汇总:5分钟网销私房课:网站排名持续下降?收录锐减该怎么办?
优采云 发布时间: 2022-10-22 12:42汇总:5分钟网销私房课:网站排名持续下降?收录锐减该怎么办?
许多网站管理员在进行 网站 优化时都会遇到这种情况。原本拥有收录的文章突然失去了收录,甚至出现了大量的网站。在掉收录的情况下,这可能是因为网站的死重复太多,被降级或者进入沙盒期,所以收录的文章没有跟随它。现在,网站 排名继续下降?收录急跌怎么办?
1. 网站重复次数过多
内容对网站来说很重要,而网站百度收录减少的原因之一是内容重复过大。这通常发生在百度更新之后,重复是没有意义的。文章 将被删除,快照将消失。即用site命令查询时,收录的数字突然消失了。这种现象可以说是比较正常的。不要紧张。
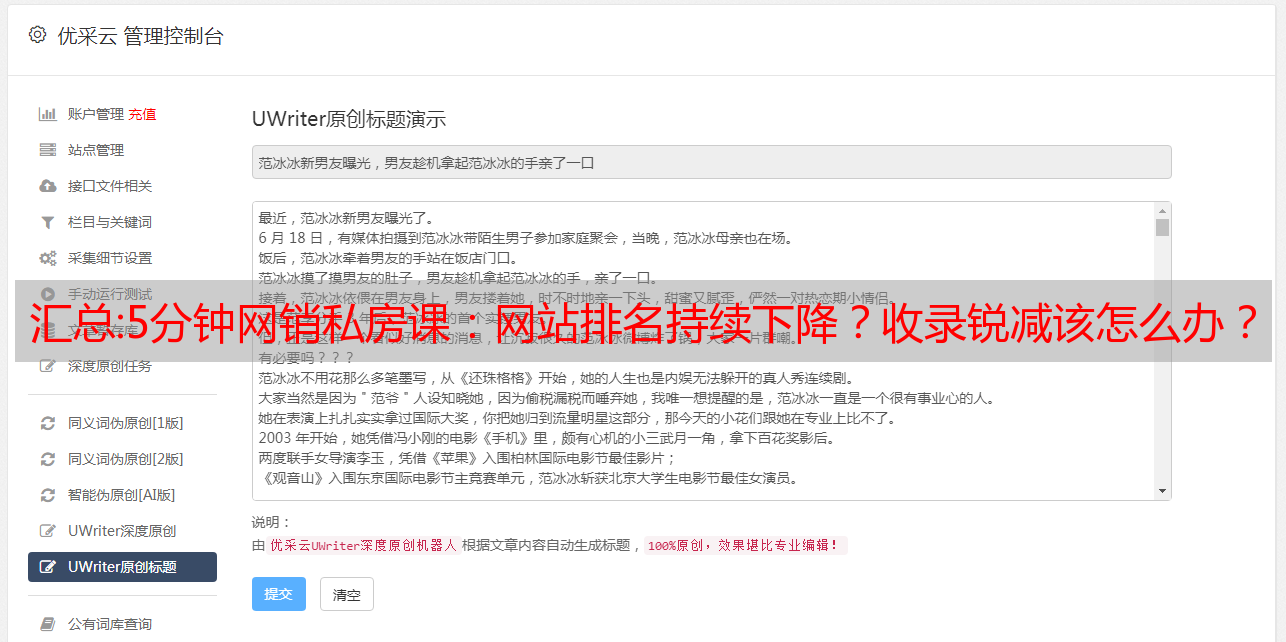
解决方法:对于重复较多导致网站降级的,需要使用原创文章或伪原创进行较大的改动,同时伪原创 时间到了,标题一定要改。不如改的比较新奇。用intitle+title名称先搜索百度,看看有没有文章同名。
2. 网站 被降级
网站 已降级。百度大更新后,网站收录会明显减少,或者有一天突然发现网站收录减少了。有很多,这个时候要小心,可能是网站的减少导致收录的减少。这时候可以使用百度站长工具中的百度索引量进行查询。如果指数体量指数很大,而站点数据收录很小,而网站刚刚降级,这一次是百度收录突然下降的第二个原因。
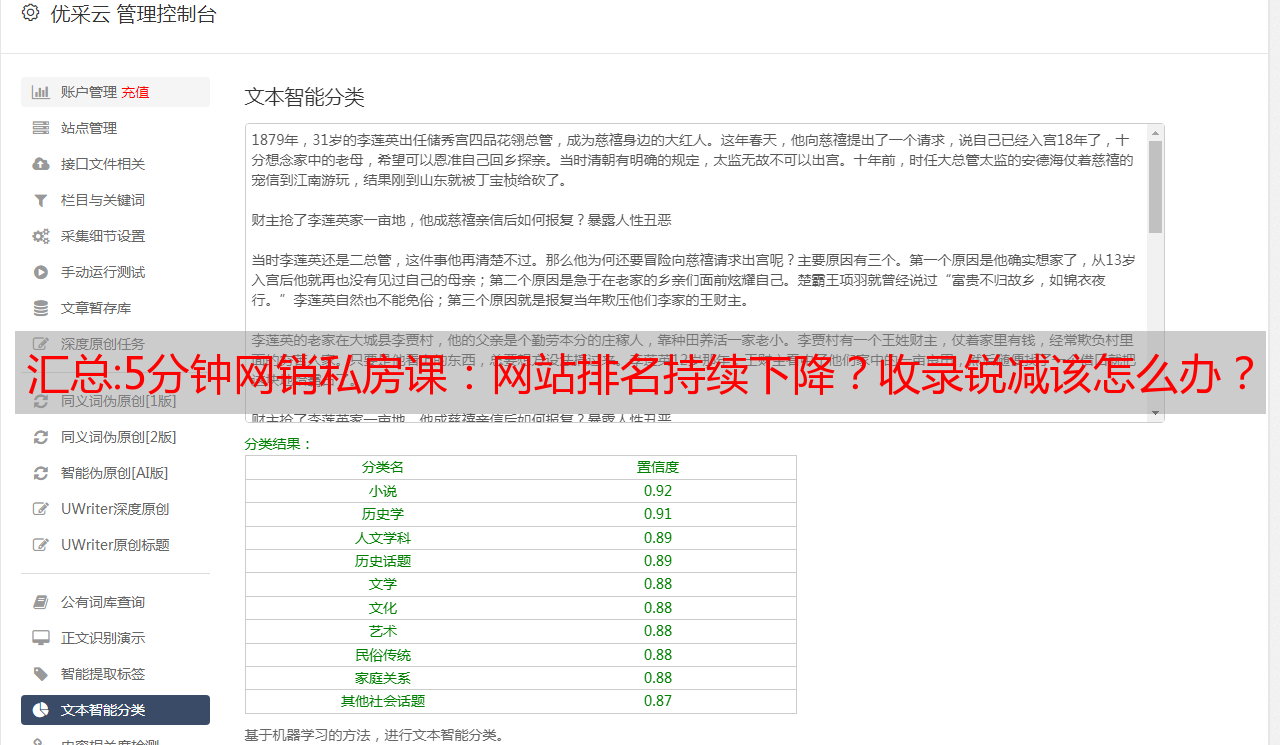
解决方法:网站降级后,收录降级的解决方法是及时找出网站降级的原因。这时候用百度站长工具一般可以看到索引量。没有太大变化。这时候可以查看外链,是否暂停,网站优化是否过度,友情链接是否有问题。一般查明网站降级原因后,收录会在一个月左右恢复正常。
3.网站进入沙盒周期
网站由于新站点或频繁更改标题和框架结构,网站将进入百度的沙盒期,一般为1个月到3个月不等。此时网站的收录会减少,快照不会更新。进入百度站长工具查询索引量时,索引量数据会增加。该站点将保持不变或减少。
解决方法:网站如果网站收录因进入沙盒期而减少,可以继续每天更新原创文章,去各大B2B平台,在分类信息平台上发布一些外部链接。
测评:采集某站热搜排行榜(阅读量,评论量和点赞量)
大概的概念:
任务一采集一个站的综合人气
任务2采集某站排行榜下的所有站
任务 3 采集 排行榜下的*敏*感*词*
没有加密,无非是编码的问题
任务一:
查了网页,发现api_ur可以直接从网络获取,所以可以直接从采集api获取数据,里面只收录播放量和评论量。没有点赞,只能通过输入视频获得点赞,所以这里需要找到另一个视频页面的url,api中已经收录参数,直接取即可
任务 2 和任务 3 做同样的事情:
首先查看网络中是否有api,发现没有api,只有采集网页。那么排行榜中的页面只收录浏览量、评论量,没有点赞。所以还是需要进入视频页面来获取点赞数,视频页面的url也可以从排名页面获取。
这次要分享的内容是我帮助别人的采集是某站的热搜排名。之前没采集去过某站,以为某站有防爬功能,也就是采集的弹幕,弹幕无非就是一些地下评论。经检查,似乎没有加密。没有加密,这很简单。别胡说八道了!看看这次的内容到采集!
具体过程我不能详细告诉你,也不能发出去。你可以去知乎查看地址:
具体代码:
#-*- coding:utf-8 -*-
import requests
import json
# 导入urllib与lxml库
from bs4 import BeautifulSoup
from lxml import etree
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
false = False
null = None
# 画图
def drawHistogram(x0, y1, y2, label1, label2, title):
matplotlib.rc("font", family='MicroSoft YaHei')
list1 = y1 # 柱状图第一组数据
list2 = y2 # 柱状图第二组数据
length = len(list1)
x = np.arange(length) # 横坐标范围
listDate = [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19]
plt.figure()
total_width, n = 1, 2 # 柱状图总宽度,有几组数据
width = total_width / n # 单个柱状图的宽度
x1 = x - width / 2 # 第一组数据柱状图横坐标起始位置
x2 = x1 + width # 第二组数据柱状图横坐标起始位置
plt.title(title) # 柱状图标题
# plt.xlabel("星期") # 横坐标label 此处可以不添加
plt.ylabel("数量") # 纵坐标label
plt.bar(x1, list1, width=width, label=label1)
plt.bar(x2, list2, width=width, label=label2)
plt.xticks(x, listDate, rotation=30) # 用星期几替换横坐标x的值
plt.legend() # 给出图例
plt.show()
# 排行榜 总榜 *敏*感*词*
def get_data(url, name):
headers = {
'cookie': "buvid3=51EECB8F-B2B4-F648-B16B-3485D6761C0437292infoc; b_nut=1663560437; i-wanna-go-back=-1; _uuid=42CBCB23-A539-DE8E-61B3-106A47517E4CC36605infoc; buvid4=1D9BE17F-5D9E-9B18-FD37-0F39ECBB843038064-022091912-JDMlVHKZXid/ggr/2NfjCA==; fingerprint=22087719bd29558ec54024d294426d83; buvid_fp_plain=undefined; nostalgia_conf=-1; rpdid=|(J|)l)R)R|k0J'uYYJlY|RlJ; DedeUserID=1639478777; DedeUserID__ckMd5=d8f72f04917d4ed9; buvid_fp=cd9174fe898e94313f12161d55f5c6d4; b_ut=5; SESSDATA=99311495,1679456980,62d1c*91; bili_jct=cda1af7ea2aebcb2d84117106aeb7b9c; b_lsid=B7F1AFEA_183724A44BE; CURRENT_FNVAL=4048; sid=75325who; bp_video_offset_1639478777=709429817518325800; innersign=0; PVID=12",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# 爬取网页的网址,此网址仅限于本实训使用
url = url
# 请求网页获取网页源码
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
title = tree.xpath('//*[@class="title"]/text()')
print(title)
# 播放量 评论量
bofangliang = tree.xpath('//*[@class="data-box"]/text()')
# print(bofangliang)
<p>
# 播放量 点赞量
x = []
y1 = []
y2 = []
for i in range(len(bofangliang)):
if(i==40):
break
if((i+2)%2==0):
y1.append(bofangliang[i].strip())
# 除去万
for i in range(len(y1)):
if ("万" not in y1[i]):
y1[i] = int(("".join(list(filter(str.isdigit, y1[i])))))
else:
y1[i] = int(str("".join(list(filter(str.isdigit, y1[i])))) + "000")
# 找出点赞的url
# 全站排行榜 和*敏*感*词* 排行榜点赞的url
url = tree.xpath('//*[@class="img"]/a/@href')
for i in range(len(url)):
if(i==20):
break
praise_url = 'https://www.bilibili.com/video/' + str(url[i].split('/')[-1])
y2.append(get_praise_1(praise_url, '//span[@class="info-text"]/text()'))
# 画图
print(y1)
print(y2)
drawHistogram(x, y1, y2, '播放量', '点赞量', name)
def get_api_data():
# 综合热门前20
headers = {
'cookie': "buvid3=51EECB8F-B2B4-F648-B16B-3485D6761C0437292infoc; b_nut=1663560437; i-wanna-go-back=-1; _uuid=42CBCB23-A539-DE8E-61B3-106A47517E4CC36605infoc; buvid4=1D9BE17F-5D9E-9B18-FD37-0F39ECBB843038064-022091912-JDMlVHKZXid/ggr/2NfjCA==; fingerprint=22087719bd29558ec54024d294426d83; buvid_fp_plain=undefined; nostalgia_conf=-1; rpdid=|(J|)l)R)R|k0J'uYYJlY|RlJ; DedeUserID=1639478777; DedeUserID__ckMd5=d8f72f04917d4ed9; buvid_fp=cd9174fe898e94313f12161d55f5c6d4; b_ut=5; SESSDATA=99311495,1679456980,62d1c*91; bili_jct=cda1af7ea2aebcb2d84117106aeb7b9c; b_lsid=B7F1AFEA_183724A44BE; CURRENT_FNVAL=4048; sid=75325who; bp_video_offset_1639478777=709429817518325800; innersign=0; PVID=12",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
hot_url = "https://api.bilibili.com/x/web-interface/popular"
param = {
'ps': 20,
'pn': 1
}
res_0 = requests.get(url=hot_url, data=json.dumps(param), headers=headers)
# json解析
data = res_0.json()
# print(data)
# 构造数据
y1 = []
y2 = []
x = []
for i in range(len(data['data']['list'])):
x.append(data['data']['list'][i]['title'])
y1.append(data['data']['list'][i]['stat']['view'])
# 获取点赞量
url_praise = 'https://www.bilibili.com/video/' + str(data['data']['list'][i]['bvid']) + '/'
y2.append(get_praise_0(url_praise, '//span[@class="info-text"]/text()'))
print(x)
print("播放量"+str(y1))
print("点赞量" + str(y2))
# 获取点赞量
drawHistogram(x, y1, y2, '播放量', '点赞量', '综合热门')
# 综合热门的点赞量
def get_praise_0(url, data):
headers = {
'cookie': "buvid3=51EECB8F-B2B4-F648-B16B-3485D6761C0437292infoc; b_nut=1663560437; i-wanna-go-back=-1; _uuid=42CBCB23-A539-DE8E-61B3-106A47517E4CC36605infoc; buvid4=1D9BE17F-5D9E-9B18-FD37-0F39ECBB843038064-022091912-JDMlVHKZXid/ggr/2NfjCA==; fingerprint=22087719bd29558ec54024d294426d83; buvid_fp_plain=undefined; nostalgia_conf=-1; rpdid=|(J|)l)R)R|k0J'uYYJlY|RlJ; DedeUserID=1639478777; DedeUserID__ckMd5=d8f72f04917d4ed9; buvid_fp=cd9174fe898e94313f12161d55f5c6d4; b_ut=5; SESSDATA=99311495,1679456980,62d1c*91; bili_jct=cda1af7ea2aebcb2d84117106aeb7b9c; b_lsid=B7F1AFEA_183724A44BE; CURRENT_FNVAL=4048; sid=75325who; bp_video_offset_1639478777=709429817518325800; innersign=0; PVID=12",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# print(response.text)
# response=urllib.request.urlopen(url=url)
# # time.sleep(5)
# # 将文本转化为HTML元素树
tree = etree.HTML(response.text)
praise = tree.xpath(data)
#print(praise)
if("万" not in praise[0]):
temp = int(("".join(list(filter(str.isdigit, praise[0])))))
else:
temp = int(str("".join(list(filter(str.isdigit, praise[0])))) + "000")
return temp
# 排名全站和排名*敏*感*词*的点赞量
def get_praise_1(url, data):
headers = {
'cookie': "buvid3=51EECB8F-B2B4-F648-B16B-3485D6761C0437292infoc; b_nut=1663560437; i-wanna-go-back=-1; _uuid=42CBCB23-A539-DE8E-61B3-106A47517E4CC36605infoc; buvid4=1D9BE17F-5D9E-9B18-FD37-0F39ECBB843038064-022091912-JDMlVHKZXid/ggr/2NfjCA==; fingerprint=22087719bd29558ec54024d294426d83; buvid_fp_plain=undefined; nostalgia_conf=-1; rpdid=|(J|)l)R)R|k0J'uYYJlY|RlJ; DedeUserID=1639478777; DedeUserID__ckMd5=d8f72f04917d4ed9; buvid_fp=cd9174fe898e94313f12161d55f5c6d4; b_ut=5; SESSDATA=99311495,1679456980,62d1c*91; bili_jct=cda1af7ea2aebcb2d84117106aeb7b9c; b_lsid=B7F1AFEA_183724A44BE; CURRENT_FNVAL=4048; sid=75325who; bp_video_offset_1639478777=709429817518325800; innersign=0; PVID=12",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.text)
praise = tree.xpath(data)
if(len(praise)==0):
praise = tree.xpath('//*[@class="video-toolbar-content_item video-toolbar-hover"]/text()')
# print(praise)
for i in range(len(praise)):
praise[i] = praise[i].strip()
temp = praise[2]
# print(temp)
else:
temp = praise[0]
# print(praise)
if("万" not in temp):
temp = int(("".join(list(filter(str.isdigit, temp)))))
else:
temp = int(str("".join(list(filter(str.isdigit, temp)))) + "000")
# print(temp)
return temp
# 综合热门
# get_api_data()
# # 全站排行榜前20
# quanzhan_url = 'https://www.bilibili.com/v/popular/rank/all'
# get_data(quanzhan_url, '排名全站')
# # *敏*感*词*排行榜前20
donghua_url = 'https://www.bilibili.com/v/popular/rank/douga'
get_data(donghua_url, '排名*敏*感*词*')
</p>
运行结果:

