教程:优采云采集内容自动排版-图片自动加水印保存
优采云 发布时间: 2022-10-20 11:36教程:优采云采集内容自动排版-图片自动加水印保存
优采云采集器内容排版,众所周知,优采云采集器的内容不能批量排版文章,图片也不可能排版. 保留原有风格需要HTML代码知识,这对很多不懂编程或代码的人来说不是很友好。今天给大家分享一个优采云采集器:免费采集→内容处理→主动发布和推送搜索引擎,详情请参考所有图片
1、文章内容的批量排版:对采集中的内容进行字号、行距、颜色、对齐、段落间距的处理(具体如下)
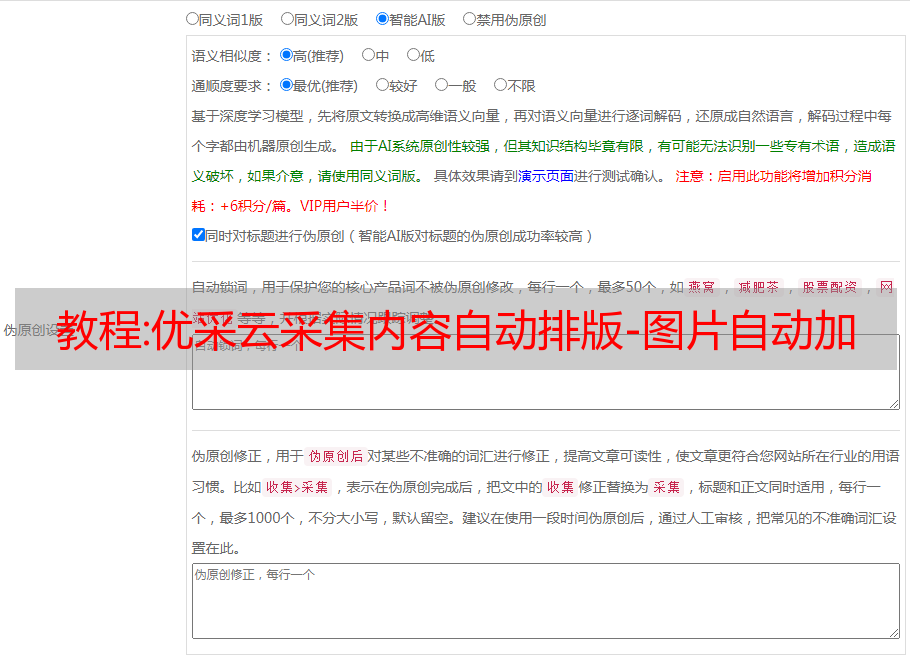
2.图片的批量处理(如下图)
图片水印类型:标题水印-目录标题水印-自定义水印
水印属性设置:水印背景-水印颜色-水印透明度-水印位置-水印大小
图片设置:图片压缩-图片大小设置
批量图片自动加水印的优点:不仅可以保护图片的版权,还可以防止图片被盗。图片加水印后,就形成了一张全新的原创图片。
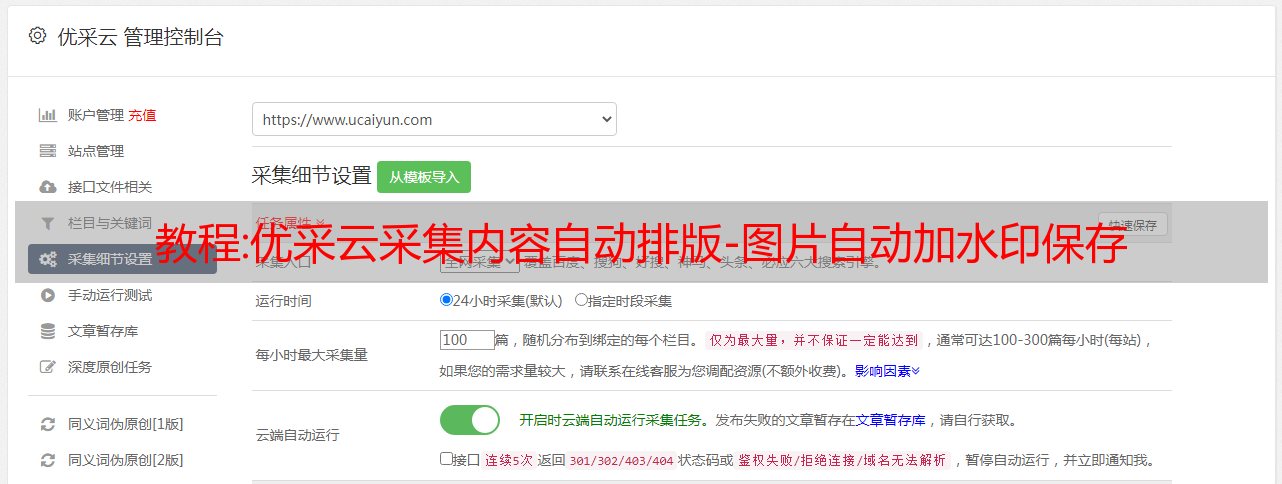
3、免费采集网站any data采集的指定如下图
无限网页,无限内容,支持多种扩展,选什么,怎么选,全看你自己!通过三个简单的步骤轻松实现 采集 网络数据。任意文件格式导出,无论是文字、链接、图片、视频、音频、Html源代码等均可导出,还支持自动发布到各大cms网站!
只需输入 关键词,然后输入 采集文章。关键词采集 中的 文章 与我的 网站 主题和写作主题 100% 相关,所以我找不到任何 文章 想法。麻烦。
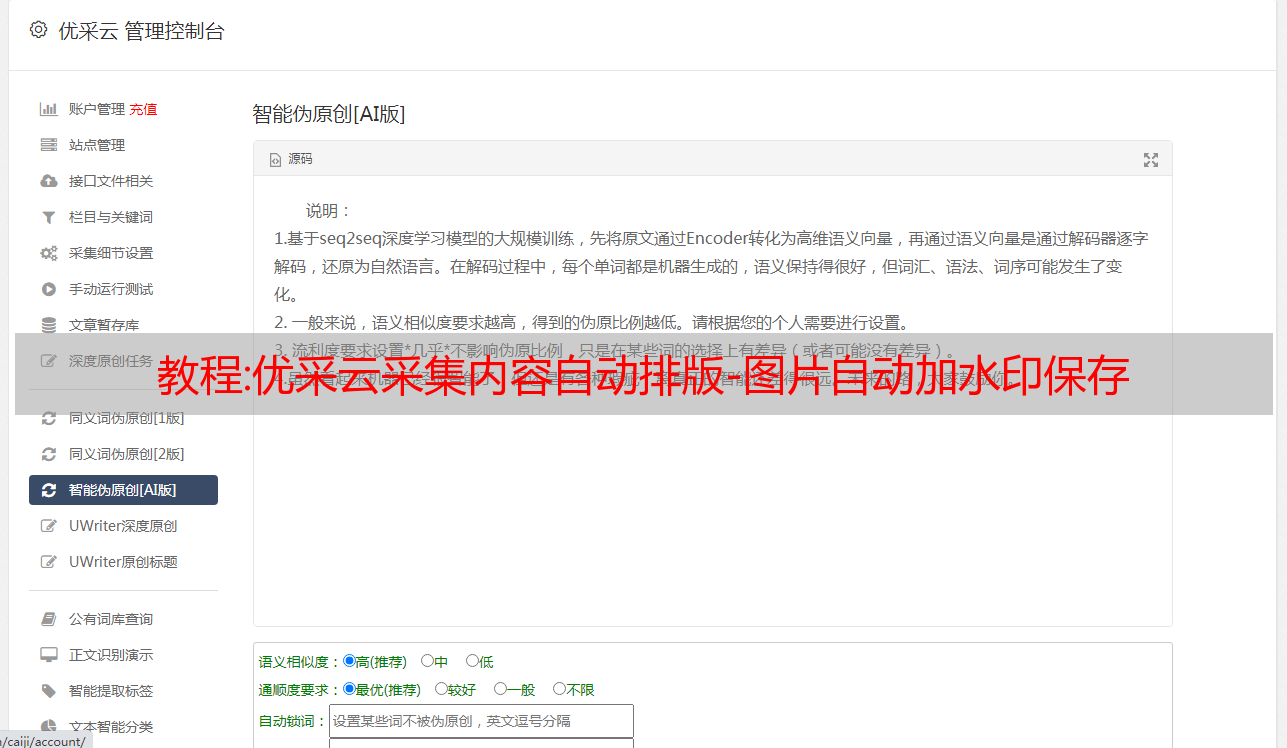
5.内容自动伪原创设置如下图
暴力版:原创地高是为全网搜索引擎开发的,对于搜索引擎来说是原创
温和版:原创度数没有暴力版高,流畅度更好)
伪原创范围:伪原创仅内容或标题+内容一起伪原创
保留词库:设置保留字后,伪原创不会对设置的保留字执行伪原创
自动内容伪原创的优点:伪原创的意思是重新处理一个原创的文章,让搜索引擎认为它是一个原创文章 ,从而增加网站的权重,再也不用担心网站没有内容更新了!
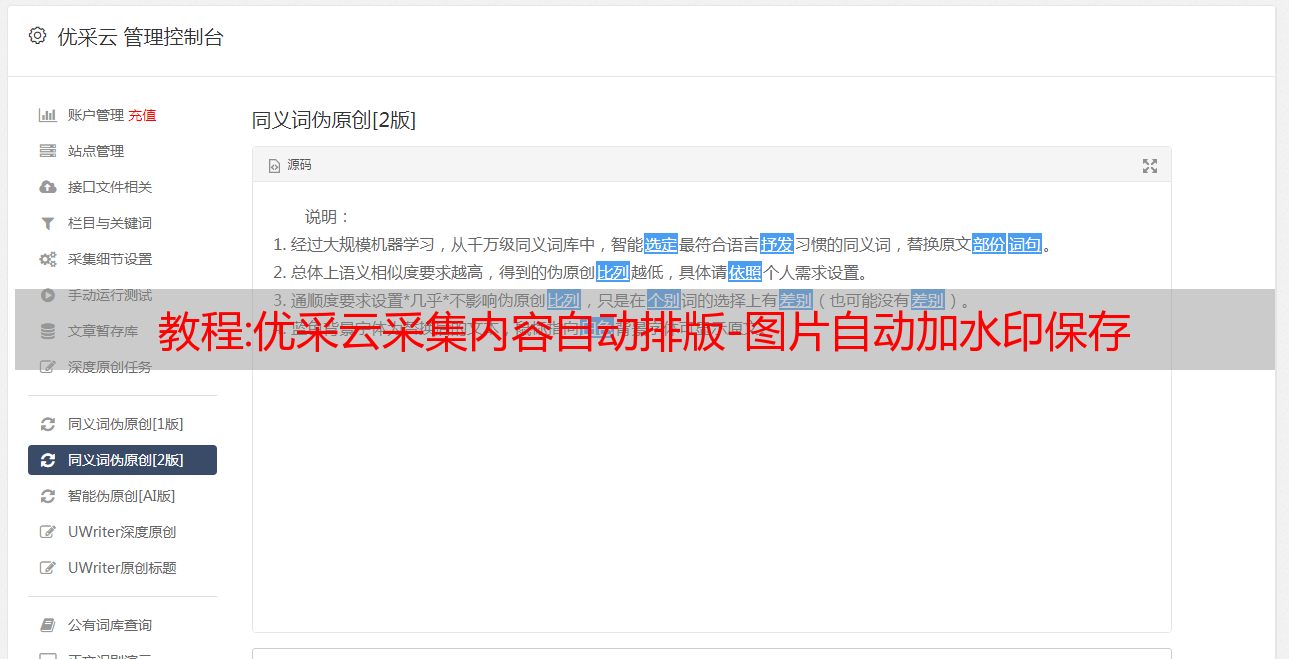
6.自动多语言翻译如下图
自动多语言翻译的特点:
主要语言翻译:中文、英文、日文、韩文、葡萄牙文、法文、*敏*感*词*文、德文、意大利文、俄文、泰文、阿拉伯文
回译:中译英中译回中文
翻译来源:百度翻译、有道翻译、谷歌翻译、147翻译(不限字数)
自动多语言翻译的优势:汇集了世界上几个最好的翻译平台,将内容质量提升到一个新的水平。翻译后不仅保留了原版面的格式,而且翻译的字数也不受限制。多样化的翻译让文章形成高质量的伪原创。
采集如何在内容之后推广内容网站收录
相信很多朋友过去都操作过采集网站项目,有的是人为抄袭的,有的是使用采集软件和插件快速获取内容的。尽管搜索引擎已经引入了各种算法来处理采集垃圾网站,但有些人做得更好,当然,这些一定不是我们想象的那么简单。
为什么更新文章要注意规律?很多人想一次性发布所有文章,然后就不管它了。的效果,定期更新也很重要。首先通过网站日志分析,搜索引擎蜘蛛经常来网站爬取的时间段是什么时候,找出最频繁的时间段,然后利用该时间段发布,同时避免网站内容被高权重同行抄袭。
每个 网站 都必须填充内容。在这个“内容为王”的网站时代,为了更好的优化网站,我写了很多疯狂的文章。不过有的SEOer觉得原创文章没有以前那么重要了,而是为了缩短时间,让网站优化,快速拥有大量内容,所以很多站长会选择使用采集软件采集文章。
那么如何让采集的内容产生优化值呢?你只需要对采集下点功夫,还是可以有一定效果的。下面我们来详细谈谈如何做。采集 增加内容的价值。
首先,修改标题、关键词 和描述。这是最基本的操作。如果这些不改,很快就会被百度认定为抄袭,所以网站的内容很难被百度收录使用,即使是收录,那么用户看到和其他网站一模一样的内容,加上你的内容排名垫底,显然获得点击的概率很低。而且,随着百度算法的进步,这种纯粹的抄袭采集模式显然已经过时了。
二是布局要优化。采集别人的内容也不能为别人的网页格式化采集,相当于复制了一个网页,很明显会被百度认为是抄袭或作弊,而且会也给用户带来了坏消息。现象。对于排版,首先要结合自己的网站整体风格进行排版,然后尽量减少广告图片或其他垃圾邮件,让采集的内容更加突出,所以以实现网页的差异化排版。
教程:全网采集工具(msray)-百度搜索引擎关键词全网采集
全网采集工具(MSRAY) - 百度搜索引擎进行全网采集
Msray-plus是一款以GO语言开发的企业级综合爬虫/采集软件。
支持:搜索引擎结果采集,域名采集,网址采集,网址采集,
全网域名采集、cms采集、*敏*感*词*、采集
支持数以亿计的数据存储、导入和重复判断。无需使用复杂的命令,提供本地WEB管理后台即可对软件执行相关操作,功能强大,使用方便!
1:用户导入关键词对应的搜索结果(SERP数据)可以从*敏*感*词*多个搜索引擎批量采集,并进行结构化数据存储和自定义过滤;
2:可从用户提供的URL*敏*感*词*地址自动抓取全网网站数据,并进行结构化数据存储和自定义过滤处理;
3:网站联系信息可以从用户提供的网站列表数据中自动提取,包括但不限于电子邮件,手机/电话,QQ,微信,脸书,推特等。
同时支持存储域名、根URL、网址(URL)、IP、IP国家、标题、描述、访问状态等数据,主要用于全网域名/网站/采集、行业市场调研分析、指定类型网站采集分析、网络推广分析等,并为各种大数据分析提供数据支持。
MSRAY-PLUS可以批量采集用户从*敏*感*词*多个搜索引擎导入关键词对应的搜索结果(SERP数据),并进行结构化数据存储和自定义过滤处理。可以存储和导出的数据包括:
所属引擎:如 baidu
关键词:如 招牌
域名:如 www.msray.net
根网址: 如 http://www.msray.net
网址(url): 如 http://www.msray.net/page/1.html
IP: 如 113.123.12.123
IP所属国家: 如 美国
标题:如 这是一个网站的标题
描述:如 这是一个网站的描述内容
访问状态码:如 200
<p>
</p>
目前,它支持百度手机,百度电脑,必应,谷歌,神马,搜狗,燕德,QWANT,鸭鸭Go等主流搜索引擎,并且正在不断被添加。
支持导出自动展开关键词数据,并显示展开词的来源;
支持根据*敏*感*词*连续关键词,全自动扩展相关单词和采集(无限采集);
1:配置采集参数
2:执行采集任务
3:采集预览结果

