通用解决方案:怎么通过CSS选择器采集网页数据
优采云 发布时间: 2022-10-23 19:30通用解决方案:怎么通过CSS选择器采集网页数据
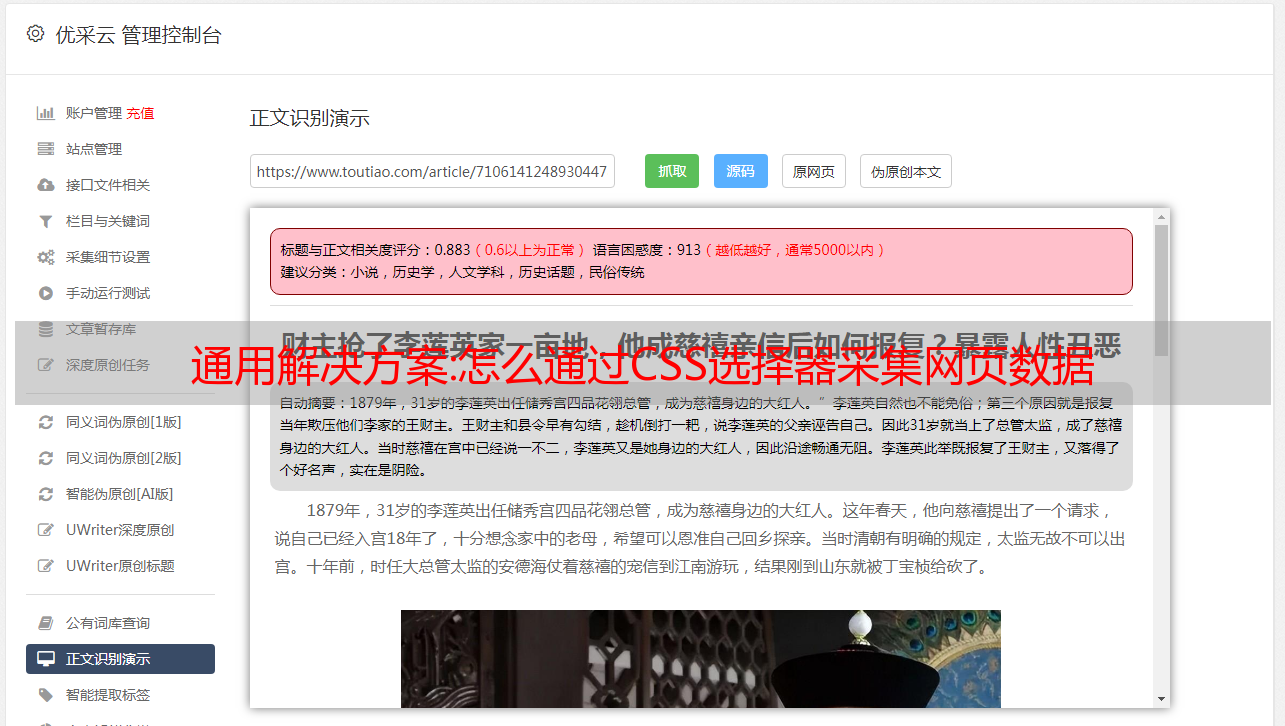
按 F12 打开开发人员工具,并查看文章列出 HTML 代码结构:
文章标题可以通过CSS selector.post 项标题获得;
文章地址可以通过CSS selector.post 项标题获得;
文章介绍可以通过CSS selector.post 项摘要获得;
作者可以通过CSS selector.post 项目作者;
用户头像可以通过CSS选择器img.头像获得;
喜欢的数量可以通过CSS获得 selector.post 项 a.post 元项;
注释的数量可以通过 CSS selector.post 项脚 a[类*=后元项]:第 n 个类型(3) 获得;
视图数可以通过 CSS selector.post 项英尺 a[类*=元项后]:类型 n(4) 跨度获得;
所以现在开始编写采集规则,采集规则保存,进入页面检查数据当前是否采集。
{
"title": "博客园首页文章列表",
"match": "https://www.cnblogs.com/*",
"demo": "https://www.cnblogs.com/#p2",
"delay": 2,
"rules": [
"root": "#post_list .post-item",
"multi": true,
"desc": "文章列表",
"fetches": [
"name": "文章标题",
<p>
"selector": ".post-item-title"
"name": "文章地址",
"selector": ".post-item-title",
"type": "attr",
"attr": "href"
"name": "文章介绍",
"selector": ".post-item-summary"
"name": "作者",
"selector": ".post-item-author"
"name": "头像",
"selector": "img.avatar",
"type": "attr",
"attr": "src"
"name": "点赞数",
"selector": ".post-item-foot a.post-meta-item"
"name": "评论数",
"selector": ".post-item-foot a[class*=post-meta-item]:nth-of-type(3)"
"name": "浏览数",
"selector": ".post-item-foot a[class*=post-meta-item]:nth-of-type(4)"
</p>
编写内容页采集规则
编写方法与上面相同,代码直接在此处发布。
{
"title": "博客园文章内容",
"match": "https://www.cnblogs.com/*/p/*.html",
"demo": "https://www.cnblogs.com/bianchengyouliao/p/15541078.html",
"delay": 2,
"rules": [
"multi": false,
"desc": "文章内容",
"fetches": [
"name": "文章标题",
"selector": "#cb_post_title_url"
"name": "正文内容",
"selector": "#cnblogs_post_body",
"type": "html"
添加计划任务(用于批量采集、翻页采集
)。
在定时任务中,通过动态URL采集地址获取待 采集文章页面的地址,插件在获取完成后会自动打开对应的页面。打开页面后,插件将立即采集规则匹配并采集数据。
https://www.cnblogs.com/
[a.post-item-title,href]:https://www.cnblogs.com/#p[2,10,1]
优化的解决方案:关键词爬虫,Python花瓣画板关键词采集存储数据库
想找图的朋友不要错过这个网站,对,没错,就是,各种图都有,而且推荐画板里的字还是很不错的,可惜了和谐了很多,想要采集花瓣画板的话,python爬虫当然没问题,花瓣的数据更有趣!
查询源码,有点类似数据接口
app.page["explores"] = [{"keyword_id":1541, "name":"创意灯", "urlname":"创艺灯笼", "cover":{"farm":"farm1", "bucket" :"hbimg", "key":"f77b1c1df184ce91ff529a4d0b5211aa883872c91345f-tdQn2g", "type":"image/jpeg", "width":468, "height":702, "frames":1, "file_id":15723730}, "
想了想,还是用普通访问更简单方便!
常规的
explores=re.findall(r'app.page\["explores"\] = \[(.+?)\];.+?app.page\["followers"\]',html,re.S)[0]
复制
注意这里的转义字符
源代码:
#花瓣推荐画报词采集
#20200314 by 微信:huguo00289
# -*- coding: UTF-8 -*-
from fake_useragent import UserAgent
import requests,re,time
from csql import Save
key_informations=[]
def search(key,keyurl):
print(f"正在查询: {key}")
ua = UserAgent()
headers = {"User-Agent": ua.random}
url=f"https://huaban.com/explore/{keyurl}/"
html=requests.get(url,headers=headers).content.decode("utf-8")
time.sleep(2)
if 'app.page["category"]' in html:
#print(html)
explores=re.findall(r'app.page\["explores"\] = \[(.+?)\];.+?app.page\["followers"\]',html,re.S)[0]
#print(explores)
keyfins=re.findall(r', "name":"(.+?)", "urlname":"(.+?)",',explores,re.S)
print(keyfins)
sa=Save(keyfins)
sa.sav()
for keyfin in keyfins:
if keyfin not in key_informations:
key_informations.append(keyfin)
search(keyfin[0], keyfin[1])
print(len(key_informations))
else:
print(f"查询关键词{key}不是工业设计分类,放弃查询!")
pass
print(len(key_informations))
print(key_informations)
search('3D打印', '3dp')
复制
函数调用本身不断循环浏览网页以获取数据!
花瓣网板字采集
数据是下拉加载,ajax数据加载
同时还有一个规则,就是下一个下拉的max就是最后一个petal seq!
源代码:
#花瓣画报词采集
#20200320 by 微信:huguo00289
# -*- coding: UTF-8 -*-
from csql import Save
import requests,json,time
def get_board(id):
headers={
'Cookie': 'UM_distinctid=170c29e8d8f84f-0b44fc835bc8e3-43450521-1fa400-170c29e8d903de; CNZZDATA1256914954=1367860536-1583810242-null%7C1583837292; _uab_collina=158415646085953266966037; __auc=30586f3f170d7154a5593583b24; __gads=ID=28115786a916a7a1:T=1584156505:S=ALNI_MbtohAUwMbbd5Yoa5OBBaSO0tSJkw; _hmt=1; sid=s%3AkwSz9iaMxZf-XtcJX9rrY4ltNDbqkeYs.bc8fvfAq6DLGxsRQ6LF9%2FmHcjOGIhRSZC0RkuKyHd7w; referer=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Df1FbGruB8SzQQxEDyaJ_mefz-bVnJFZJaAcQYJGXTZq%26wd%3D%26eqid%3Dda22ff4e0005f208000000065e74adf2; uid=29417717; _f=iVBORw0KGgoAAAANSUhEUgAAADIAAAAUCAYAAADPym6aAAABJ0lEQVRYR%2B1VuxHCMAyVFqKjomEjVgkb0VDRMQgrmJMdBcUn2VbAXDiSJpb9%2FHl6%2BiCEEAAAAiL9AJP5sgHSQuMXAOIB6NxXO354DOlhxodMhB8vicQxjgxrN4l1IrMRMRzmVkSeQ4pMIUdRp4RNaU4LsRzPNt9rKekmooWWDJVvjqVTuxKJeTWqJL1vkV2CZzJdifRWZ5EitfJrxbI2r6nEj8rxs5w08pAwLkXUgrGg%2FDoqdTN0IzK5ylAkXG6pgx%2F3sfPntuZqxsh9JUkk%2Fry7FtWbdXZvaNFFkgiPLRJyXe5txZfIbEQ4nMjLNe9K7FS9hJqrUeTnibQm%2BeoV0R5olZZctZqKGr5bsnuISPXy8muRssrv6X6AnNRbVau5LX8A%2BDed%2FQkRsJAorSTxBAAAAABJRU5ErkJggg%3D%3D%2CWin32.1920.1080.24; Hm_lvt_d4a0e7c3cd16eb58a65472f40e7ee543=1584330161,1584348316,1584516528,1584705015; __asc=c7dc256a170f7c78b1b2b6abc60; CNZZDATA1256903590=1599552095-1584151635-https%253A%252F%252Fwww.baidu.com%252F%7C1584704759; _cnzz_CV1256903590=is-logon%7Clogged-in%7C1584705067566%26urlname%7Cxpmvxxfddh%7C1584705067566; Hm_lpvt_d4a0e7c3cd16eb58a65472f40e7ee543=1584705067',
'Referer': 'https://huaban.com/discovery/industrial_design/boards/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'X-Request': 'JSON',
'X-Requested-With': 'XMLHttpRequest',
}
url="https://huaban.com/discovery/industrial_design/boards/?k804hb1m&max=%s&limit=20&wfl=1" % id
html=requests.get(url,headers=headers,timeout=8).content.decode('utf-8')
time.sleep(1)
if html:
req=json.loads(html)
print(req)
boards=req['boards']
print(len(boards))
for board in boards:
print(board['title'])
sa = Save(board['title'])
sa.sav2()
#print(board['seq'])
next_id=boards[-1]['seq']
get_board(next_id)
if __name__ == '__main__':
id="1584416341304281760"
while True:
get_board(id)
复制
使用 while 循环并循环自身
最后保存到数据库
源代码
import pymysql
class Save(object):
def __init__(self,key):
self.host="localhost"
self.user="root"
self.password="123456"
<p>
self.db="xiaoshuo"
self.port=3306
self.connect = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
db=self.db,
port=self.port,
)
self.cursor = self.connect.cursor() # 设置游标
self.key=key
def insert(self):
for keyword in self.key:
try:
sql="INSERT INTO huaban(keyword)VALUES(%s)"
val = (keyword[0])
self.cursor.execute(sql, val)
self.connect.commit()
print(f'>>> 插入 {keyword[0]} 数据成功!')
except Exception as e:
print(e)
print(f'>>> 插入 {keyword[0]} 数据失败!')
def insert2(self):
keyword=self.key
try:
sql="INSERT INTO huaban2(keyword)VALUES(%s)"
val = keyword
self.cursor.execute(sql, val)
self.connect.commit()
print(f'>>> 插入 {keyword} 数据成功!')
except Exception as e:
print(e)
print(f'>>> 插入 {keyword} 数据失败!')
def cs(self):
# 关闭数据库
self.cursor.close()
self.connect.close()
def sav(self):
self.insert()
self.cs()
def sav2(self):
self.insert2()
self.cs()
</p>
复制

