行业解决方案:互联网数据采集器---优采云
优采云 发布时间: 2022-10-20 13:19行业解决方案:互联网数据采集器---优采云
优采云Data采集系统基于完全自主研发的分布式云计算平台。它可以很容易地在很短的时间内从各种网站或网页中获取大量的标准化数据。数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率。
下载地址:
折叠编辑本段主要功能
简而言之,使用 优采云 可以轻松采集从任何网页中精确获取所需的数据,并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1、财务数据,如季报、年报、财务报告,包括每日最新净值自动采集;
2、各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、采集最新最全的招聘信息;
6、关注各大地产相关网站、采集新房、二手房的最新行情;
7、采集主要汽车网站具体新车和二手车信息;
8、发现和采集潜在客户信息;
9、采集行业网站的产品目录和产品信息;
10. 同步各大电商平台商品信息,可在一个平台发布,在其他平台自动更新。
折叠编辑本款产品优势折叠操作简单
操作简单,图形化操作完全可视化,无需专业的IT人员,任何会用电脑上网的人都能轻松掌握。
折叠云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
折叠和拖动采集过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
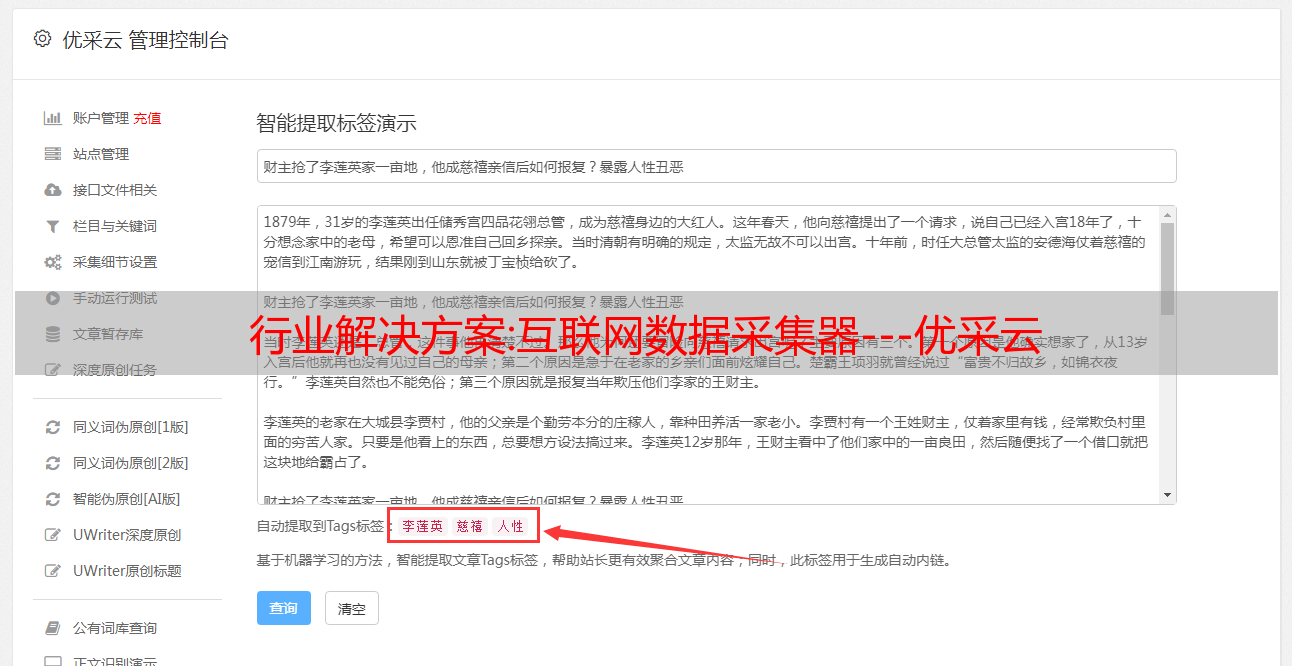
折叠图像识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
折叠定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
折叠 2 分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
折叠免费使用
它是免费的,免费版没有功能限制,您可以立即试用,立即下载安装。
配置视频教程:
解决方案:[平台建设] 大数据平台如何实现任务日志采集
背景
平台任务主要分为三种:flink实时任务、spark任务,以及java任务spark和flink。我们在纱线上运行。日常排查,我们通过查看yarn日志来定位,但是会设置一定的保留时间用于日志存储。, 为了以后更好的排查问题,希望spark、flink、java任务可以采集到ES中,为用户提供统一的查询服务。这是设计的动机。
这个想法要解决的主要问题是什么?
如何进行Flink、Spark、java logging采集如何在保证不影响任务部署的同时,尽量保持低耦合,用户端尽量少操作
查阅了相关资料后,选择了基于Log4实现一个自定义的Appender。实现方式更加优雅、轻量、易维护。
log4介绍
log4j 具有三个主要组件:
调用 log4j 组件执行顺序:
实现一个自定义 log4j Appender:
一般情况下,只需重写append方法即可。然后就可以在log4j中使用了
java 任务采集
对于java任务,我们只需要引入自己自定义的log4j Appender,就可以获取到相关的日志信息进行后续操作。
Flink 任务采集
因为Flink任务是在yarn上提交和执行的,所以我们需要采集除了日志信息,还需要想办法获取任务对应的应用id,这样更方便用户查询对应日志,并且设计必须满足查询 taskManger ,nodemanager 每个节点的日志
System.getProperty("mand") 获取当前正在执行的类,根据返回的字符串处理后,就可以得到你需要的相关信息。我们可以在yarn log中看到返回的结果,灵感也来源于此
如何判断不同的节点?
根据收录类org.apache.flink.yarn.entrypoint.YarnJobClusterEntrypoint判断是否为jobManager日志
根据返回值收录 org.apache.flink.yarn.YarnTaskExecutorRunner 判断是否是taskManager节点日志
火花任务采集
类似于 flink 处理
根据
org.apache.spark.executor.CoarseGrainedExecutorBackend 可以判断执行器日志
org.apache.spark.deploy.yarn.ApplicationMaster 是驱动日志
部署
1.log4j.properties 配置:
log4j.rootCategory=INFO, customlog, console
log4j.appender.customlog=com.aa.log.CustomlogAppender
29 log4j.appender.customlog.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
30 log4j.appender.customlog.layout=org.apache.log4j.PatternLayout
customlog 是我们自己定义的 logAppender 实现
将自定义的 Appender 程序打包,放在我们的 Flink 和 Spark 包下。Java程序采集引入我们的jar,排除其他日志框架,引入采集架构设计
通过 log4j appender 将 采集 的日志发送到接收中心。这里注意创建一个缓冲区,通过http批量发送到接收中心。日志太小,无法过滤掉。这里可以根据实际情况设置相应的策略,比如一分钟写,如果输入的消息很多,有可能用户把日志弄乱了,所以我们就停止发送,避免占满磁盘和影响其他用户。接收中心主要负责接收消息,然后写入kafka。Flink 消费 Kafka 的日志,执行简单的清洗和转换后,将数据下沉到 es 中。用户可以通过界面根据applicationId、时间、不同角色节点等各种条件进行过滤,
本文主要介绍基于log4j的自定义appender,实现了大数据平台采集相关的任务日志,用于处理不同类型的任务,获取我们平台最终搜索所需的功能。日志采集注意采集容量过大可能会填满磁盘,需要相应的降级或预防措施。用户不会过多考虑平台相关的事情。大数据平台技术目前很多大公司都有类似的技术架构。查看详细信息。
参考
/grh946/p/5977046.html
如果您觉得本文对您有帮助,请点赞、关注、支持

