技巧:除了Python以外,还有哪些工具可以用来爬取数据?
优采云 发布时间: 2022-10-21 11:35技巧:除了Python以外,还有哪些工具可以用来爬取数据?
●我是来自【真诚的学术和生活关怀】组(即学院学术组1)的Glitter。我在广东985大学学习会计。首先,我想说的是,向学会投稿这样的爬虫教程的动机,不是为了表现出任何优越感,而是因为我深深认同学会的公益学术理念:让每一个普通的有技能的学生 所有人都有机会与同龄人分享他们所学的知识。
●看到学校社区里已经有很厉害的前辈分享了Python爬虫教程(),虽然很佩服前辈的能力,也很感谢前辈直接用推特分享这么长的教程,但是我还是觉得Python对于普通人来说是有门槛的。如果只是比较简单的数据爬取工作,可以在Python之外一键实现,依靠傻瓜式菜单操作的小工具,无需任何编程基础。
●本次分享其实来自以下日常在线对话。你会发现爬虫的起点其实很低。除了在学术研究中用于捕获数据之外,各行各业只与数据打交道的公司白领也可能会发现它很有用。不要把焦虑卖给自己~
前辈,用excel导入数据确实有点麻烦,有没有更快的方法?
爬虫可以用!一般指网络爬虫,即根据个人需求在万维网上爬取信息的算法。
听起来很方便,但是爬虫是怎么工作的呢?
当我们决定去某个网页时,首先爬虫可以模拟浏览器向服务器发送请求;其次,服务器响应后,爬虫也可以代替浏览器来帮助我们解析数据;然后,爬虫就可以按照我们设置的规则批量提取相关数据,无需我们手动提取;最后,爬虫可以在本地批量存储数据。
因此,爬虫的工作可以分为四个部分:获取数据、解析数据、提取数据和存储数据。下面主要介绍Excel,优采云采集器和优采云采集器的数据爬取功能。
爬虫工具介绍
1)Excel
其实Excel也有爬虫功能,大家可以学着用。我们用Excel来采集全国空气质量排名数据,地址如下:
以下是Excel2019操作示例:
输入采集对象
首先,点击【数据】选项卡,在【获取数据】选项组中,选择【来自其他来源】→【来自网站】
然后输入URL地址,系统会跳转到需要采集数据的页面。
采集 并导出
然后,选择页面中的表格,点击【加载】按钮,将数据导入到工作表中,如下图:
注意:使用Excel爬取数据主要是利用它来获取网页中的表格数据。非表格数据不建议使用,因为格式比较乱,一般不是我们需要的效果。
2) 优采云采集器
优采云采集器是一款桌面应用软件,支持Linux、Windows、Mac三大操作系统。可以直接从官网免费下载,地址如下:
优采云采集器将采集作业分为两种:智能模式和流程图模式。
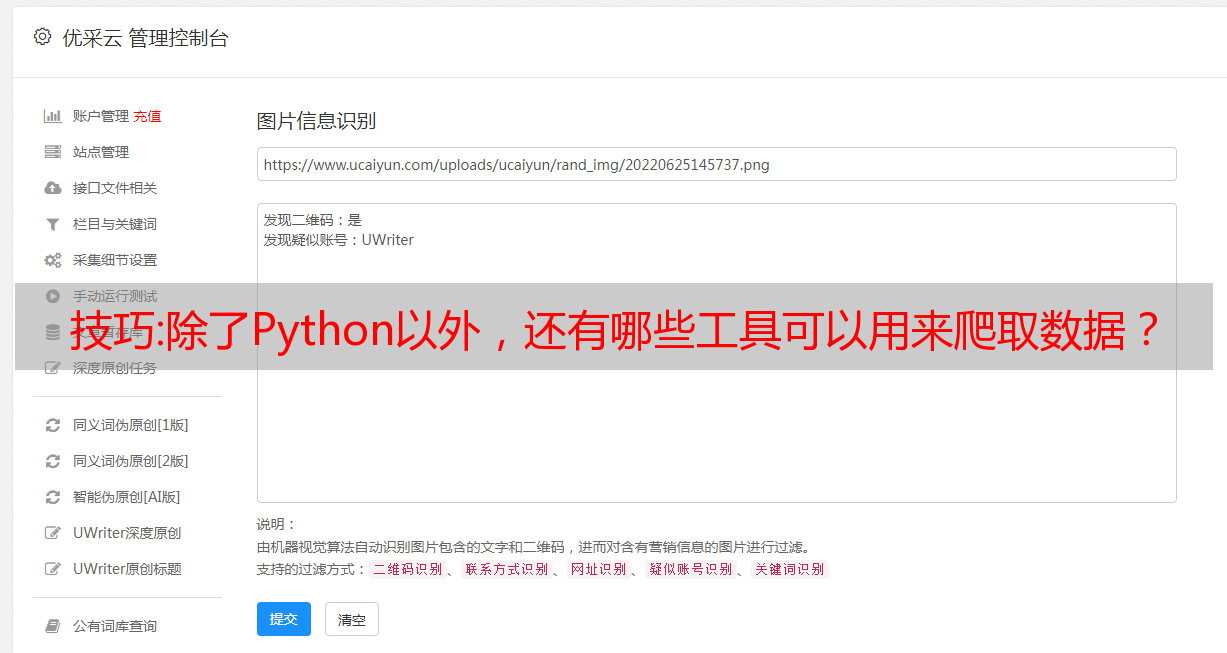
智能模式是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式更适合简单的网页。
流程图模式的本质是图形化编程。我们可以使用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页爬取数据的各种行为。
下载安装后打开优采云采集器可以看到它简洁的主界面,它的主智能采集模式对小白最友好,只要把网址放在我们想要的地方搜索信息 Enter 自动进入 Smart采集 模式。
以下是实习僧官网作为爬取对象的示例:
打开采集器,输入网址
点击智能采集
*第一次爬取数据建议使用智能采集。
可以看到优采云采集器会自动识别输入URL的页面类型,识别文字内容等元素,智能采集的功能帮我们放了重要信息(公司、地点、时间)等)被提取出来。
如果网页多页,一般优采云采集器会默认选择自动分页识别。我们也可以点击分页设置来设置分页按钮。
设置采集范围
例如,如果我们只想要前3页的数据,我们可以在设置采集范围内将结束页-自定义-值设置为3。
数据过滤
比如我们要采集这个网页位于重庆,与金融业务相关,可以点击【数据过滤】-【新建条件】-【选择字段名和条件】。因为公司位置的内容是城市,所以字段名选择城市,条件选择收录,数值框输入重庆,第一个条件成立。
但是我们还要第二个条件和金融实习相关,因为这两个条件是相关的,所以点击新建条件。(如果第二个条件和第一个条件的关系是OR,则点击新建组)。
此时由于之前金融实践的数据框为fl,所以第二个条件的字段名称为fl,条件选择为收录,值框填入金融实践。单击确定以保存过滤器。
采集 并导出
然后我们可以点击[开始采集]。
您可以选择定时启动或直接启动。(及时启动费,直接启动免费)
采集完成后,我们点击【导出数据】,可以选择Excel、CSV、TXT、HTML四种格式导出数据,可以到导出的文件中查看爬取的数据~
3)优采云采集器
优采云采集器是一个互联网数据采集器,可以根据不同的网站提供多种网页采集策略和配套资源,访问web文档。操作简单,图形化操作完全可视化,很容易从任何网页准确采集我们需要的数据生成自定义的常规数据格式。
优采云采集器分为简单采集和自定义采集两种模式。Simple采集内置主流数据源,无需配置;自定义采集可自由配置,灵活适配所有业务场景。
下面是一个简单的采集操作过程的例子:
选择对象
首先点击[Simple采集],选择Simple采集中国东方财富网图标
进入东方财富网板块后,您可以选择特定的规则模板。这时候我们选择【东方财富网-分享栏-发帖内容采集】,如图:
设置采集范围
然后进入信息设置页面,根据个人需要设置翻页次数。比如这里我们选择3个页面:
采集 并导出
点击保存并启动数据采集,下图为本地采集效果示例,如图:
采集完成后点击【导出数据】,可以自由选择Excel、CSV、HTML等格式,导出数据如下:
编者的话
●非常感谢闪灵前辈的真诚分享。上面介绍的爬虫工具的功能远比上面列出的要强大,操作也非常简单快捷。归根结底,使用爬虫工具是为了方便我们提取数据,消除我们日常工作中提取数据过程中的简单重复性工作。学习技能最重要的是要有明确的目的和计划。如果你只是为了时尚而学习Python,你会有回报珍珠的意图。我们出来做公益学术,不是为了让观众越来越焦虑和内向,而是为了有效拉近知识技能与每个普通人的距离,消除信息不对称。
●学术强调“独立精神和自由思想”。当然,在当今知识经济时代,“扎实的技能”是必须要补充的。我们提倡的公益奖学金,无非是希望尽可能以自由的形式分享这种学术精神和技能。在更深层次上,我们认为公益学术分享并不要求分享者有好看的个人头衔,也不应该过分强调知识和技能带来的功利性成果,而只是展示知识和技能本身的魅力。 . 就够了,实际上只是让公众更接近这些知识和技能。至于观众是利用这些知识和技能赚钱还是继续深造,这些不应由我们定义或指导。也就是说,关注学术(及其衍生的知识和技能)而非学术带来的额外成果的公益学术分享,可能是纯粹的公益学术。
●对于想要上手Python的朋友,学社君曾推送Glitter前辈贡献的个人Python学习笔记。以下是专为前辈笔记制作的宣传推文(点击图片跳转):
现在不再需要通过填写问卷来采集笔记,可以直接在后台回复【Glitter_Python】获取完整笔记的提取链接。
●目前,学会有3个活跃的公益学术交流群:【真诚的学术与生活关怀】、【始终如一的学术与生活关怀】、【同线的学术与生活关怀】,每个团体都有风格和定位都是不同的。如需进*敏*感*词*流,可在后台回复【进群】,获取进群规则。
文案 | 高级闪光,高级Z
排版 | 燕音女士
评论 | 燕音师姐,Z学长
关于我们
金融计量经济学会是一个私人公众号,专注于经济金融相关知识的普及。我们追求学业与实践的结合,追求义利的统一,倡导金融业重视社会责任,帮助学生建立对商业和经济的理性认识。我们不是一个社会,也不是一个组织。与任何机构、单位或部门无关。我们不以利润为目标。本号只是一群志同道合、真诚相爱的朋友,自愿为学生建立公益性学术交流平台。学术资料的整理、排版、小助手等工作全部由我们的公益学术分享群志愿者朋友完成,
官方数据:Excel爬取数据
这里有两个简单的爬虫软件,Excel和优采云。这两款软件无需编写任何代码即可完成大部分网络数据爬取。让我简单介绍一下这两个软件。如何爬取数据,主要内容如下:
Excel 抓取数据
1. 大多数人应该都听说过。除了表格的日常处理,Excel还可以完成简单页面数据的爬取。下面是一个爬取PM2.5排行榜数据的例子,如下:
2、首先新建一个excel文件,点击菜单栏中的“数据”->“来自网络”,在弹出框中输入要爬取的页面的URL,点击“Go”,即可跳转到我们需要爬取的页面 取到的网页如下:
3、然后,直接点击“导入”,选择对应的工作表,然后导入我们需要爬取的数据,如下:
这里也可以设置数据更新的频率,可以多长时间刷新一次数据,如下:
优采云爬取数据
1.这是一款专门用于爬取数据的爬虫软件。它易于使用,易于学习和理解。只需点击按钮,选择爬取的数据,即可自动完成数据采集流程。,这个可以直接从官网下载,如下:
2.安装完成后,我们就可以采集的数据了。这里以采集智联上的招聘数据为例,进入主界面,选择“自定义采集”,输入如果需要采集的URL,可以跳转到对应页面,如下:
3、接下来我们直接点击页面元素,选择我们需要的元素采集,依次按照提示完成采集数据的准备,如下:
4、最后点击启动本地采集,采集的数据如下,就是我们需要的数据,这里会自动设置字段个数,分页显示:
我们也可以选择数据保存的格式,比如csv、excel、数据库等:
至此,我们已经介绍了这两款爬虫软件。一般来说,对于简单的、常规的、静态的数据,我们使用Excel来爬取,非常简单。对于稍微复杂一些的页面,我们可以使用优采云进行爬取,选择相关元素,直接采集就可以了,当然你也可以使用优采云等采集软件,基本功能类似优采云,如果你对编程很熟悉,也可以自己写代码来完成,有兴趣的可以搜索一下。希望以上分享的内容对您有所帮助。也欢迎您发表评论和留言。

