解决方案:采集内容管理平台采集方式+解析+存储+分析
优采云 发布时间: 2022-10-19 11:16解决方案:采集内容管理平台采集方式+解析+存储+分析
采集内容管理平台采集方式分为爬虫采集和深度采集,只有能采集更高质量的内容,则采集方式才能更有效率。通过爬虫采集,无需考虑采集网站稳定性,通过深度采集,需要更高质量的内容才能采集到目标网站,若采集到低质量的内容,则浪费时间和精力。采集大小分为单采集和多采集,单采集适合单条或单条数据,多采集适合多条、多条数据,多采集不适合采集大量数据。
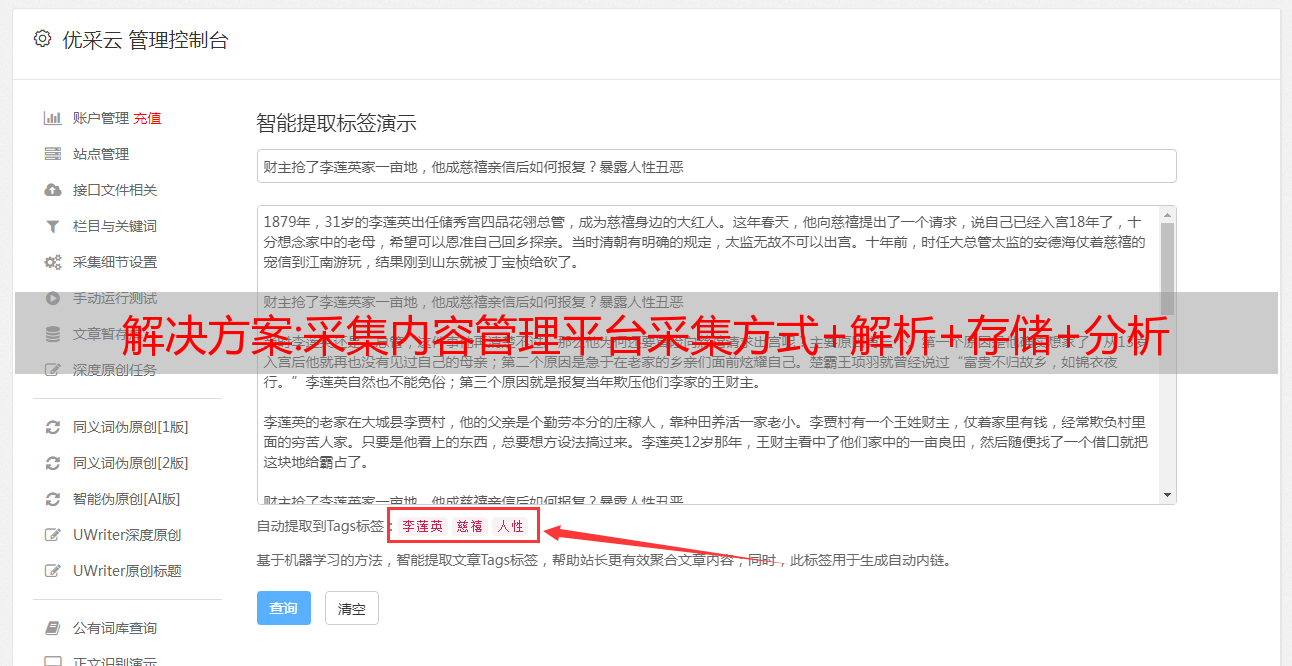
采集成本主要看采集哪些数据,单采集只需要通过提取规则,找到网页的指定位置即可,后续可以修改规则即可;多采集的流程相对复杂,需要提取规则,并且还要判断网页是否为原始网页。采集规则字段太多,一般不要超过20个字段字段,否则都需要注明是否采集。单采集适合单条或单条数据,多采集适合多条、多条数据,多采集不适合采集大量数据。
爬虫采集简单快捷,一个字段即可采集到整个页面,而且通过分析网页结构,可以提取关键字,然后通过规则形式,直接采集到内容。爬虫采集时,可以考虑通过多账号分布式采集,或是一台服务器单采集。深度采集适合多条、多条数据,且必须是相关内容,一般采集网站,必须采集完整网页才能采集到内容。采集存储流程整理,一般为多条、多条数据存储在第一个数据库中。
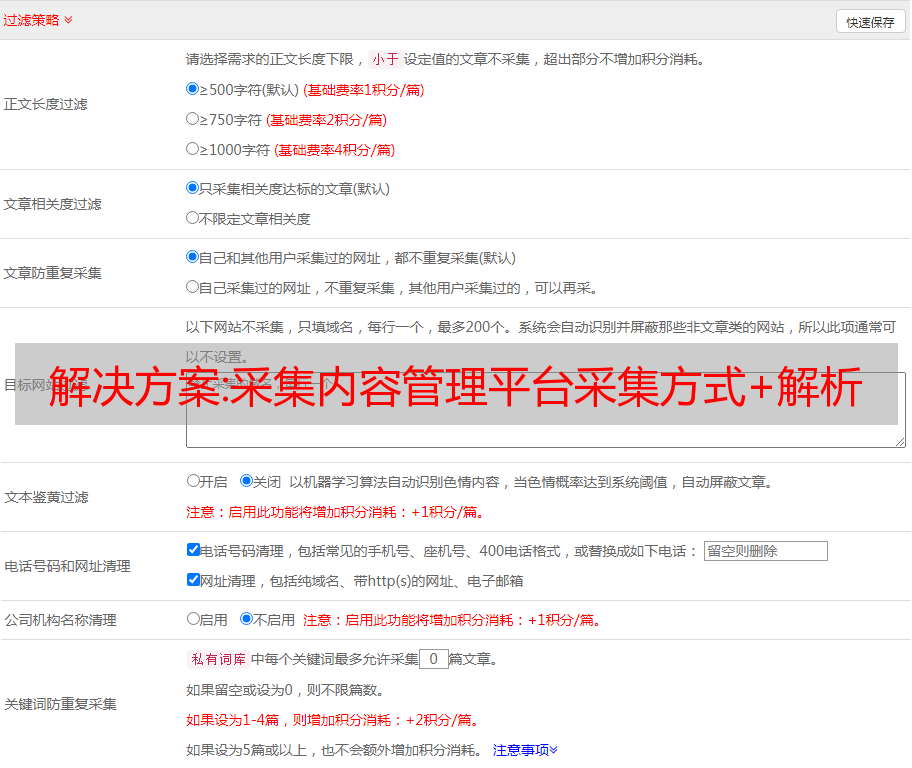
获取方式有外部代理与爬虫,外部代理代理成本相对较低,可以简单设置为使用,也可以上传代理进行无代理模式的爬虫,爬虫数据采集到一定量后可以将代理池进行清理存储。若是爬虫,则需要增加第二个代理池,以爬取相关内容为准。数据存储流程为爬虫+解析+存储+分析。爬虫属于开发人员设置,解析属于程序猿调试,存储一般是开发人员设置,分析由程序猿进行,建议选择全网爬虫,利于对接现有数据源,还可以利用spidermonkey进行反爬虫抓取,避免爬虫判断过于简单,可以通过代理池进行数据存储。
爬虫以追踪数据源为主,经常与其他爬虫有交互,无论爬虫是否存在,存储的工作都要先做完,也不容易出现数据丢失情况。爬虫的解析和存储分为下载与下载插件,下载以按目录存储,解析可以是网页存储,也可以是全文存储。在采集全文时,还需要对下载引擎进行正则匹配,否则下载的全文文件会有乱码等情况。下载代理适合有各种代理池,只需要爬虫接入下载引擎即可。
爬虫多采集属于同一爬虫库的,爬虫与爬虫之间互不影响,若是采集多个数据库,只需要对数据库链接即可,而且,数据库跨库的爬虫,切记区分数据库采集,避免频繁采集造成数据丢失。每采集一个网站,需要做数据存储解析。数据库之间互不影响,可以采取更新爬虫。多采集属于同一网站数据采集过多,可以加。

