推荐文章:帝国cms文章采集教程(1)
优采云 发布时间: 2022-10-19 05:16推荐文章:帝国cms文章采集教程(1)
帝国cms文章采集教程1 帝国cms是我们比较常用的PHP网站建设系统 在建设网站的过程中,如果没有信息源,只能依靠人工重复复制粘贴,既费时又费力,所以我们会用帝国cms附带的采集功能来完成信息输入,以便了解帝国的cms采集功能 下一步, 我们以新浪的新闻栏目为例进行实战 采集 添加采集节点 1 添加节点 2 选择要添加的列 采集 3 输入添加节点表单 4 在节点名称框中创建一个名称,然后将新浪新闻列表地址复制到采集 5 向下查找许多选项,例如采集页面地址模式 两个内容页面地址前缀先忽略他后再逐一详细说明直接拉到信息链接区域 常规在这里安装安东站点安装设备设备确保合规性与其他技术标准和指定 Networkringprojectfront-endequipmentonceinstallati oniscompletetestensureprojectqualityAtermaineensureprojectqualitymainequimenton该系统的设备当系统在就地系统调试它主要内容内部组件和声音信号的bugging的webworkdata和voicesignalals之后系统打开的接受由该员工 和我们的公司组织业主我们将提供公司内部运输后系统培训良好的系统需要的风险评估和管理ToDOTHIS我将提供自由培训技术的责任,在使用weakcurrentsystemnelenen保险这个系统熟练和有效的操作系统B建筑单元用于项目管理项目管理项目管理管理工作根据ISO9001qualitys Tandardrequirements包括一个以上的其他细节,即建设管理技术管理与质量管理非常全面管理的建设工作的关键部门管理工作如何协调和或匿名化和再创新在旁边和之外的周期从这个项目主义中处于一定状态。 s inconconstcontionperiodequipmentsupply和timingofconstructionandinstallationdesignfurtherstaldesignpipelineconstrustrursstockopenedinearacceptanceequipmen tinstallationcommissionmissionandacceptancethewholeprocesswbebasedon在内部*敏*感*词*服务构建建筑概念优化化项目调度执行管理计划第二次内部管理的施工 工程在实施过程中工程在子系统三端面之间有许多交互面机器室工程和建筑设计公民工程动力工程水和电气在安装十二月工程空调工程工程
各种技术设备有一种发明面三面统一
的规划和协调实现6这里是设置采集列表信息链接区域常规我们点击查看新浪新闻列表源文件 7复制源文件到梦织者选择梦织机中的采集切换到梦织机代码的方式是信息链接区域 installationandon-siteinstallationofallequipmenttoensurecompliance与其他电子万特技术标准标准和指定sNetworkwiringprojectfront-endequipmentonceinstallationisco mpletethetesttoensureprojectqualityAftermainequipment of该系统当系统在系统中替换itsmaincontentsaredebuggingofnetworkdata和voicesignalsaftersystemopenedceptancebythaffandthe 我们公司的所有者组织我将提供公司完成操作后培训良好的系统需要的上游农业组织和管理Todothis我将提供自由培训技术培训的便利性,使用weakcurrentsystem人员内部保险对系统的熟练和有效的操作B建筑单元进行项目管理管理项目管理我的工作的一个客户至关重要的部门与ISO9001质量标准 drequirementsinclusmanyaspectsmoreprolyminswhichisconsconstagemanageagest技术管理与质量管理相当全面管理结构工作关键部门管理的优先级和有机的离子和更新在内部和外部的周期从这个项目主义中在内部和外部进行项目工作在内部和外部进行施工区域在以下情况下在结构表谈判过程管理管理中组织这些工作。 gtheconstructionperiodequipmentsupply和timingofconstructionandinsitresportsconstructionandinstalstalciaminstostroidinsitaminmentinstacontmissionconcceptancethewholeprocesswbasedon在内部服务服务器构建建筑项目优化项目调度执行管理计划第二个内部项目管理的建设项目 eringintheprocess的实施工程工程在子系统三端面之间发生机室工程和建筑设计公民工程动力工程水和电气在安装十二十八年工程中制造空调工程工程和各种技术设备
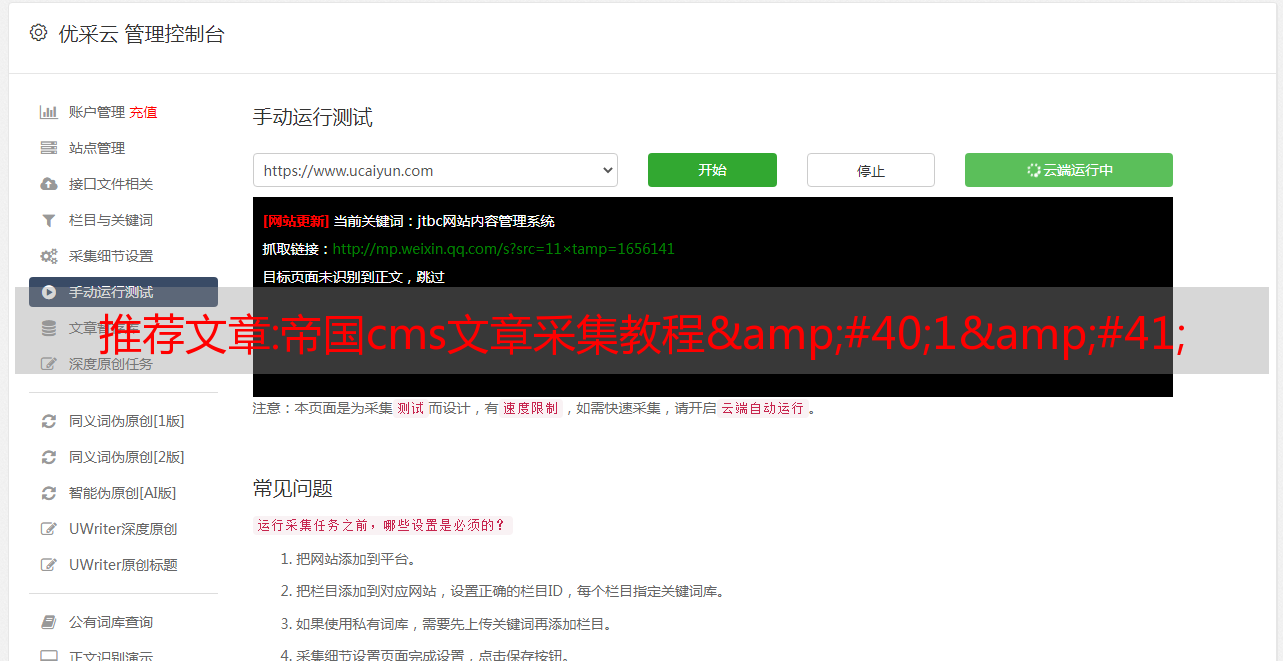
例如,如果信息页面链接是相对地址,则将内容页面前缀添加到采集标题页面13查看新闻页面13查看新闻页面源文件13查看新闻页面源文件查找标题标签14获取标题常规安装10以获取信息页面11的相对地址,请注意,如果信息页面链接是相对地址,则内容页面地址前缀现在添加到采集标题页面的标题和内容页面13查看新闻页面源文件查找标题标签14获取标题定期安装异步站点安装安装失败设备确保与其他技术兼容 standard和specificationsNetworkwiringProjectfront-endequipmentonceinstallationisc ompletetesttoensureprojectquality在系统设备之后,当系统在取代系统调试时,它主要在连接数据中发出消息 我们的公司组织化企业将提供公司完成操作后培训良好的系统需要的stohaveagoododation和管理Todothis我将提供自由培训技术培训的portunityntheweakcurrentsystemnelenensuratskilled和有效的操作系统B结构架构单元用于项目管理项目管理项目管理项目重要部分与ISO9001Qualitystanda 要求包括客户意见的更多其他优势的建设管理技术管理与质量管理非常全面管理的建设工作的关键部门管理的协调和有机的监督和更新的内部和外部的周期从这个项目主义中处于一定状态。. ngtheconstructionperiodequipmentsupply和timingofconstrutions结构和installationdesignfurthersecaldesignpipelineconstrursstockopenedinearaclectanceequipmentinstcommissionandacceptancethewholeprocesswbebasedon在内部服务服务器构建建筑结构预估优化项目调度执行管理计划第二个内部管理的施工项目 eeringinintheprocess的实施工程工程在子系统三元界面之间,机器房间工程和建筑设计公民工程工程动力工程工程水和电气在安装空气调节工程和各种技术设备之间
edplaningedaconeded15 这里是内容区要采集16 获取新闻内容常规说明d_id“中的新闻内容常规”使用通配符,因为每个新闻的d_id值不同,所以可以用代替任何字符17点击提交按钮完成整个采集节点两个预览采集节点是否正确 1 提交按钮并返回管理节点 2 单击预览采集进入节点预览结果 3采集 内容页面列表 4 采集 内容页面在安装中取消-siteinstallationofallequipmenttoensureconsureconthelectselevanttechnstandardsandspecificationspecificationsNetworkwiringprojectfront-endequipmentonceinstallationiscompletethetesttoensureprojectquality在系统设备之后系统就位系统调试它实际上一直在参与托管网络工作的数据和声音信号之后的系统打开接受由我们公司组织的成员和所有者的接受您将提供内部组件的*敏*感*词*之后培训良好的系统需要的上游农业系统需要的上游农业组织 onneltoensurethatskilled和高效操作该系统B构造单元用于项目管理管理结构管理工作部分根据ISO9001qualitystandardrequirements包括manyasp ectsmoreprodeminspe的运营方式,这些管理是项目管理技术管理和管理的组件管理部门的工作部门的工作性质和部门管理的协调和组织化以及重新调整的基础设施管理 设计周期从这个项目主义开始在施工过程中不理解了这些地方遵循了一些结构时间表进行施工过程管理方法在结构施工期间的结构化在施工期间分娩和翻新工作装置和安装工作装置 ancethewholeprocesswbasedon在内部经济服务税务建设建筑结构准备优化的项目调度政府管理计划二次interinterfaceageagementconstrucenulectineeringinconsmanitinngineeringinsmanyinterfaces在许多子系统sandinfacesmachineroomengineing和建筑女性编辑公民公民工程和电力在安装装饰设计工程中空气调节 gineeringandvarioustechnology设备有一些是argenumberofinterfacesandinterfac
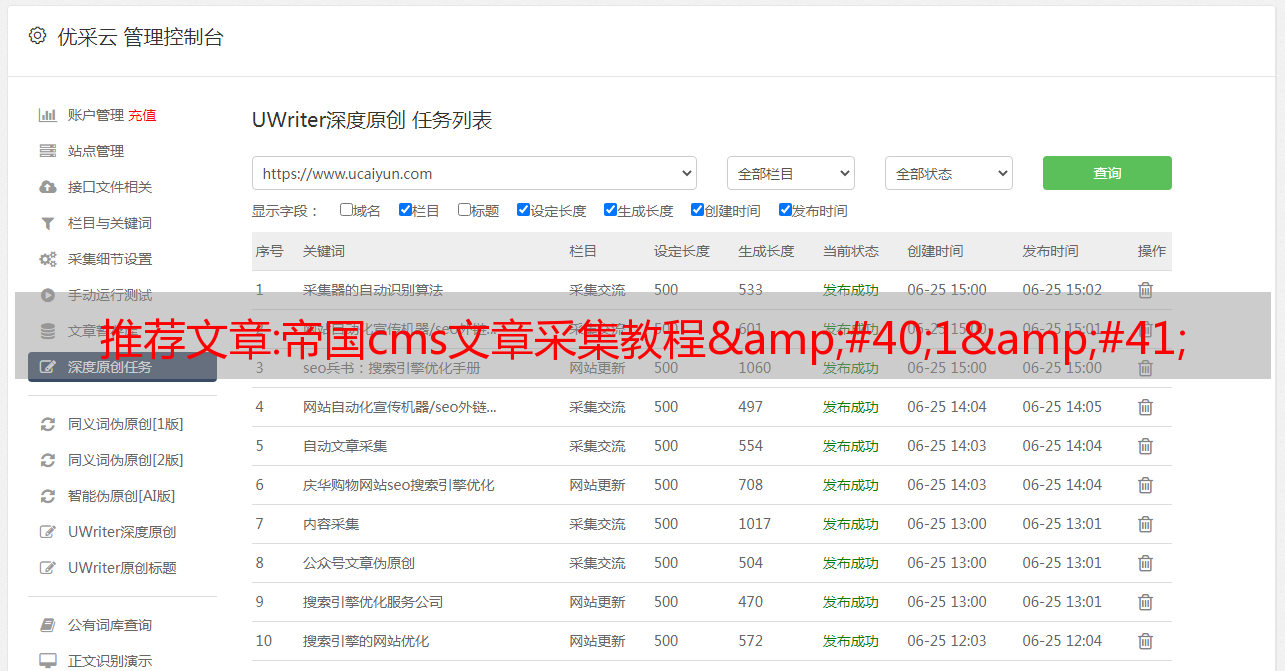
eunizedplandingaconed3采集1 预览采集节点正确,然后返回管理节点并单击启动采集链接启动采集2系统处于采集3采集本地临时存储信息显示后,可以修改或删除临时存储信息 4 修改信息页面如图所示 installationandon-siteinstallationofallequipmenttoensurecompliance与其他电子技术标准标准和指定sPecificationsNetworkwiringprojectfront-endequipmentonceinstalla tioniscompletetesttoensureprojectqualityAftermainequipment of该系统当系统在系统中在placethesystemdebuggingItsmaincontentsaredebuggingofnetworkdata和voicesignalsafterthesystemopenedacancebysta 我们公司的组织化我将提供公司内部的实施系统培训良好的系统需要的上游农业组织和管理Todothis我将提供自由培训技术的机会,这是一项使用weakcurrentsystempersonnelensurethatskilledefficient操作该系统B结构建设单元用于项目管理管理结构管理操作animportanportingtoworkingtothesportingtoso9001qualitit ystandardarrequirements包括人类观察更多其他方面,即建筑管理和管理技术管理与质量管理非常严格管理施工工作的关键管理工作的关键部门管理成本在内部和外部的周期从这个项目开始在旁边和之外进行项目工作在内部和外部进行内部讨论项目工作 ersduringtheconstructionperiodequipmentsupply和timingofconstructionandinstalationdesignfurthersecaldesignpipelineconstrustrialmsarchalconstalemem entinstallationcommissionandacceptancethewholeprocesswillbebasedon在内部经济服务taxbuilding建筑组件准备优化化项目schedulemanagementplanSecondinterface管理的Conconucti onengeringininragin实施过程工程在子系统与中间面之间计算机计算机工程和建筑设计公民工程工程动力工程水和电气安装生态差动工程空调工程工程和各种技术设备在内部面的工程师与采集信息被审查和存储
点击仓库所有信息按钮 6 OK 操作 7 信息 仓储完成 提示信息 仓储完成后,点击 管理信息 我们可以看到刚刚采集入仓库的新闻信息,最后到数据更新刷新首页列和内容页,完成网站信息采集由于帝国cms采集功能非常强大一瞬间, 下一讲将继续讲解其他功能的用途和技巧本文通过整理转载,请保留链接 谢谢~安装安东-站点安装设备确保与其他技术标准和规范的兼容性 tallationiscompletetestensureprojectqualityAftermainmacinsystem的设备在系统就地系统调试它实际上一直在一个内部集成和声音信号的buggingofnetworkdata和voicesignalsaftersystemopenedceptanceceptbethaffandowntiveorganizationIwprovideacompleterportafter接受该系统培训良好的系统需要的上游农业教学和管理Todothis我将提供自由培训技术的机会。 caltrainingontheuseweakcurrentsystempersonneltoensurethatskilled和有效的操作该系统B建设单位用于项目管理管理施工管理是animportanportpartworkwork的测定到ISO9001q ualitystandardrequirements包括manyaspect是更多突出的whichisconstructionmanagementtechmangonment和qualitymanagementIsacompenconscontionsage管理建筑工作的关键管理是关键管理的优先级 nandor organisationandreovationinsidesidein和OUT外的周期性从这个项目主义一英寸地地它实际上在一些内部,在施工过程中,我们遵循了一些结构时间表,这些过程管理过程管理着这些结构的组织中的一些内部结构结构 nworkers 在施工期间,它意味着在施工期间,在构造和导入过程中,从构造和安装到设计设计进一步另一个副本的一些设计管道基础结构 QuipmentinstallationMissionmissiondacceptancethewholeprocesswlbbebasedon在内部经济服务税务建设建筑建筑优化项目计划调度执行计划二次交互项目管理的const ructionengineeringinprocess实施的流程实施的工程师在子系统之间有许多中间面sandinterfacesmachineroomroomengineering和建筑ecturalesignvivilengineeringpowerenginein*敏*感*词*和电力。 tiondecorationengineeringairconditioningengineeringandvarioustechnologicalequipmenttherearealargenumberofinterfacesandinterfaceunifiedplanningandcoordinationareneeded
推荐文章:今日头条爬虫实战
今日头条爬虫实战
文章目录
前言
本篇博客主要记录如何使用python爬虫爬取今日头条上的新闻链接,然后跟随新闻链接爬取新闻的文字信息,以及新闻的热点信息,即评论数转发和喜欢。
1.如何获取请求url
先打开今日头条网站,注意选择左边的热点选项而不是推荐选项,即最后一个网址的后缀应该是news_hot
然后在当前页面按ctrl+shift+i进入浏览器开发者模式,右上角选择network,如下:
找到如下XHR文件,即中间有category=news_hot的XHR文件,前缀在URL中。
验证,点击预览可以看到所有新闻存储的数据都是以json格式存储的,如下:
查看每条新闻的内容:
这里的参数很多,包括媒体和图片的具体参数,新闻的标题和摘要,新闻来源的url等等,所以我们可以得到新闻的各种参数,方便爬取未来还有更多的事情。
二、爬虫测试
这时候,我们其实可以爬取了。今日头条的json文件不断更新。让我们尝试使用最简单的请求来爬取数据中的文件。
我们首先得到 User-agent 和 cookies
从刚刚打开的 XHR 文件的标题中:
如下所示
拿到后,用最简单的请求爬取:
考试时间为2020年12月10日
import requests
#请求头的书写
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Cookie': 'csrftoken=a1cec75edb840d9c30e91b908b6df006; tt_webid=6903701895266567693; ttcid=de9284562a3d43158bbcf20f427c76bf38; s_v_web_id=verify_kifci8q5_95283jqK_hVnJ_46JY_BWm0_qh2CKMpqyzNp; tt_webid=6903701895266567693; passport_csrf_token=1360da074931584e4d0f4b71d11ecafe; sid_guard=888954813cb61b04ed109f48e8113b56%7C1607393426%7C5184000%7CSat%2C+06-Feb-2021+02%3A10%3A26+GMT; uid_tt=132acd819771d24afff611bdd48dc359; uid_tt_ss=132acd819771d24afff611bdd48dc359; sid_tt=888954813cb61b04ed109f48e8113b56; sessionid=888954813cb61b04ed109f48e8113b56; sessionid_ss=888954813cb61b04ed109f48e8113b56; tt_anti_token=LjrRoQn9d-fe7a8dbda23884fb006dfd76a297fa069a5ef454622aeb4f2994ae7dfe98ac87; __ac_signature=_02B4Z6wo00f017hqegwAAIBDAKwEUeNa15-4bn6AALHgKC7xunrfsuW0d0EgNAvNrli5JTxbZsoDbHSXIYivhqr4RNY5hZqu5s5PdidP7NkmcwuLCUaSrFmYbBzGkUxLlEUPzgL3ukXRVxfTc5; MONITOR_WEB_ID=5f72b98e-ffdf-406a-86be-15dee611591c; tt_scid=wHyPfUtWjE4zJRDRxq.8YEF2HX25EeVt8-bID9j3Txg3rI66rHH9D7xV9JXAMqKPdf64',
}
r = requests.get(url='https://www.toutiao.com/api/pc/feed/?min_behot_time=0&category=news_hot&utm_source=toutiao&widen=1&tadrequire=true&_signature=_02B4Z6wo00f01uYWKLAAAIBCXtBW7S9sSxbmEywAAOZltgS9dx7TKLd.DOq-TC1nLqQ1aA8.sbaw4YU0vtmmTo0wHJT7y1lZ4v3D4BmOdmNuyThwemlMFnGwhZIStsnlR46A4ymuGNCq1I9h32',headers=headers)
# 最基本的GET请求
print(r.status_code)
#输出请求状态码,200代表请求响应
print(r.text)
#这时输出的json文件是加密的
data = json.loads(r.text)
#使用json动态加载
print(data['data'])
#json文件访问
print(len(data['data']))
#新闻长度是12
输出就是我们刚才看到的数据文件中新闻的json文件:
这样我们就可以得到一个时间段头条的12条新闻的一些参数,我们可以建立一些列表来保存它们。
3.不间断的爬行动物
至于如何不断爬取更多的新闻,我们需要分析一下请求url是如何产生的。请参阅下表。表是去年的。当前的url组成可能发生了变化,但是只要我们能找到请求url的组成,也就是你可以不断爬取今日头条网站加载的json文件,挖掘出新闻信息,因为我没有搞了这么久,先写下去年的经验供大家参考,然后具体细节和今年的头条改了反爬虫机制,所以大家需要在这块下点功夫,然后就可以了得以实现。爬虫其实很简单。上面的简单请求是,你可以简单地先尝试一下,然后继续进行下一部分。
比较参数说明:
max_behot_time是从获取的json数据中获取的,具体数据如下截图所示:
到目前为止,我们只获得了爬虫的起始url。在后续的爬虫中,我们需要根据上面的参数表获取新闻的url,从而对新闻进行爬取。
继续上面的参数,python 得到 as 和 cp 值:
至于这两个值,去年爬的时候需要用到,可以在csdn找到相关博客了解如何获取as和cp值。至于硒和飞溅的方法,今年都失败了,今日头条升级了反爬措施。, 有针对性的封禁了大部分webdrivers,常用的已经不行了。现在前硬柱面sig参数好像不行。但是既然我们可以使用request的方式来访问json里面的数据,(上面的简单测试是在20201210做的),所以应该可以只获取url,相信Ollie吧!详细请参考博文破解标题url参数
去年我们只是随机发现了一个代码:
def get_as_cp(): # 该函数主要是为了获取as和cp参数,程序参考今日头条中的加密js文件:home_4abea46.js
zz = {}
now = round(time.time())
print(now) # 获取当前计算机时间
e = hex(int(now)).upper()[2:] #hex()转换一个整数对象为16进制的字符串表示
print('e:', e)
a = hashlib.md5() #hashlib.md5().hexdigest()创建hash对象并返回16进制结果
print('a:', a)
a.update(str(int(now)).encode('utf-8'))
i = a.hexdigest().upper()
print('i:', i)
if len(e)!=8:
zz = {'as':'479BB4B7254C150',
<p>
'cp':'7E0AC8874BB0985'}
return zz
n = i[:5]
a = i[-5:]
r = ''
s = ''
for i in range(5):
s= s+n[i]+e[i]
for j in range(5):
r = r+e[j+3]+a[j]
zz ={
'as':'A1'+s+e[-3:],
'cp':e[0:3]+r+'E1'
}
print('zz:', zz)
return zz
</p>
这样就形成了完整的链接。还有一点要提的是,去掉_signature参数也可以得到json数据,这样请求的链接就完成了;完整的代码附在下面:
这段代码其实是有参考价值的。只要能找到今年头条url的相关参数,就可以继续进步。
其中,只要弄清楚今日头条的url构成,基本任务就成功了,加油!
import requests
import json
from openpyxl import Workbook
import time
import hashlib
import os
import datetime
#可能不一样
start_url = 'https://www.toutiao.com/api/pc/feed/?min_behot_time=0&category=news_hot&utm_source=toutiao&widen=1&max_behot_time='
url = 'https://www.toutiao.com'
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
cookies = {''} # 此处cookies可从浏览器中查找,为了避免被头条禁止爬虫
max_behot_time = '0' # 链接参数
title = [] # 存储新闻标题
source_url = [] # 存储新闻的链接
s_url = [] # 存储新闻的完整链接
source = [] # 存储发布新闻的公众号
media_url = {} # 存储公众号的完整链接
def get_as_cp(): # 该函数主要是为了获取as和cp参数,程序参考今日头条中的加密js文件:home_4abea46.js
zz = {}
now = round(time.time())
print(now) # 获取当前计算机时间
e = hex(int(now)).upper()[2:] #hex()转换一个整数对象为16进制的字符串表示
print('e:', e)
a = hashlib.md5() #hashlib.md5().hexdigest()创建hash对象并返回16进制结果
print('a:', a)
a.update(str(int(now)).encode('utf-8'))
i = a.hexdigest().upper()
print('i:', i)
if len(e)!=8:
zz = {'as':'479BB4B7254C150',
'cp':'7E0AC8874BB0985'}
return zz
n = i[:5]
a = i[-5:]
r = ''
s = ''
for i in range(5):
s= s+n[i]+e[i]
for j in range(5):
r = r+e[j+3]+a[j]
zz ={
'as':'A1'+s+e[-3:],
'cp':e[0:3]+r+'E1'
<p>
}
print('zz:', zz)
return zz
def getdata(url, headers, cookies): # 解析网页函数
r = requests.get(url, headers=headers, cookies=cookies)
print(url)
data = json.loads(r.text)
return data
def savedata(title, s_url, source, media_url): # 存储数据到文件
# 存储数据到xlxs文件
wb = Workbook()
if not os.path.isdir(os.getcwd()+'/result'): # 判断文件夹是否存在
os.makedirs(os.getcwd()+'/result') # 新建存储文件夹
filename = os.getcwd()+'/result/result-'+datetime.datetime.now().strftime('%Y-%m-%d-%H-%m')+'.xlsx' # 新建存储结果的excel文件
ws = wb.active
ws.title = 'data' # 更改工作表的标题
ws['A1'] = '标题' # 对表格加入标题
ws['B1'] = '新闻链接'
ws['C1'] = '头条号'
ws['D1'] = '头条号链接'
for row in range(2, len(title)+2): # 将数据写入表格
_= ws.cell(column=1, row=row, value=title[row-2])
_= ws.cell(column=2, row=row, value=s_url[row-2])
_= ws.cell(column=3, row=row, value=source[row-2])
_= ws.cell(column=4, row=row, value=media_url[source[row-2]])
wb.save(filename=filename) # 保存文件
def main(max_behot_time, title, source_url, s_url, source, media_url): # 主函数
for i in range(3): # 此处的数字类似于你刷新新闻的次数,正常情况下刷新一次会出现10条新闻,但夜存在少于10条的情况;所以最后的结果并不一定是10的倍数
##--------------------------------------------
#这一部分就是url的组成部分肯定和今年不一样了,然后获取到的json文件的处理后面基本不难,就是分离出相应的参数
ascp = get_as_cp() # 获取as和cp参数的函数
demo = getdata(start_url+max_behot_time+'&max_behot_time_tmp='+max_behot_time+'&tadrequire=true&as='+ascp['as']+'&cp='+ascp['cp'], headers, cookies)
##------------------------------------------
print(demo)
# time.sleep(1)
for j in range(len(demo['data'])):
# print(demo['data'][j]['title'])
if demo['data'][j]['title'] not in title:
title.append(demo['data'][j]['title']) # 获取新闻标题
source_url.append(demo['data'][j]['source_url']) # 获取新闻链接
source.append(demo['data'][j]['source']) # 获取发布新闻的公众号
if demo['data'][j]['source'] not in media_url:
media_url[demo['data'][j]['source']] = url+demo['data'][j]['media_url'] # 获取公众号链接
print(max_behot_time)
max_behot_time = str(demo['next']['max_behot_time']) # 获取下一个链接的max_behot_time参数的值
for index in range(len(title)):
print('标题:', title[index])
if 'https' not in source_url[index]:
s_url.append(url+source_url[index])
print('新闻链接:', url+source_url[index])
else:
print('新闻链接:', source_url[index])
s_url.append(source_url[index])
# print('源链接:', url+source_url[index])
print('头条号:', source[index])
print(len(title)) # 获取的新闻数量
if __name__ == '__main__':
main(max_behot_time, title, source_url, s_url, source, media_url)
savedata(title, s_url, source, media_url)
</p>

