解决方案:AI智能文章采集软件 v1.3
优采云 发布时间: 2022-10-21 14:15解决方案:AI智能文章采集软件 v1.3
AI智能文章采集软件对于从事自媒体或者软文的朋友来说一定是一款非常实用的文章采集加工神器,软件不能不仅帮助用户采集好文章,还可以进行伪原创处理,一键发布,处理文章原创度和率收录在80%以上,大大提高了营销效果。我建议大家试一试。相信你会喜欢的~
软件功能
一个好的文章可以让你的软文不仅收录、排名、转化都大放异彩,直接提升营销效果。
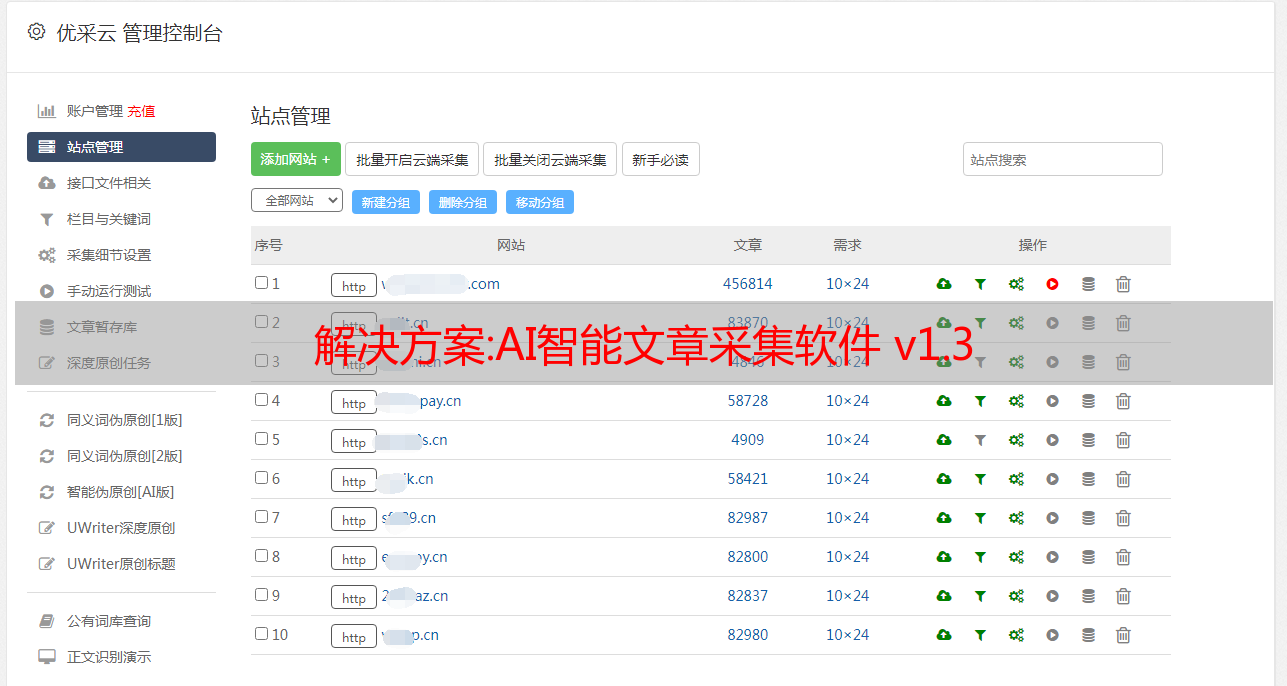
爆文采集您可以从今日头条、趣头条、一点资讯、东方头条等各大自媒体平台中选择文章。
操作简单方便,只需输入关键字即可启动采集文章,可随时暂停,也可打开查看文章详情。
其他玩法
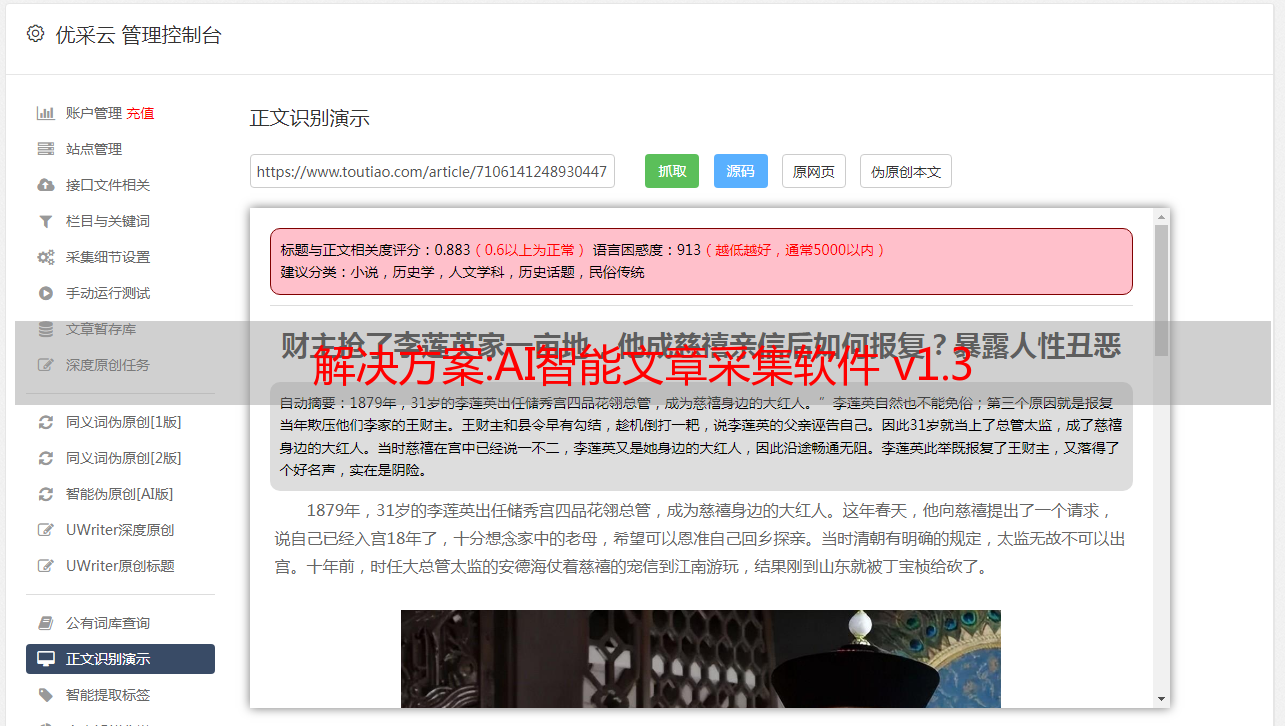
1.智能伪原创:利用人工智能中的自然语言处理技术,实现对文章伪原创的处理。核心功能是“智能伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词” >”、“句子打乱重组”等,处理后的文章原创度和收录率均在80%以上。更*敏*感*词*请下载软件试用。
2.传送门文章采集:一键搜索相关传送门网站新闻文章,网站有搜狐,腾讯,新浪。 com、网易、今日头条、新兰网、联合早报、光明网、站长网、新文化网等,用户可进入行业关键词>搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
3、百度新闻采集:一键搜索各行各业新闻文章,数据来源来自百度新闻搜索引擎,资源丰富,操作灵活,无需编写任何采集规则,但缺点是采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:使用文章时请注明文章出处,尊重原文版权。
你喜欢小编为你带来的AI智能文章采集软件吗?希望对你有帮助~更多软件下载可到华信软件站
解决方案:*敏*感*词*的websocket实时数据采集分析
*敏*感*词*网站websocket实时数据采集分析
**
前言:
**
本文仅供交流学习,请勿用于非法用途,后果自负!
*敏*感*词*是全球顶级赛事信息提供商网站和*敏*感*词*网站,涵盖足球、篮球等赛事。为什么要爬这个网站?因为它快速、准确、专业、事件信息丰富。国内很多赛事网站都与*敏*感*词*赛事信息直接或间接相关。
*敏*感*词*的游戏信息之所以能够快速更新,与其数据传输方式是分不开的。现在*敏*感*词*的游戏信息更新是通过websocket的方式实时传输的。下图是*敏*感*词*的数据展示
事件分数、事件索引等都是使用 websockets 传输的
红框的内容,左边是websocket的请求连接,右边是实时传输的一些游戏数据,包括实时指数、实时比分等。
相信能找到我文章文章的朋友应该对websocket的传输方式有一定的了解,这里就不赘述了(不能说不是很熟悉,哈哈)。好了,让我们开始*敏*感*词*的破解之路吧。
在第一段中,websocket 要求我们发送握手请求。上面的握手请求我也提到过,也就是wss:///zap/?uid=487869和这个格式差不多。这里有一个uid,下面的字符串Numbers应该是有用的,我们来全局搜索一下
但不幸的是,没有。这说明这个参数应该是js生成的。是时候开始逆转了
右边的红框代表这个url在发送前经历了什么。您可以点击最右侧的蓝色字体进入响应的代码块进行查看。
点进去之后,有没有似曾相识的感觉?没错,红框就是生成websocket请求地址的地方。不信的朋友可以设置断点看看,但是由于这段js代码是服务器动态生成并发送的,所以,重启断点后,会为你重新生成一个文件,但是并没有get到顺便说一句,你也可以在断点处停止。下一步是逐步反向推动。反推后,您将被定位在下图中。
红色字体是我们生成uid的地方,我们可以点击进入*敏*感*词*背景的函数查看
看,右边红框是uid的生成代码,你说不信?不行的话可以点左边的e功能进去看看,你会发现原来是这个,但是这个。. . 懂的人都明白,这是js中随机生成随机数的函数。这是随机生成随机数的功能,别问杜娘,为什么会这样,原因很简单,*敏*感*词*的uid是虚拟反爬的方法,其实只要是随机的数字匹配的位数,哈哈。
在第二段中,你只需要一个随机数组合来获取数据,显然,不需要。通过看前面的截图,我们知道接下来需要session_id:D27057904C7715589A932B1B1DCA70AC000003,token值(最难获取):m7AdXw==.yZly3XRicdw/1HkKKgFpxWRAkKOS0zKvQXzyzivNxsk=,其中:
session_id可以从这里请求,token需要经过两层加密获取。细心的朋友可能已经注意到了,没错,在上面的截图中,其实token已经出现了。
很明显,S(称为第二个token)是我们最终需要获取的数据,但是看第一个红框(称为第一个token)中的数据,它与S相似,但不一致,由此可见fe函数是一个加密函数,加密第一个token值生成第二个加密token值,这样点击
简单来说,就是将每个第一个token的值进行拆分,与e.charMap的数组中的数据进行交换,然后组合生成第二个token。有两种操作方式,第一种:直接复制加密后的代码,然后使用nodejs或者python框架execjs执行js生成。
pip3 安装 PyExecJS
二是直译,就是看懂代码,然后把对应的加密函数翻译成python代码,也可以执行。
令牌值的获取从我们找到第一个令牌的地方开始,并将其向后推到一个名为 C 的函数中。
在传入的init对象/token值之前,在这个函数中,原来的e是空的,但是在C执行之后才出现,说明在第一个tokenC中生成的理解C函数知道e=ae。join("") + String.fromCharCode(46) + se.join("") 生成的46是十进制ASCII中的句点,ae
瑟
结合起来,出现第一个令牌值。ae,se 是从哪里来的?
通过当前文件搜索可以看出,在C函数下,首先定义了两个数组ae和se,然后通过下面两个函数ef和gh将限定的o赋值到指定位置。
ef和gh函数是e对象的方法,e是传入的对象。继续往下看,可以看到e对象是后面的boot对象,同时
在这里找到了调用的地方,说明这里是正式生成ae,se(3号代码块中的绿框代码),但是这个_0x271cd1是什么?其实这是*敏*感*词*使用了一种叫做js代码混淆的技术,对比较容易阅读的js代码进行混淆,增加了反爬的难度,对js代码进行了混淆。
*敏*感*词*的代码混淆比较简单易懂,重点在几个地方
1号定义了一个收录数百个数据内容的数组,然后使用2号函数调整数组中元素的位置。调整后跳转到3号代码块进行for循环操作,在for循环中跳转到4号代码块中对应的函数执行。3、4执行过程中,需要频繁跳转到代码5、6、7进行数据提取。数据提取完成后,将提取的数据传递给boot.gh函数进行ae和se赋值。for 循环完成后,会生成第一个 A 标记值。看起来很复杂,其实只要了解代码运行过程,执行起来就麻烦了一些。因为上面的代码是服务器动态生成的,而且初始_0x4d8a数组的元素也是动态生成的,我们不能直接复制响应码生成参数。我这里使用的是使用re-regular通过请求动态提取对应的代码并获取响应,动态生成token值。
我们可以自己生成上述参数后,就可以使用框架携带响应请求参数发送握手请求并获取数据了。当然,我们还需要设置一些websocket基础,比如设置请求子协议:zap-protocol -v1,设置数据传输的数据格式:permessage-deflate(握手中使用permessage-deflate header来表示连接是否应该使用压缩)。设置这些后,通常可以获取数据。但是对于我们python来说,还有一个难点,就是框架的选择,也就是选择请求哪个websocket框架?其实对于一般的websocket连接,基本可以,但是对于*敏*感*词*:不是都可以用,当你使用websocket/websocket-client框架进行操作时,
折腾了一阵子,切换到asyncio+webscokets框架,成功获取数据
pip3 安装 websockets
分享到这里,就可以完成了。是的,可以完成,只要设置了断连重连,基本不会中断数据。
细心的朋友可能会发现一个细节,就是在最初的webscoket请求url列表中,还有一个和数据请求url很相似的url:wss:///zap/?uid=193506,而且每次都是,这对数据采集有影响吗?
观察url和数据交互,
当数据与这个数据一起返回时,获取数据的url连接会发送下图所示的数据
经过验证,发送的数据中还收录一个token值,而这个token值是对看似无关的ulr连接返回的token值进行二次加密得到的。那么这些是干什么用的呢?通过对比实验,只有在获取数据的ur链接运行时,获取数据的连接异常率才会很高。平均每五分钟它会自动断开连接并重新启动一次。两者都连接的情况下,基本不会出现五分钟重启的现象。这对设置异常断线自动重启的代码没有影响,认为是优化了。
总结:
*敏*感*词*实时数据获取的反爬流程总结如下: 1、url中的uid是指定位数的随机数的组合,发送数据中的pstk可以通过request获取,而最难的token值首先是通过首页的js代码获取参数后,配置连接参数,使用websockets框架获取数据。
最后
本文仅供交流学习,请勿用于非法用途,后果自负!
我只是一个菜鸟。如果有不对的地方请指出,我没有任何python学习教程可以分享,所以我不会留下任何*敏*感*词*。如果您对以上有任何疑问,可以留言,我看到会回来的。
最后感谢大家的收看。

