事实:全网大小写抓取控制台、采集规则管理、请求池管理
优采云 发布时间: 2022-10-22 09:17事实:全网大小写抓取控制台、采集规则管理、请求池管理
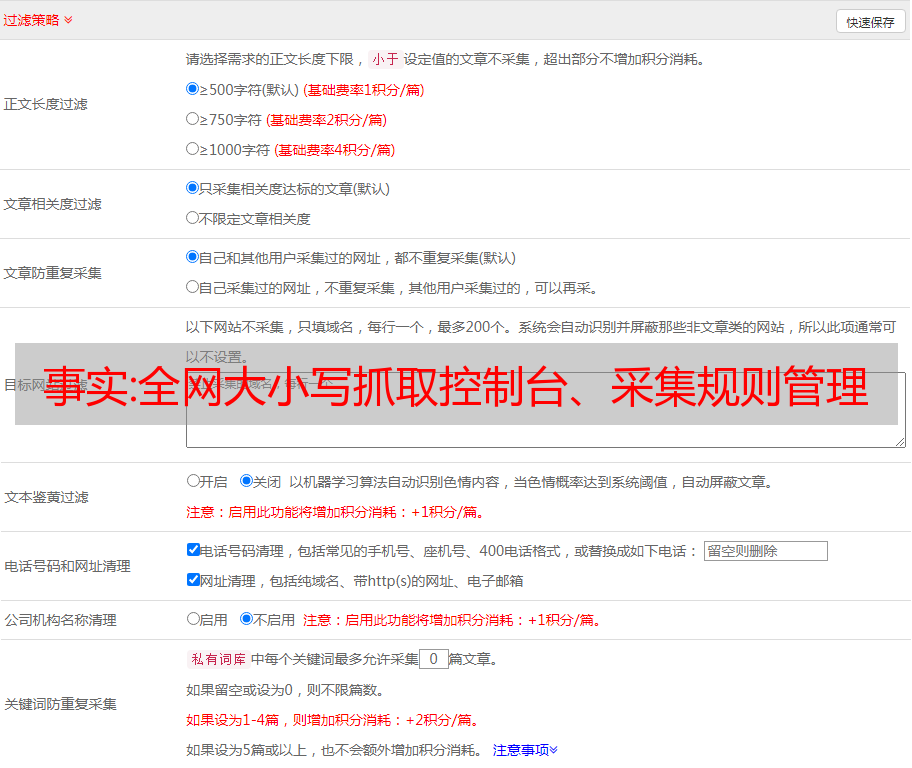
文章采集系统的选择由全网大小写抓取控制台、采集规则管理、请求池管理和爬虫控制控制台五部分组成。全网大小写抓取控制台是为了保证爬虫的最佳性能,以便在搜索引擎抓取到最好的内容。爬虫控制台是为了提高系统处理爬虫数据的能力。
搜索引擎下的很多产品并不都一样,再好的scrapy抓取系统也是要人手动规划和布置的,所以我觉得评价一个抓取系统好不好,首先要看他有没有人手动规划设置抓取规则,否则根本是一个垃圾玩意。
我们单位用的是curl+xpath+forwardingrequest+redis分布式抓取系统。url可以生成meta字段反馈到队列中,无需整库整表地修改抓取规则。系统分分钟处理完毕,一周内接入代理抓取。这个系统比较傻瓜。
我们已经用上了!下面是我们pep的传送门地址:
在excel中导入xml文件我看到有一个官方的比赛上,有人说:“抓了一个url,要快速回访每个点,
有用好吗?要是上个这个,
python的scrapy和selenium,
大致看了一下,感觉个人的理解是,有一些靠谱,有一些不靠谱。这两个我感觉是很多爬虫网站里用的最多的两个。它们的区别在于,selenium是一种支持强异步加载的技术,而pythonscrapy是一种支持全局设置同步加载的技术,并且保证两者对于不同的网站都可以高效率地处理网页内容。下面详细回答一下问题1:selenium适合抓动态网页,比如http站点;而pythonscrapy适合抓静态网页,比如爬淘宝,京东等购物网站。
下面详细说说pythonscrapy和selenium有何区别:首先pythonscrapy要实现的是基于浏览器的scrapy抓取,而selenium则可以利用浏览器的hook机制,但两者之间在hook机制的使用上是不同的。我们在处理固定网页时,会用到selenium,在处理自定义网页时,则会用到pythonscrapy,它们应用场景不同。
实现不同的场景,在web爬虫,反爬虫,反爬虫监控等有不同的处理方法,这个网上应该很好查找,而且相关内容也很多。与此同时,我们再来说说规则的问题,下面用一个特别的场景来说明,什么是规则:例如知乎第一页,限制用户id的访问。我们要抓取,发现知乎的第一页使用的是限制用户id的抓取(假设为auth,因为大多数网站对用户id都是处理成private的),这个时候,我们该怎么做呢?如果用pythonscrapy去实现,那么也不复杂,只要设置population为n就可以了。但要注意,如果我们只是实现一个不限制id抓取,那么我们就要给他加一个bool属性booli。

