文章采集站 大集合:[Cosplay]河豚抚子 – 温泉 [14P-133MB]
优采云 发布时间: 2022-10-19 19:24文章采集站 大集合:[Cosplay]河豚抚子 – 温泉 [14P-133MB]
材质说明
本站图片、视频等资料不提供任何资源预览,以免造成不必要的误解。如需了解资源预览,请从百度获取。
如资源链接无效、解压密码错误等请留言,防止分享R18+等缺失的素材资源。
严禁在网盘上解压任何资源。一经发现,会员将被删除,IP将被封禁。谢谢您的合作。
【资源名称】:【角色扮演】河豚抚子-温泉【14P-133MB】
【主题类型】:角色扮演
【版权声明】:互联网采集分享,严禁商用,最终所有权归素材提供者所有;
【下载方式】:百度网盘
【压缩格式】:zip、7z、rar等常用格式,下载部分资源后,更改后缀解压;【解压密码已测试!】
【温馨提示】:下载的资源包内有广告。本站不提供任何保证,请慎重!
【资源保障】:不用担心失败,资源有备份,留言后24小时内补档。
采集 终极:Kubernetes 集群中日志采集的几种玩法
介绍
对于企业应用系统来说,日志的状态非常重要,尤其是在Kubernetes环境中,日志采集比较复杂,所以DataKit对日志采集提供了非常强大的支持,支持多种环境,一个各种技术栈。接下来,我们将详细解释如何使用DataKit log采集。
前提
登录观察云,【集成】->【Datakit】->【Kubernetes】,按照提示在Kubernetes集群中安装DataKit,接下来的操作会用到部署的datakit.yaml文件。
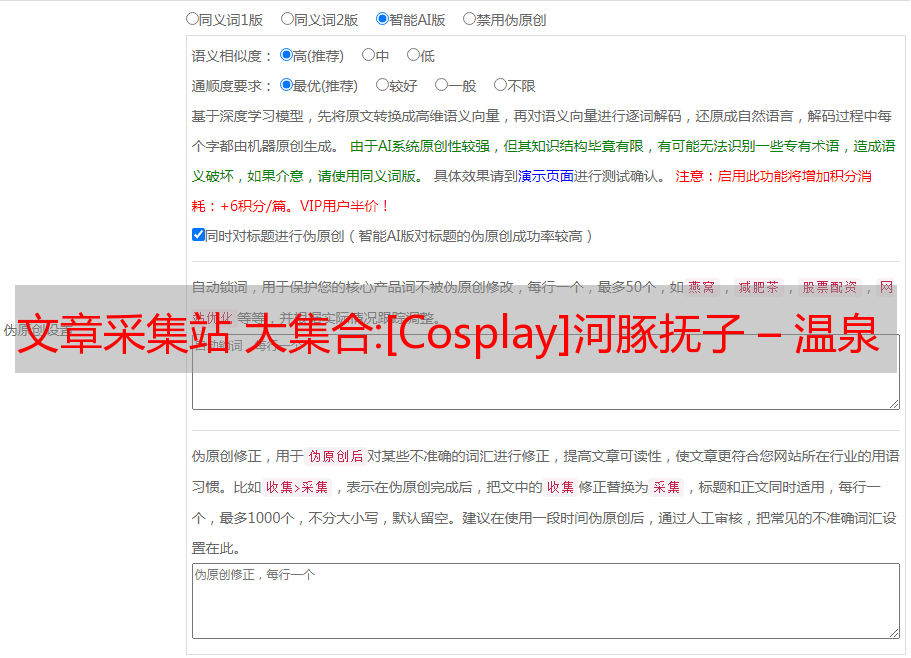
DataKit 高级配置 1 设置日志级别
DataKit 的默认日志级别是 Info。如果需要将日志级别调整为Debug,请在datakit.yaml中添加环境变量。
- name: ENV_LOG_LEVEL
value: debug
2 设置日志输出方式
DataKit 默认会输出日志到 /var/log/datakit/gin.log 和 /var/log/datakit/log。如果您不想在容器中生成日志文件,请在 datakit.yaml 中添加环境变量。
- name: ENV_LOG
value: stdout
- name: ENV_GIN_LOG
value: stdout
DataKit 生成的日志可以通过在 kubectl 命令中添加 POD 名称来查看。
kubectl logs datakit-2fnrz -n datakit #
“注意”:ENV_LOG_LEVEL设置为debug后,会产生大量日志。此时不建议将 ENV_LOG 设置为 stdout。
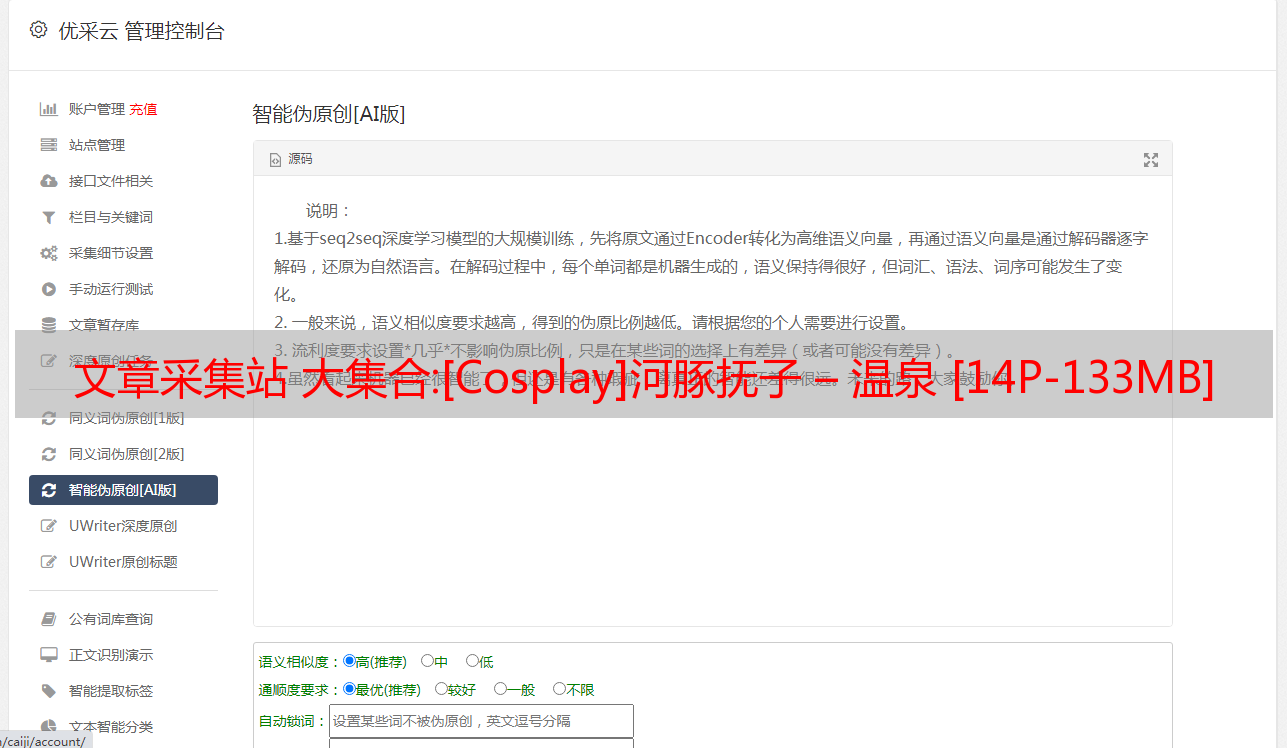
日志采集1 标准输出 采集1.1 标准输出日志已满采集
DataKit 可以采集 将容器日志输出到标准输出。使用 datakit.yaml 部署 DataKit 后,容器 采集器 已默认启用。
- name: ENV_DEFAULT_ENABLED_INPUTS
value: cpu,disk,diskio,mem,swap,system,hostobject,net,host_processes,container
此时会在DataKit容器中生成/usr/local/datakit/conf.d/container/container.conf配置文件。默认配置是 采集除以 /datakit/logfwd 开头的镜像之外的所有 stdout 日志。
container_include_log = [] # 相当于image:*
container_exclude_log = ["image:pubrepo.jiagouyun.com/datakit/logfwd*"]
1.2 自定义标准输出日志采集
为了更好的区分日志来源,添加标签,指定日志切割管道文件,需要自定义方法。也就是在部署的yaml文件中添加注解。
apiVersion: apps/v1
kind: Deployment
metadata:
name: log-demo-service
labels:
app: log-demo-service
spec:
replicas: 1
selector:
matchLabels:
app: log-demo-service
template:
metadata:
labels:
app: log-demo-service
annotations:
# 增加如下部分
datakit/logs: |
[
{
"source": "pod-logging-testing-demo",
"service": "pod-logging-testing-demo",
"pipeline": "pod-logging-demo.p",
"multiline_match": "^\d{4}-\d{2}-\d{2}"
}
]
注解参数说明
1.3 不要采集容器的stdout日志
当容器采集器启用时,它会自动采集容器输出日志到stdout。对于不想成为采集的日志,有以下方法。
1.3.1 关闭POD的STDOUT日志采集
在已部署应用的 yaml 文件中添加注解,并将 disable 设置为 true。
apiVersion: apps/v1
kind: Deployment
metadata:
...
spec:
...
template:
metadata:
annotations:
## 增加下面内容
datakit/logs: |
[
{
"disable": true
}
]
1.3.2 标准输出重定向
如果开启了标准输出日志采集,容器日志也会输出到标准输出。如果两者都不想被修改,可以修改启动命令来重定向标准输出。
java ${JAVA_OPTS} -jar ${jar} ${PARAMS} 2>&1 > /dev/null
1.3.3 CONTAINER 采集器的过滤功能
如果想更方便地控制stdout日志的采集,建议重写container.conf文件,即使用ConfigMap定义container.conf,修改container_include_log和container_exclude_log的值,然后将其挂载到datakit。修改datakit.yaml如下:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: datakit-conf
namespace: datakit
data:
#### container
container.conf: |-
[inputs.container]
docker_endpoint = "unix:///var/run/docker.sock"
containerd_address = "/var/run/containerd/containerd.sock"
enable_container_metric = true
enable_k8s_metric = true
enable_pod_metric = true
## Containers logs to include and exclude, default collect all containers. Globs accepted.
container_include_log = []
container_exclude_log = ["image:pubrepo.jiagouyun.com/datakit/logfwd*", "image:pubrepo.jiagouyun.com/datakit/datakit*"]
exclude_pause_container = true
## Removes ANSI escape codes from text strings
logging_remove_ansi_escape_codes = false
<p>
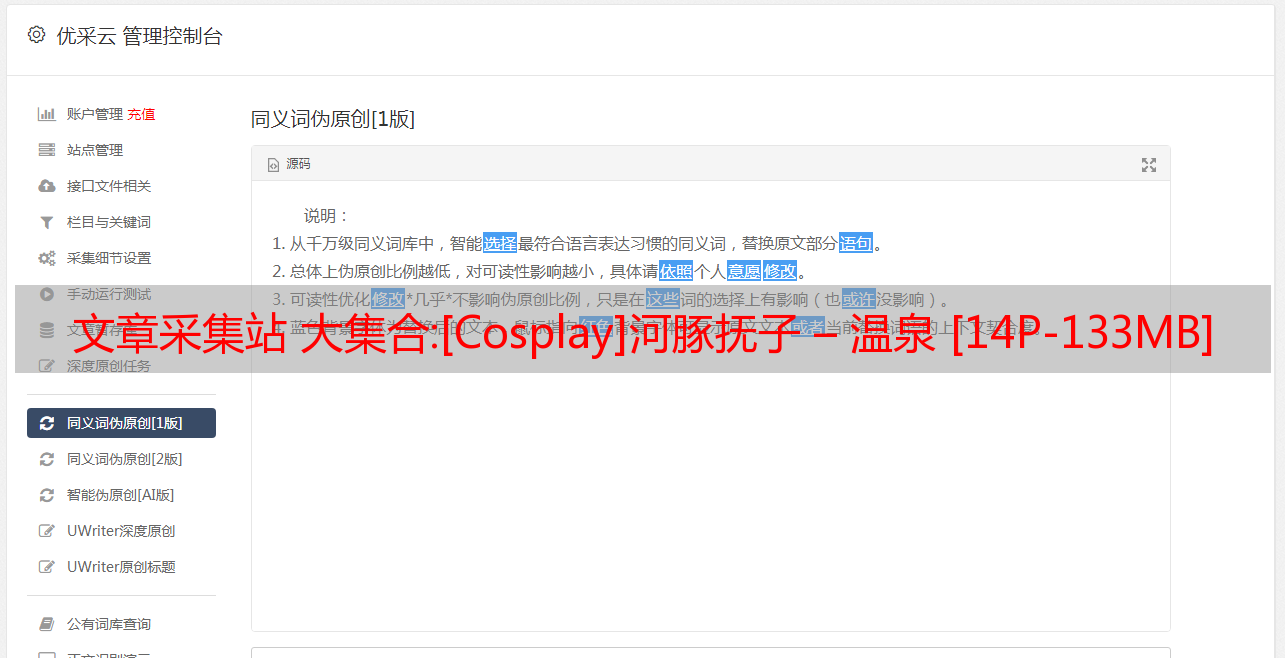
kubernetes_url = "https://kubernetes.default:443"
## Authorization level:
## bearer_token -> bearer_token_string -> TLS
## Use bearer token for authorization. ('bearer_token' takes priority)
## linux at: /run/secrets/kubernetes.io/serviceaccount/token
## windows at: C:\var\run\secrets\kubernetes.io\serviceaccount\token
bearer_token = "/run/secrets/kubernetes.io/serviceaccount/token"
# bearer_token_string = ""
[inputs.container.tags]
# some_tag = "some_value"
# more_tag = "some_other_value"
volumeMounts:
- mountPath: /usr/local/datakit/conf.d/container/container.conf
name: datakit-conf
subPath: container.conf</p>
例如,如果您只希望采集 图像名称收录 log-order,并且图像名称不收录 log-pay,则可以进行以下配置。
container_include_log = ["image:*log-order*"]
container_exclude_log = ["image:*log-pay*"]
“注意”:如果某个POD打开了采集stdout日志,请不要使用logfwd或socket日志采集,否则会重复采集日志。
2 logfwd 采集
这是一个使用 Sidecar 模式的 log采集 方法,即使用同一个 POD 中的容器共享存储,让 logfwd 以 Sidecar 模式读取业务容器的日志文件,然后发送到 DataKit . 具体用法请参考 Pod Log采集Best Practice 2。
3 个插座 采集
DataKit打开一个socket端口,比如9542,日志会被推送到这个端口。Java 的 log4j 和 logback 支持日志推送。下面以SpringBoot集成Logback为例,实现socket log采集。
3.1 添加Appender
在 logback-spring.xml 文件中添加 socket Appender。
logback
${log.pattern}
...
${dkSocketHost}:${dkSocketPort}
UTC+8
{
"severity": "%level",
"appName": "${logName:-}",
"trace": "%X{dd.trace_id:-}",
"span": "%X{dd.span_id:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"msg": "%message\n%exception"
}
3.2 添加配置
在 SpringBoot 项目的 application.yml 文件中添加配置。
datakit:
socket:
host: 120.26.218.200 #
port: 9542
3.3 添加依赖
在 SpringBoot 项目的 pom.xml 中添加依赖。
net.logstash.logback
logstash-logback-encoder
4.9
3.4 DataKit 添加 logging-socket.conf 文件
在 DataKit 的 datakit.yaml 文件中
volumeMounts: # 此位置增加下面三行
- mountPath: /usr/local/datakit/conf.d/log/logging-socket.conf
name: datakit-conf
subPath: logging-socket.conf
---
apiVersion: v1
kind: ConfigMap
metadata:
name: datakit-conf
<p>

namespace: datakit
data:
logging-socket.conf: |-
[[inputs.logging]]
# only two protocols are supported:TCP and UDP
sockets = [
"tcp://0.0.0.0:9542",
#"udp://0.0.0.0:9531",
]
ignore = [""]
source = "demo-socket-service"
service = ""
pipeline = ""
ignore_status = []
character_encoding = ""
# multiline_match = '''^\S'''
remove_ansi_escape_codes = false
[inputs.logging.tags]
# some_tag = "some_value"
# more_tag = "some_other_value"</p>
关于socket logging采集的更多信息,请参考logback socket logging采集最佳实践。
4 日志文件采集
Linux主机上安装的DataKit采集主机上的登录方式是复制logging.conf文件,然后将logging.conf文件中的logfiles值修改为日志的绝对路径。
cd /usr/local/datakit/conf.d/log
cp logging.conf.sample logging.conf
在Kubernetes环境中,需要先将Pod生成的日志目录/data/app/logs/demo-system挂载到宿主机的/var/log/k8s/demo-system,然后使用Daemonset部署DataKit,挂载 /var/log/k8s/demo-system 目录,以便 datakit 可以采集进入主机上的 /rootfs/var/log/k8s/demo-system/info.log 日志文件。
volumeMounts:
- name: app-log
mountPath: /data/app/logs/demo-system
...
volumes:
- name: app-log
hostPath:
path: /var/log/k8s/demo-system
volumeMounts: # 此位置增加下面三行
- mountPath: /usr/local/datakit/conf.d/log/logging.conf
name: datakit-conf
subPath: logging.conf
---
apiVersion: v1
kind: ConfigMap
metadata:
name: datakit-conf
namespace: datakit
data:
#### logging
logging.conf: |-
[[inputs.logging]]
## required
logfiles = [
"/rootfs/var/log/k8s/demo-system/info.log",
]
## glob filteer
ignore = [""]
## your logging source, if it's empty, use 'default'
source = "k8s-demo-system-log"
## add service tag, if it's empty, use $source.
#service = "k8s-demo-system-log"
## grok pipeline script path
pipeline = ""
## optional status:
## "emerg","alert","critical","error","warning","info","debug","OK"
ignore_status = []
## optional encodings:
## "utf-8", "utf-16le", "utf-16le", "gbk", "gb18030" or ""
character_encoding = ""
## The pattern should be a regexp. Note the use of '''this regexp'''
## regexp link: https://golang.org/pkg/regexp/syntax/#hdr-Syntax
multiline_match = '''^\d{4}-\d{2}-\d{2}'''
[inputs.logging.tags]
# some_tag = "some_value"
# more_tag = "some_other_value"
“注意”:由于日志是使用观察云采集的,所以日志已经持久化了,不需要将日志保存到主机。因此,在 Kubernetes 环境中不推荐使用 采集 的这种方法。
管道
Pipeline 主要用于切割非结构化文本数据,或者从结构化文本(如 JSON)中提取部分信息。对于日志,主要是提取日志生成时间、日志级别等信息。这里需要特别注意的是,Socket采集接收到的日志是JSON格式的,需要在搜索框中通过关键字进行搜索前进行剪切。有关管道使用的详细信息,请参阅下面的 文章。
异常检测
当日志出现异常,对应用影响较大时,使用观察云的日志异常检测功能,并配置告警及时通知观察对象。飞书等通知方式。下面以邮箱为例介绍告警。
1 创建通知对象
登录观察云,【管理】->【通知对象管理】->【新建通知对象】,选择邮件组,输入姓名和邮箱。
2 创建一个新的监视器¶
点击【监控】->【新建监控】->【日志监控】。
输入规则名称,检测指标log_fwd_demo为采集日志中配置的来源,以下错误为日志内容,host_ip为日志标签。在事件内容中,可以使用 {{host_ip}} 来输出具体 label 的值。触发条件填1,标题和内容将通过邮件发送。填写完成后点击【保存】。
3 配置警报
在【监控】界面,点击刚刚创建的监控,然后点击【告警配置】。
对于报警通知对象,选择第一步创建的邮件组,选择报警静音时间,点击【确定】。
4 触发警报
应用程序触发错误日志,此时会收到一封通知邮件。

