干货教程:短视频如何下载和批量伪原创?这里有个方法
优采云 发布时间: 2022-10-18 17:26干货教程:短视频如何下载和批量伪原创?这里有个方法
今天金旋风论坛分享短视频伪原创方法,需要使用短视频分析下载软件,MD5值短视频修改软件,使用liwo视频转换器剪辑视频. 完成这三个基本步骤后,你的短视频就伪原创成功了。另外,小编提醒大家,搬砖的重点是将热门视频从一个短视频平台转移到另一个平台。如果还在同一个平台,很容易被举报降级。
最近一段时间,各种短视频软件可以说是蓬勃发展,日新月异。梨视频、快手、抖音短视频势头相同,发展迅猛。很多人也看到,这种发展势头的影响是非常大的。
如果我们能想办法把视频伪装成原创视频,不让视频平台审核,我们就很容易成功。下面将详细介绍如何将传输的视频处理成原创视频!
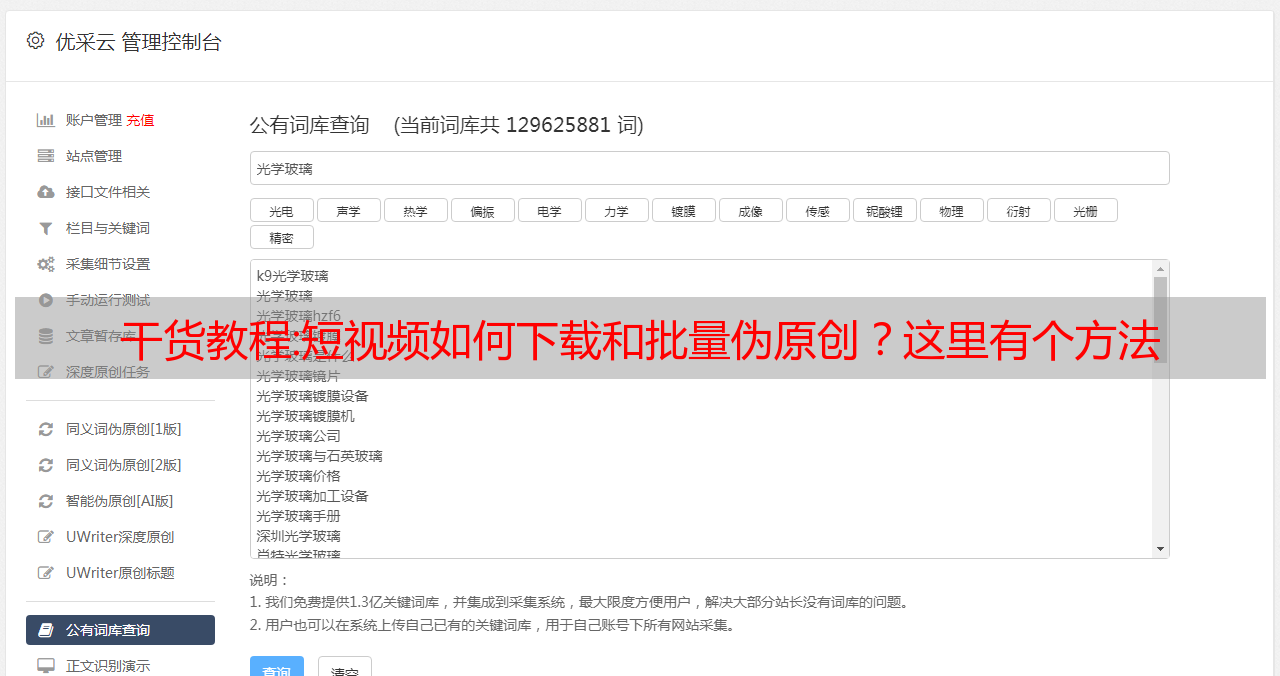
1.使用短视频分析下载软件
首先你需要知道。com 网站(不是广告,真的好用!),很多情况下可以下载无水印视频。操作方法是先点击右上角的视频分析下载,然后下载你要下载的视频。
如果找不到链接,以抖音为例,点击右下角的分享会有一个复制链接,复制链接粘贴到这里点击分析视频,那里有不同的图像质量可供选择!如果你不知道如何在其他平台上找到链接,你可以自己百度一下。下载的视频没有水印!
2. MD5值短视频修改软件
这还没有完成,我们还要对视频进行处理,保证不被平台发现。
干货教程:Python一键下载文章,转制成PDF格式电子书
前言
前段时间,我发了一段关于某个姓氏B的视频,也就是采集文章,把它转换成PDF格式的教程,CSDN居然向我报告了!!!
现在我要写一文章,让自己以电子方式将其转换为PDF格式,看看我是否可以发送出去
wkhtmltopdf [软件],这是必须学习的,否则这种情况将无法实现 获取文章内容代码 发送请求,发送请求解析URL地址的数据,提取内容以保存数据,将其另存为html文件然后将html文件转换为PDF
#代码实现
请求数据
import requests # 数据请求模块
url = f'https://blog.csdn.net/fei347795790/article/list/1' # 确定请求网址
# headers 请求头, 主要用于伪装python, 防止程序被服务器识别出来
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36'
}
# 用requests模块里面get方式发送请求
response = requests.get(url=url, headers=headers)
print(response.text)
<p>
</p>
响应对象 200 表示请求成功
解析数据,提取内容
for index in href:
html_data = requests.get(url=index, headers=headers).text
selector_1 = parsel.Selector(html_data)
title = selector_1.css('#articleContentId::text').get()
content = selector_1.css('#content_views').get()
article_content = html_str.format(article=content)
print(title)
print(article_content)
break
保存数据
html_path = 'html\' + title +'.html'
with open(html_path, mode='w', encoding=' utf-8') as f:
<p>
f.write(article_content)
print(title,'保存成功')
</p>
转换为 PDF 文件
html_path = 'html\ + title + '.html'
pdf_path = 'pdf\' + title + '.pdf'
with open(html_path, mode='w', encoding='utf-8') as f:
f.write(article_content)
config = pdfkit.configuration(wkhtmltopdf=r'C:
-Software-installation\wkhtmltopdf\bin\wkhtmltopdf.exe')ppdfkit.from_file(html_path,pdf_path,configuration=config)
print(title,'保存成功')

