教程:网站采集工具-超级采集与WingDNS动态域名下载评论软件详情对比
优采云 发布时间: 2022-10-21 14:18教程:网站采集工具-超级采集与WingDNS动态域名下载评论软件详情对比
【网站采集工具-超级采集】是一款智能采集软件,超级采集的最大特点是您无需定义任何采集规则,只需选择您感兴趣的关键词,超级采集会自动为您搜索并采集相关信息,然后通过WEB发布模块直接发布到您的网站。超级采集目前支持大多数主流cms,通用博客和论坛系统,包括织梦迪德,东夷,迪斯库兹,Phpwind,Phpcms,Php168,超级网站,帝国Ecms,非常cms,Hbcms,风新闻,科学新闻,文字press,Z博客,乔姆拉等。如果您现有的发布模块不支持您的网站,我们还可以为标准版和专业版用户免费定制发布模块,以支持您的网站版本。
1. 傻瓜式使用模式
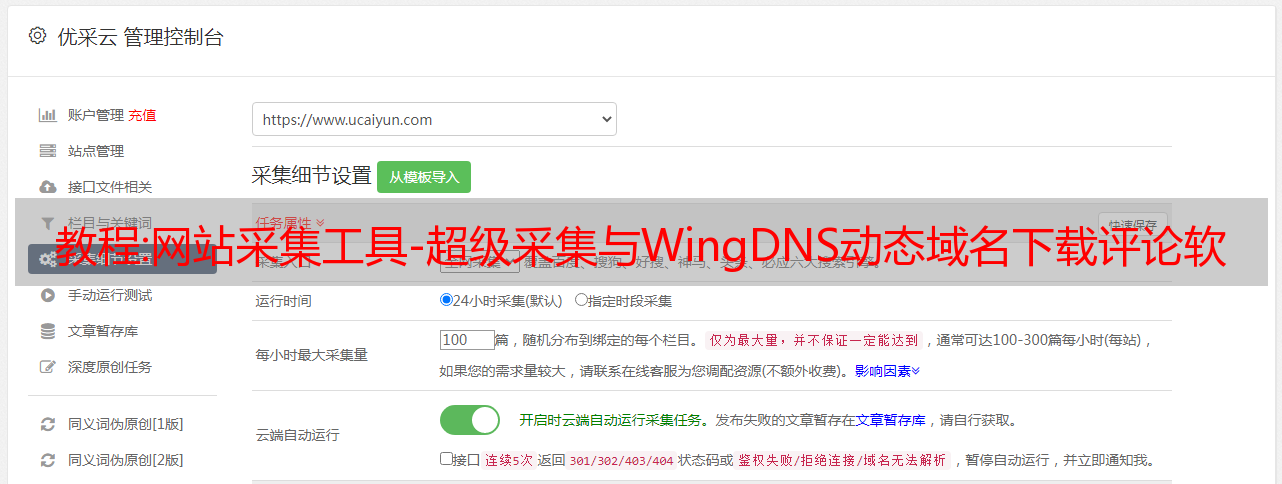
超级采集是
非常易于使用,不需要您有任何网站采集专业知识和经验,Super 采集的核心是一个智能搜索和采集引擎,可根据您感兴趣的内容自动采集相关信息并发布到您的网站。
2.超级强大的关键词挖掘工具,选择合适的关键词可以
为您的网站带来更高的流量和更大的广告价值,Super 采集提供的关键词挖掘工具为您提供每个关键词的每日搜索量,Google广告的每次点击价格以及关键词的广告人气信息,您可以根据此信息的排名选择最合适的关键词。
3. 内容、标题伪原创
超级采集提供最新的伪原创引擎,可以做同义词替换、段落回流、多篇文章混合等,可以选择通过伪原创处理来采集信息,增加搜索引擎收录 网站内容的数量。
汇总:主题式新闻搜索系统的方案—新闻页面采集模块方案.doc 39页
毕业项目(论文) 题目:专题新闻搜索系统设计—新闻页面采集 模块 学科名称:计算机学院 班级:软件115 学生编号:2 学生姓名:杜新佳 导师:程传鹏 2015年5月 设计专题新闻搜索系统—新闻页面采集模块设计专题新闻搜索系统—新闻页面采集模块院系名称:计算机学院班级:软件115学生编号:2学生姓名:杜新佳导师:程传鹏2015摘要 2009 年 5 月 随着 Internet 的普及和日益普及,以及人们对所需信息的渴望,基于主题的新闻搜索的系统方法变得越来越重要。一个主题就是一种个性,一种时尚。用户如何能够快速准确地找到他们需要的信息是极其重要的。同时,为用户提供最有效、最准确的信息也是每个开发者的追求和目标。随着岁月的流逝,这种情况变得越来越紧迫。当然,这也是一个非常难得的机会和机遇。谁抓住了这个机会,就有可能成为下一个互联网巨头,引领互联网时代。本文主要研究新闻是如何从这么多复杂的网络中采集到的采集。谁抓住了这个机会,就有可能成为下一个互联网巨头,引领互联网时代。本文主要研究新闻是如何从这么多复杂的网络中采集到的采集。谁抓住了这个机会,就有可能成为下一个互联网巨头,引领互联网时代。本文主要研究新闻是如何从这么多复杂的网络中采集到的采集。
通过广度遍历算法,URL采集被本地化。使用哈希表对下载的 URL 进行一一比较并删除重复项。通过转换将得到的相对路径链接转化为绝对路径链接。然后通过获取的绝对路径链接获取网页,然后截取标题的最后两个词判断是否属于新闻,然后将数据写入txt文本,图片存放在指定文件中。关键词: 关键词:新闻采集、URL捕获、绝对路径获取、标题截取、文字写作目录AbstractIAbstractII目录第三章引言11.1研究背景及实施意义11.2*敏*感*词*研究现状21.3本文主要内容工作 31. 1 研究背景及实施意义 随着互联网的快速发展,万维网已成为海量信息的载体。挑战,也是难得的机会。
如何向用户展示他们需要的信息也是搜索引擎的一个里程碑。传统搜索引擎(Search Engines),包括AltaVista、Yahoo!而谷歌等,在现实社会中,可能被视为辅助人们采集信息的工具,也可以被视为用户访问或进入万维网入口和行动指南的一种手段。事实上,传统的搜索引擎通常具有一定的局限性,因此信息采集技术应运而生。信息采集必须满足以下三个可靠性特征。也就是说,信息采集是指在采集信息产生的时候,信息必须是真实的物体或者环境产生的,必须保证信息来源的可靠,必须保证采集的信息确实能够反映信息的真实状态,这是信息采集的基础,即信息采集的基础. 诚信原则 信息采集诚信是指采集的信息内容必须完整,信息的采集必须按照一定的标准来做,采集的信息> 信息要反映全局,诚信原则是使用信息的基本原则。实时性原则,即采集的信息要与用户的请求相关。向用户显示采集的信息。它是一种基于搜索引擎的相关技术,但不完全等同于搜索引擎。它改进了传统搜索引擎的特性。它消除了它的缺陷。例如,搜索引擎搜索到的信息中有很多与用户需求无关的信息。总之,它克服了搜索引擎的缺点,继承了它的优点,这也是它发展如此迅速的主要原因。
1.2 *敏*感*词*研究现状基于磁盘的顺序存储基于哈希算法的存储基于磁盘的顺序存储基于磁盘的顺序存储。每次在任务 URL 开始下载之前有爬虫线程时,都会从磁盘上的文件中检索它。如果没有基于散列算法的存储,则通过散列算法实现。它的实现算法如下,它会给每个指定的或者说某个URL映射到某个物理地址。当需要检查URL是否重复时,只需对URL进行Hash映射即可。如果获取的地址已经存在,说明已经下载,放弃下载。否则,使用 URL。而其作为键值的Hash地址是基于MD5压缩图存储的,D5算法是一种加密算法,Hash算法存储。URL中的字符串是经过压缩的,压缩后的字符串可以直接是一个Hash地址。,MD5算法可以将任意字符串压缩成128位整数,映射到物理地址MD5,Hash映射冲突的几率很小。基于Hash算法,存储Hash存储的绝对路径的URL,然后一一访问。如果有可访问的网页,它将被添加到队列中。如果网页链接过期无法访问,则选择删除,然后继续阅读,直到到达最后一个链接位置。也就是说,直到最后一个Hash表被访问。实际上,有两种方法可以获取 HTML 的源代码。
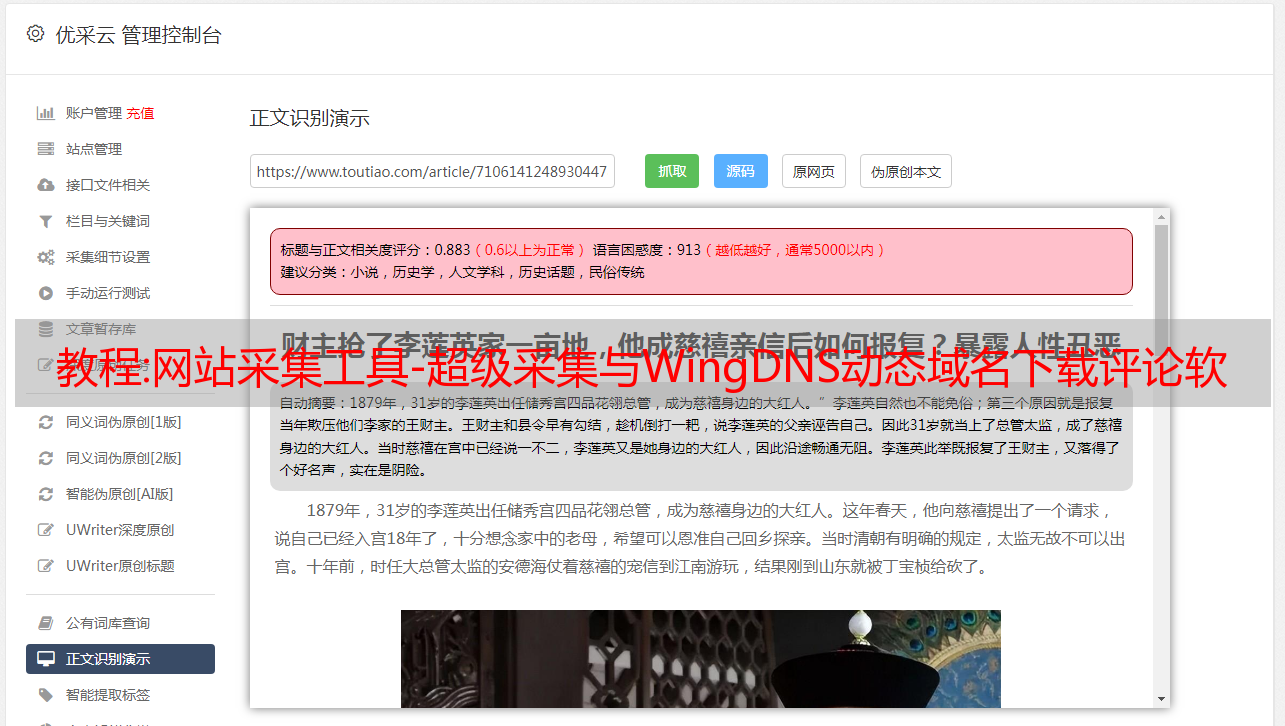
另一种方法是通过绝对路径的URL获取页面,获取网页中的源代码。显然,第二种方法简单易操作,因此系统采用第二种方法。新闻的判断是根据得到的源码,截取标题,也就是所谓的标题,加载到数组中。与已经写入数组的数据相比,如果新闻、信息等中存在汉字,则提取字符并下载其中收录的模式。否则选择放弃。继续这样做,直到到达最后一个。当然,这个操作也和其他操作有关,比如百科的判断。1.4 本文的组织结构本文分为5章。主要组织架构如下:分别介绍了基于话题的新闻搜索技术的历史和发展趋势,以及研究的意义。通过描述系统的主要工作方法,阐述了本文的主要内容。介绍了新闻主题采集涉及的一些相关关键技术。引入新闻主题采集和相关算法进行分类。系统测试。闭幕致辞。第二章新闻采集是一个基于关键技术主题的新闻搜索系统,即通过用户需要的新闻主题,从互联网上下载用户需要的新闻。当然这个系统只是那个更大系统的一个子集,所以我们只实现了 news采集 模块。本文重点关注新闻采集,并讨论了如何将网络上的URL抓取到本地,如何获取网页的绝对路径,如何判断网页的内容,是否为新闻,如何解读新闻。写入本地文档。
2.1 相关技术 2.1.1 搜索引擎 所谓搜索引擎,是指利用特定的计算机相关程序,按照一定的策略和方法采集或采集互联网上的信息,然后进行相关操作,如as 信息的组织或处理。然后,通过检索方法,为用户提供服务。检索与相关用户相关的某种信息,并展示给使用系统的用户,例如检索新闻。搜索引擎通常包括以下八种方法,即目录索引、全文索引、免费链接列表、垂直搜索引擎、引擎元搜索引擎、引擎门户搜索引擎、集合搜索引擎等,不再列出逐个。2.1.2 网络爬虫网络爬虫(也称为网络机器人,网络蜘蛛,在 FOAF 社区中,更常被称为网页追逐者),它们根据特定规则自动爬取万维网上信息的程序或脚本。它的主要功能是描述或定义爬取目标,分析然后过滤网页上的信息或数据,是一种爬取URL的策略。无所谓,我们也可以认为它是一个特殊的搜索引擎。它可以通过用户的需求直接抓取用户需要的东西。2.1.3 多线程编程是指可以同时与多个线程同时执行的程序或软件。我们可以考虑将一个程序分成许多小块,然后同时执行它们。收录在 using System.Threading 命名空间中。根据特定规则自动抓取万维网上信息的程序或脚本。它的主要功能是描述或定义爬取目标,分析然后过滤网页上的信息或数据,是一种爬取URL的策略。无所谓,我们也可以认为它是一个特殊的搜索引擎。它可以通过用户的需求直接抓取用户需要的东西。2.1.3 多线程编程是指可以同时与多个线程同时执行的程序或软件。我们可以考虑将一个程序分成许多小块,然后同时执行它们。收录在 using System.Threading 命名空间中。根据特定规则自动抓取万维网上信息的程序或脚本。它的主要功能是描述或定义爬取目标,分析然后过滤网页上的信息或数据,是一种爬取URL的策略。无所谓,我们也可以认为它是一个特殊的搜索引擎。它可以通过用户的需求直接抓取用户需要的东西。2.1.3 多线程编程是指可以同时与多个线程同时执行的程序或软件。我们可以考虑将一个程序分成许多小块,然后同时执行它们。收录在 using System.Threading 命名空间中。它的主要功能是描述或定义爬取目标,分析然后过滤网页上的信息或数据,是一种爬取URL的策略。无所谓,我们也可以认为它是一个特殊的搜索引擎。它可以通过用户的需求直接抓取用户需要的东西。2.1.3 多线程编程是指可以同时与多个线程同时执行的程序或软件。我们可以考虑将一个程序分成许多小块,然后同时执行它们。收录在 using System.Threading 命名空间中。它的主要功能是描述或定义爬取目标,分析然后过滤网页上的信息或数据,是一种爬取URL的策略。无所谓,我们也可以认为它是一个特殊的搜索引擎。它可以通过用户的需求直接抓取用户需要的东西。2.1.3 多线程编程是指可以同时与多个线程同时执行的程序或软件。我们可以考虑将一个程序分成许多小块,然后同时执行它们。收录在 using System.Threading 命名空间中。3 多线程编程是指可以同时与多个线程同时执行的程序或软件。我们可以考虑将一个程序分成许多小块,然后同时执行它们。收录在 using System.Threading 命名空间中。3 多线程编程是指可以同时与多个线程同时执行的程序或软件。我们可以考虑将一个程序分成许多小块,然后同时执行它们。收录在 using System.Threading 命名空间中。
主要收录六个步骤:线程启动、线程终止、线程挂起、线程优先级、线程挂起和线程恢复。多线程的好处是可以同时使用多个CPU核,也就是说可以进行并发控制,就像一个一个吃一样,一起吃的速度肯定会大大提高。因此,它的出现使计算机运行程序更加高效,节省了大量时间。当然,这项技术对于多核 CPU 的程序执行速度非常快。当然,对于单核 CPU 来说并没有那么快,但也提升了很多。可以说,多线程编程就是软件的开发。它一直是 1911 年的革命。2.1.4 主题 从表面上看,主题是一种风格,一种美丽的效果,以及视觉延伸和视觉效果。本质上,专题新闻搜索的主要目的是让用户随意获取各类新闻,让用户可以根据自己的喜好自由阅读或存储自己喜欢的新闻。当然这是整个系统大系统的灵魂,但是对于news采集模块来说,就不是重点了,这里稍微提一下。2.1.5 相对路径和绝对路径 绝对URL用于表示互联网上特定文件所需的全部内容,相对URL只适用于同名网页链接下的其他目录。因此,在存储时,需要使用绝对路径。只有绝对路径才能真正获取网页,而相对路径不能。专题新闻搜索的主要目的是让用户随意获取各类新闻,让用户可以根据自己的喜好自由阅读或存储自己喜欢的新闻。当然这是整个系统大系统的灵魂,但是对于news采集模块来说,就不是重点了,这里稍微提一下。2.1.5 相对路径和绝对路径 绝对URL用于表示互联网上特定文件所需的全部内容,相对URL只适用于同名网页链接下的其他目录。因此,在存储时,需要使用绝对路径。只有绝对路径才能真正获取网页,而相对路径不能。专题新闻搜索的主要目的是让用户随意获取各类新闻,让用户可以根据自己的喜好自由阅读或存储自己喜欢的新闻。当然这是整个系统大系统的灵魂,但是对于news采集模块来说,就不是重点了,这里稍微提一下。2.1.5 相对路径和绝对路径 绝对URL用于表示互联网上特定文件所需的全部内容,相对URL只适用于同名网页链接下的其他目录。因此,在存储时,需要使用绝对路径。只有绝对路径才能真正获取网页,而相对路径不能。让用户可以根据自己的喜好自由阅读或存储自己喜欢的新闻。当然这是整个系统大系统的灵魂,但是对于news采集模块来说,就不是重点了,这里稍微提一下。2.1.5 相对路径和绝对路径 绝对URL用于表示互联网上特定文件所需的全部内容,相对URL只适用于同名网页链接下的其他目录。因此,在存储时,需要使用绝对路径。只有绝对路径才能真正获取网页,而相对路径不能。让用户可以根据自己的喜好自由阅读或存储自己喜欢的新闻。当然这是整个系统大系统的灵魂,但是对于news采集模块来说,就不是重点了,这里稍微提一下。2.1.5 相对路径和绝对路径 绝对URL用于表示互联网上特定文件所需的全部内容,相对URL只适用于同名网页链接下的其他目录。因此,在存储时,需要使用绝对路径。只有绝对路径才能真正获取网页,而相对路径不能。5 相对路径和绝对路径 绝对URL用于表示互联网上某个特定文件所需要的全部内容,相对URL只适用于同名网页链接下的其他目录。因此,在存储时,需要使用绝对路径。只有绝对路径才能真正获取网页,而相对路径不能。5 相对路径和绝对路径 绝对URL用于表示互联网上某个特定文件所需要的全部内容,相对URL只适用于同名网页链接下的其他目录。因此,在存储时,需要使用绝对路径。只有绝对路径才能真正获取网页,而相对路径不能。
因为从本质上讲,它不能被视为真正的连接,也不能代表与刚刚链接相关联的网页。比如当你输入一个网站时,可能你点击里面的其他屏幕时,你在地址栏中观察链接时可能会发现链接变得很长,这是因为点击内容的地址使用相对链接。换句话说,这个链接没有被使用。所以相对URL只适用于连接同名网页下的其他目录,输入其他网站时不可用。因此,爬取的链接必须是绝对路径链接,因为只有这样,爬取的链接才有意义。2.2 URL 的爬取是在数千个网络上。如何在本地抓取这些链接有三种策略。他们是广度优先搜索,深度优先策略和最佳优先搜索。广度优先搜索策略是遍历URL的整个爬取过程,爬完这一层后,才会爬取下一层的搜索。该算法的实现和设计比较简单。当您想在当前时间覆盖尽可能多的页面时,通常使用广度优先搜索方法。他的基本思想是通过考虑原创初始词的URL,认为在一定链接距离内的网页很可能与主题相关或相关的概率非常高。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。然而,
深度优先搜索策略的方法是从起始页开始并选择一个 URL 作为入口点。分析这个页面中的URL,然后去选择一个然后输入。这样一个链接会被一个一个的取出来,直到处理完整个路由,然后再处理下一个路由。深度优先策略设计的方法比较简单。但是,由于门户网站 网站 提供的链接往往是最有价值的,因此 PageRank 也非常高。但是随着每一层的深入,页面的价值和PageRank会相应降低。这意味着重要的页面通常更靠近*敏*感*词*,而爬得太深的页面价值非常低。同时,随着抓取深度的加深,该策略将直接影响抓取命中率和抓取效率,所以抓取深度是决定这个策略的关键。所以对于其他两种策略。这种策略很少使用。最佳优先级搜索策略是根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度。然后选择一个或多个评估最有效的 URL 进行爬取。它只访问页面分析算法预测为“有用”的页面。但是他还是有一个问题,网络爬取路径上可能有很多相关的网页被忽略了,记忆后就忽略了。可以说,所谓的最优优先级策略实际上是一种局部最优搜索算法。所以,
该系统使用广度优先搜索策略,因为它允许大量 采集 URL。2.3 URL去重通常有三种方式,即基于磁盘的顺序存储、基于Hash算法的存储、基于MD5压缩映射的存储、基于磁盘的顺序存储、基于磁盘的顺序存储。每次在任务 URL 开始下载之前有爬虫线程时,都会从磁盘上的文件中检索它。如果没有基于散列算法的存储,则通过散列算法实现。它的实现算法如下,它会给每个指定的或者说某个URL映射到某个物理地址。当需要检查URL是否重复时,只需对URL进行Hash映射即可。如果获取的地址已经存在,表示已经下载,放弃下载。否则,使用 URL。而其作为键值的Hash地址是基于MD5压缩图存储的,D5算法是一种加密算法,Hash算法存储。URL中的字符串是经过压缩的,压缩后的字符串可以直接是一个Hash地址。,MD5算法可以将任意字符串压缩成128位整数,映射到物理地址MD5,Hash映射冲突的几率很小。基于Hash算法的存储 3.1 URL爬取与去重 如何将网络上的URL爬取到本地是这个程序或系统的重中之重,因为它是程序的开始,也是系统笔的画龙。只有在本地抓取,系统或程序才能继续运行。并且下载被放弃。否则,使用 URL。而其作为键值的Hash地址是基于MD5压缩图存储的,D5算法是一种加密算法,Hash算法存储。URL中的字符串是经过压缩的,压缩后的字符串可以直接是一个Hash地址。,MD5算法可以将任意字符串压缩成128位整数,映射到物理地址MD5,Hash映射冲突的几率很小。基于Hash算法的存储 3.1 URL爬取与去重 如何将网络上的URL爬取到本地是这个程序或系统的重中之重,因为它是程序的开始,也是系统笔的画龙。只有在本地抓取,系统或程序才能继续运行。并且下载被放弃。否则,使用 URL。而其作为键值的Hash地址是基于MD5压缩图存储的,D5算法是一种加密算法,Hash算法存储。URL中的字符串是经过压缩的,压缩后的字符串可以直接是一个Hash地址。,MD5算法可以将任意字符串压缩成128位整数,映射到物理地址MD5,Hash映射冲突的几率很小。基于Hash算法的存储 3.1 URL爬取与去重 如何将网络上的URL爬取到本地是这个程序或系统的重中之重,因为它是程序的开始,也是系统笔的画龙。只有在本地抓取,系统或程序才能继续运行。而其作为键值的Hash地址是基于MD5压缩图存储的,D5算法是一种加密算法,Hash算法存储。URL中的字符串是经过压缩的,压缩后的字符串可以直接是一个Hash地址。,MD5算法可以将任意字符串压缩成128位整数,映射到物理地址MD5,Hash映射冲突的几率很小。基于Hash算法的存储 3.1 URL爬取与去重 如何将网络上的URL爬取到本地是这个程序或系统的重中之重,因为它是程序的开始,也是系统笔的画龙。只有在本地抓取,系统或程序才能继续运行。而其作为键值的Hash地址是基于MD5压缩图存储的,D5算法是一种加密算法,Hash算法存储。URL中的字符串是经过压缩的,压缩后的字符串可以直接是一个Hash地址。,MD5算法可以将任意字符串压缩成128位整数,映射到物理地址MD5,Hash映射冲突的几率很小。基于Hash算法的存储 3.1 URL爬取与去重 如何将网络上的URL爬取到本地是这个程序或系统的重中之重,因为它是程序的开始,也是系统笔的画龙。只有在本地抓取,系统或程序才能继续运行。URL中的字符串是经过压缩的,压缩后的字符串可以直接是一个Hash地址。,MD5算法可以将任意字符串压缩成128位整数,映射到物理地址MD5,Hash映射冲突的几率很小。基于Hash算法的存储 3.1 URL爬取与去重 如何将网络上的URL爬取到本地是这个程序或系统的重中之重,因为它是程序的开始,也是系统笔的画龙。只有在本地抓取,系统或程序才能继续运行。URL中的字符串是经过压缩的,压缩后的字符串可以直接是一个Hash地址。,MD5算法可以将任意字符串压缩成128位整数,映射到物理地址MD5,Hash映射冲突的几率很小。基于Hash算法的存储 3.1 URL爬取与去重 如何将网络上的URL爬取到本地是这个程序或系统的重中之重,因为它是程序的开始,也是系统笔的画龙。只有在本地抓取,系统或程序才能继续运行。1 URL爬取与去重 如何将网络上的URL爬取到本地是本程序或系统的重中之重,因为它是程序的开始,也是系统笔的画龙。只有在本地抓取,系统或程序才能继续运行。1 URL爬取与去重 如何将网络上的URL爬取到本地是本程序或系统的重中之重,因为它是程序的开始,也是系统笔的画龙。只有在本地抓取,系统或程序才能继续运行。
如果爬取失败,即使程序还能进入,也没有任何意义。虽然他的地位很重要,但它的实现却出奇的简单。链接的抓取不需要太多的算法,也不需要太多的策略。所需要的只是一个简单的策略。系统使用广度优先算法将网络的超链接抓取到已经初始化的本地队列。这样,几段短代码就可以实现。当然,这只是一个开始,未来的任务还很艰巨。做这一切是不够的,因为互联网上有超过一千万个链接。最重要的是系统捕捉到的链接是随机的,所以每个链接可能是下一个,也可能是前一个。重复,如何删除那些重复的链接是另一个问题。当然,它的过程更复杂,比URL爬取工作复杂得多。对于它的实现,我们在开发工具中使用算法或系统类。是基于Hash算法的存储 public static string buildurl(string url, string param)?? {?? 字符串 url1 = url;? ? 如果 (url.IndexOf(param) > 0)? ? {?? if (url.IndexOf("&", url.IndexOf(param) + param.Length) > 0)?? {?? url1 = url.Substring(0, url.IndexOf(param) - 1) + url.Substring(url.IndexOf ("&", url.IndexOf(param) + param.Length) + 1);? ? }? ? 别的?? {?? url1 = url.Substring(0, url.IndexOf(param) - 1);? ? }? ? 返回 url1;? ? }? ? 别的?? {?? 返回 url1;? ? }? ? }? ? #结束区域?? #地区 ” 我们在开发工具中使用算法或系统类。是基于Hash算法的存储 public static string buildurl(string url, string param)?? {?? 字符串 url1 = url;? ? 如果 (url.IndexOf(param) > 0)? ? {?? if (url.IndexOf("&", url.IndexOf(param) + param.Length) > 0)?? {?? url1 = url.Substring(0, url.IndexOf(param) - 1) + url.Substring(url.IndexOf ("&", url.IndexOf(param) + param.Length) + 1);? ? }? ? 别的?? {?? url1 = url.Substring(0, url.IndexOf(param) - 1);? ? }? ? 返回 url1;? ? }? ? 别的?? {?? 返回 url1;? ? }? ? }? ? #结束区域?? #地区 ” 我们在开发工具中使用算法或系统类。是基于Hash算法的存储 public static string buildurl(string url, string param)?? {?? 字符串 url1 = url;? ? 如果 (url.IndexOf(param) > 0)? ? {?? if (url.IndexOf("&", url.IndexOf(param) + param.Length) > 0)?? {?? url1 = url.Substring(0, url.IndexOf(param) - 1) + url.Substring(url.IndexOf ("&", url.IndexOf(param) + param.Length) + 1);? ? }? ? 别的?? {?? url1 = url.Substring(0, url.IndexOf(param) - 1);? ? }? ? 返回 url1;? ? }? ? 别的?? {?? 返回 url1;? ? }? ? }? ? #结束区域?? #地区 ”
只有这样,链接才能有意义和有价值。因为只有绝对路径才能称为真正的 URL。通过它获取网页。因此,这一步也是至关重要和必要的。因为在网络的爬取中,很有可能爬取的是相对路径链接。相对路径的连接是网站的内部连接,被抓到后没有任何使用价值,所以必须转换成绝对路径的连接,为系统下一步提供方便。核心代码: public static void Normalize(string baseUri, ref string strUri){if (strUri.StartsWith("/")){strUri = baseUri + strUri.Substring(1);}if (strUri.EndsWith("?") )strUri = strUri.Substring(0, strUri.Length - 1);strUri = strUri.ToLower();Uri tempUri = new Uri(strUri);strUri = tempUri.ToString();
至此,系统可以说差不多完成了,但还是不能马虎,否则就如同竹篮打水一样。因为这一步是决定成败的一步,也可以说是关系到用户的满意度。因此,我们应该高度重视使用绝对路径URL获取相关网页。接口根据队列的信息,从队列中取出一条一条的绝对链路。通过链接获取网页源代码,截取标题最后两个汉字,与已经准备好的数据进行对比。如果是新闻或信息,我们可以断定这是我们想要的,去掉无用的脚本将数据写入文本,同时将图像存储在指定的文件夹中。这样就完成了系统。它的流程图,我们在本章开头已经给出,不再重复。核心代码:public class CrawlerThread{public event CrawlerStatusChangedEventHandler StatusChanged;private Thread m_thread;public string Name{get;set;}private CrawlerStatusType m_statusType;public CrawlerStatusType Status{get{return m_statusType;}set{if (m_statusType != value){m_statusType = value;this.Dirty = true;}}}public string MimeType{get;set;}private string m_url;public string Url{get{return m_url;}set{if (m_url != value){m_url = value;this .Dirty = true;}}}private Downloader Downloader{get;set;}private bool Dirty{get;set; 不会重复。核心代码:public class CrawlerThread{public event CrawlerStatusChangedEventHandler StatusChanged;private Thread m_thread;public string Name{get;set;}private CrawlerStatusType m_statusType;public CrawlerStatusType Status{get{return m_statusType;}set{if (m_statusType != value){m_statusType = value;this.Dirty = true;}}}public string MimeType{get;set;}private string m_url;public string Url{get{return m_url;}set{if (m_url != value){m_url = value;this .Dirty = true;}}}private Downloader Downloader{get;set;}private bool Dirty{get;set; 不会重复。核心代码:public class CrawlerThread{public event CrawlerStatusChangedEventHandler StatusChanged;private Thread m_thread;public string Name{get;set;}private CrawlerStatusType m_statusType;public CrawlerStatusType Status{get{return m_statusType;}set{if (m_statusType != value){m_statusType = value;this.Dirty = true;}}}public string MimeType{get;set;}private string m_url;public string Url{get{return m_url;}set{if (m_url != value){m_url = value;this .Dirty = true;}}}private Downloader Downloader{get;set;}private bool Dirty{get;set;

