧妙利用百度站长工具获取准确数
在进行SEO时,我们经常需要了解网站的数据情况,包括索引、流量和关键词、外部链接数、蜘蛛爬取等,可以使用很多第三方工具查询,但需要付费购买第三方工具,否则数据无法及时更新。目前,百度网站站长平台将为所有网站站长增添活力。(这里以百度为搜索引擎为例,其他搜索引擎基本对应网站站长平台)
百度网站管理员平台已修改为百度搜索资源平台;网址为(之前的网址网站以前是301,现在百度网站管理员平台如下:
非常大方。上面有登录和注册。如果没有百度账号,可以自己注册。登录后会提示添加网站,然后按照向导完成添加网站操作;
接下来是重点:
1、如何知道网站的索引?
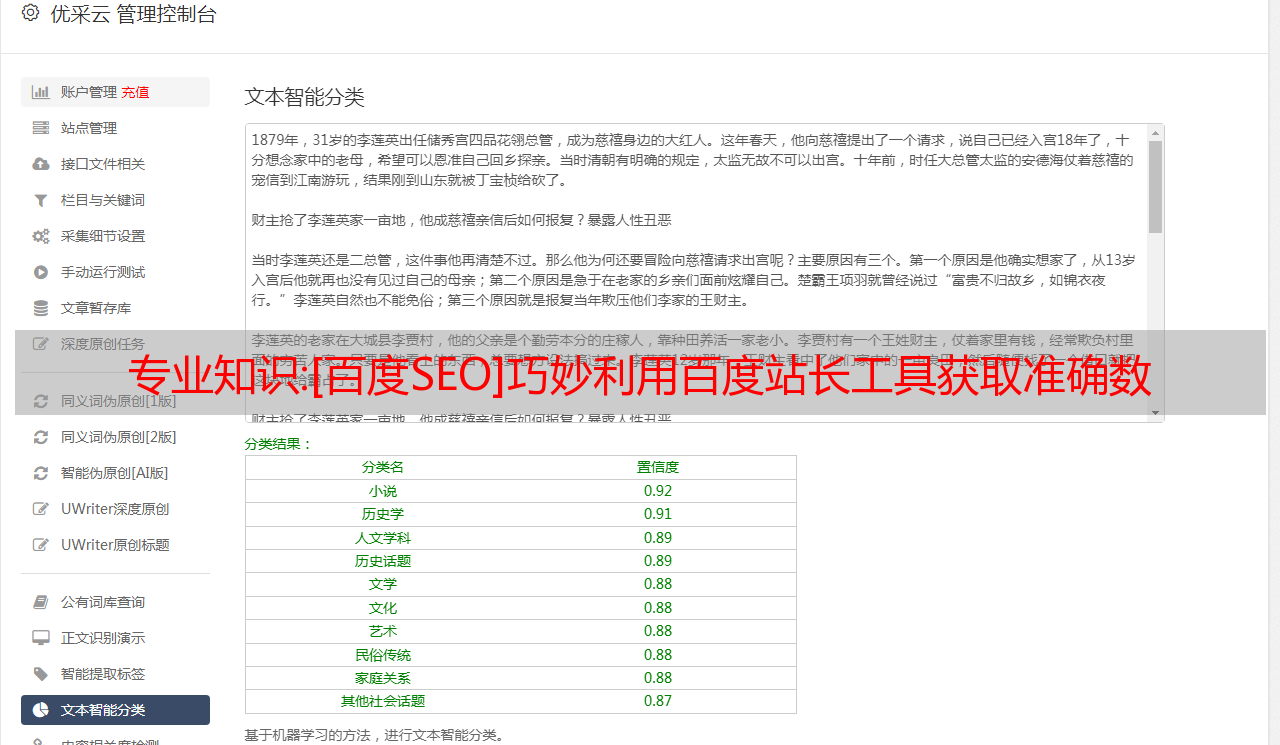
图中箭头所指位置用于查看指数情况,右侧上框为指数数量图,下框显示详细信息;
2. 网站 流量和 关键词
图中的箭头指向可以查看流量的位置和关键词,右上角的方框是金额和关键词的概览,下面的方框显示详情;
3.蜘蛛爬行
四、捕获错误
5. Robots.txt 更新
6. 提交无效链接
7.链接提交
提交链接有几种方式,可以根据网站情况选择一种方式
摘要:与其他网站管理员平台相比,百度网站管理员平台功能更加完善,网站管理员应用相对容易。如果您是 网站Administrator,则必须记住使用 网站Administrator 平台。熟练使用网站管理员平台的工具会让你的网站更加强大;
技术文章:爬虫学习日记第一篇(简易网页采集器)
以搜狗网站为例
我想爬取整个搜索页面
url很长,简化了url,发现显示内容不影响
开始写代码
import requests
if __name__=="__main__":
url="https://www.sogou.com/web"
#处理的url携带的参数:封装到字典中
# (原来的url为https://www.sogou.com/web?query=%E4%BD%A0%E5%A5%BD)这里经过了url编码,get传参
kw=input("Please enter words that you want to search:")
param={
'query':kw
}
#对指定的url发起的请求对应的url是携带参数的,并且在请求过程中处理了参数
response = requests.get(url=url,params=param)
<p>
page_text=response.text
fileName=kw+'.html'
with open(fileName,'w',encoding='utf-8') as f:
f.write(page_text)
print(fileName,'保存成功')
</p>
运行后输入“China”,得到“China.html”,浏览器打开
UA:User-Agent(请求载体的身份)
UA检测:门户网站的服务器会检测相应请求的运营商标识。如果检测到请求的载体标识为某个浏览器,则说明该请求为正常请求。但是,如果检测到请求的载体标识不是基于某个浏览器的,则说明该请求是异常请求(爬虫),服务器端很可能拒绝该请求
UA伪装:让爬虫对应的请求载体身份伪装成浏览器
浏览器简单抓包查看对应的User-Agent
更改代码
import requests
if __name__=="__main__":
#UA伪装:将对应的User-Agent封装到一个字典中
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.62'
<p>
}
url="https://www.sogou.com/web"
#处理的url携带的参数:封装到字典中
# (原来的url为https://www.sogou.com/web?query=%E4%BD%A0%E5%A5%BD)这里经过了url编码,get传参
kw=input("Please enter words that you want to search:")
param={
'query':kw
}
#对指定的url发起的请求对应的url是携带参数的,并且在请求过程中处理了参数
response = requests.get(url=url,params=param,headers=headers)
page_text=response.text
fileName=kw+'.html'
with open(fileName,'w',encoding='utf-8') as f:
f.write(page_text)
print(fileName,'保存成功')
</p>
这次搞定了
视频学习链接:

