核心方法:企业站点seo问题解决方法(批量化)
优采云 发布时间: 2022-10-18 02:22核心方法:企业站点seo问题解决方法(批量化)
问题处理网站
1.首先确认你最近(1个月内)有没有做过网站的事情,比如改标题,批量删除文章图片等等,空间有没有变过,有没有是否有任何停机时间等记录;
2.查看时间。如果是新站,很难关键词,可以暂时忽略;
3.百度:网站标题,看是不是在第一位,如果是,继续看关键词难度等级,是难字还是特殊字;如果标题不在首位,直接按网站降级处理;
5. 有排名的问题或单词、易上手的单词、反馈和链接;
6.查看链接网站是否有问题
7、按照降权标准网站降权/关键词排名降;
一个。网站处于降级状态,如果尝试其他方法半个多月仍未恢复,请更改主页标题和适当的文字;
湾。网站如果状态正常,如果有排名但是排名不好,每周导入5条好友链,记得在前台查看好友链是否显示添加成功;
C。网站上线3个月以上且无任何排名的,更改首页标题及适当字词,协助导入好友链;
d。如果标题改了,排名又恢复了(有一定概率再过几天排名又掉了),点击方式合适,进行点击操作;
标题修改原则
尽可能收录主题
尝试在主语相关词中收录更多的长尾词根,并优先考虑出现的长尾词根
尽量匹配关键词
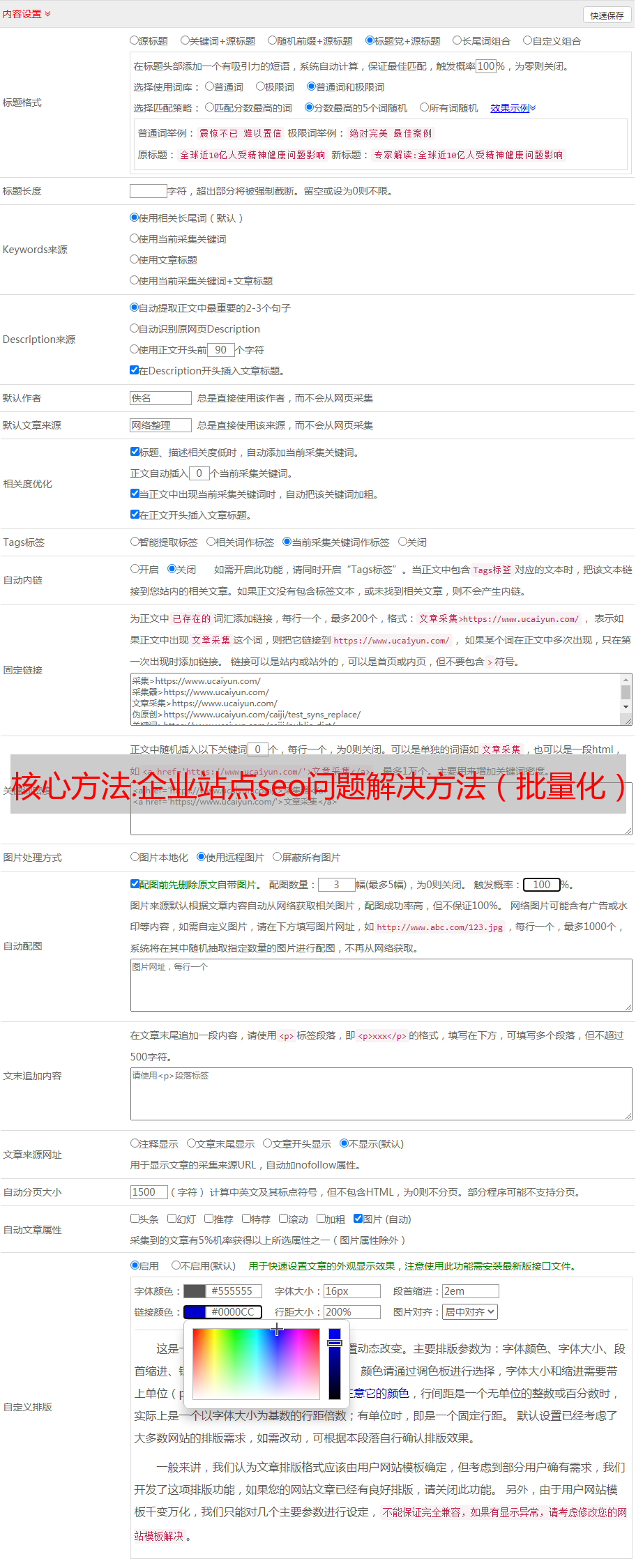
网站降级(搜索标题不在顶部)/关键词排名(关键词排名超过100):
附:首先确认一下你最近(1个月内)是否做过网站的操作,比如改标题、批量删除文章图片等,是否有改过的记录空间等;
1、先检查空间的稳定性,如果空间真的不稳定,就换空间;检查同一个ip网站(域名/)的降级和合法性,如果有灰*敏*感*词*点,最好换个空间;这主要是为了记录;
2、是否被域名或泛端口入侵或链接或劫持,如果是,按相应方法处理;
3.检查死链接并提交(网站链接抓取器+死链接检查神器+百度死链接xml*敏*感*词*);
4、查看首页状态码是否为200,查看隐藏链接(隐藏链接检测工具)、404页面状态码(http状态码批量查询工具)是否返回404和robots,隐藏链接被清除;
5.查看好友链状态网站(优采云采集网站的所有好友链-excel处理后-爱站批量查询网站 status ),导出问题站(被黑后立即删除,过期后多次检查等)并删除;
6.检查网站中的问题,如页面h1标签是否过多(剩下一个),垃圾新闻是否过多(首页换成优质的),机器人文件是否正常,弹窗是否过多(在网站中尽量往两边移动,多于2个尽量去掉多余的),是否关键词 堆叠(同一版块中同一个词太多,可以用相关词调整),网站 是否长时间没有更新(反馈给频道提供者准备新闻);
7、查看网站有没有变化(可以和百度截图对比),比如标题、页面布局等,如果有变化,可以观察一段时间再谈;
8、在百度站长工具后台查看百度索引量是否正常(正常也有可能异常,说明网站即将挂机),抓取异常记录(避免)、安全监控(处理)、网站死链接(提交)、关键词点击率(增加)、网站外链(查看传入链接是否为死链接) ,并有针对性地进行处理;
9.是否有很多收录或者镜像(搜索标题和站点主域和百度www没有www域名),低权重301到高权重,修改后提交网站修改在百度后台;网站这种排名长期监控,不在未来两个月的范围内,或者直接换域名换空间;
10.半年多网站没有维护,或者站内垃圾太多文章(占比50%+)
11. 降级网站 修改标题(根据关键词的状态加长尾巴),首页布局,首页新闻或产品,首页文字信息等。排名下降后半个月内不要修改首页标题。排名下降半个月后更改首页标题(根据关键词的状态调整,容易前移或拉长尾巴),相关词和词(首页密度等)
12、以上问题改正后,向平台发送几秒,将未提交的类别提交;定期更新一些优质新闻(一天一篇文章能持续半个月以上更好)
13、超过2个月不恢复,直接放弃,为重做空间换域名;如果排名超过两个月没有效果,特殊词将被更改;
网站收录index.html 主域名后缀
如果百度收录的首页是index.html,可能是网站的排名不好,或者排名下降了;出现这个后,按照以下方法一一检查
1、去服务器查看默认首页是否设置为index.html,如果没有,将默认首页改为index.html;
2、查看404页面是否有index.html首页的链接,如果有,立即更改;
3、查看全站所有页面,将所有收录/index.html的首页链接修改为不收录/index.html的链接。使用Xenu死链接检测工具查看所有网站链接,打开Xenu,点击“文件”-“检查URL”,然后在弹出的输入框中输入你的主域名,点击确定,等待100% 显示完成。(完成后会提示是否生成报告,选择否;另外,该工具还可以用来整理网站链接,查询哪些页面被百度收录。)然后点击“编辑”-“查找”,输入“index.html”,点击查找下一个,以检查是否有index.html的主域名,如果发现有这样的链接,则很容易解决。
直接右键点击链接,然后点击属性选项,会弹出一个对话框,会显示链接出现在哪些页面或哪些页面上,然后找到这些页面,将链接改成里面的index.html。而已。(打开问题页面,然后右键页面内容选择查看源文件显示网页代码,然后搜索index.html找到问题链接)。
对于网站如何得到30多个长尾词
1.site:域名,看首页是否在顶部,搜索网站的标题,看首页是否在首页,如果不是,看排名靠前的页面在网站之后,搜索百度排名前5的页面标题;如果第一页有标题排名,进入第二步,如果没有,进入第三步;
2.对于上一步百度收录的结果页,如果第一页有标题排名,则从上到下对每个标题进行分段,拆分出可靠词。从短到长,查找百度首页是否有文字记录;这一步可以演变为先对词进行分组,然后通过斗牛工具批量查询排名;
3、如果没有排名,调出网站的历史记录(如果每个网站都报告有问题,及时记录),看看这个网站之前做了什么操作,比如更改标题、删除新闻、空格等都不起作用。如果有,说明网站目前处于不稳定状态,需要百度调查后再给出排名;
如果没有操作,新建的网站会有一个审核期,审核期可长可短,审核期结束后发布排名。这段时间不要有什么不好的操作,我就给这里。加强; 加强;
【附】拆分词大致分为:主词+长尾(价格、厂家、公司、规格、型号、批发、哪里好、怎么样、地址等)、品牌+主词、地区+主词、地区+主词+长尾、品牌+主词+长尾、新闻头条的可靠部分,以及其他从嘴里分裂出来的词,也可以用产品词代替主词;
网站收录三级域名的预防和处理
1、本地测试后上传到空间前,全站使用绝对路径;
2、使用canonical标签,三级域名打开下一页源码中的canonical,写入一级域名;
3、三级域名指向一级域名;
SEO工具的使用
1、爱站seo工具包(免费+付费)、站群查询、竞价词挖掘、关键词挖掘、关键词实时监控、百度url提交
2. 优采云采集器(免费+付费)
实践思路:面向容器日志的技术实践
摘要:本文以Docker为例,结合阿里云日志服务团队在日志领域多年积累的丰富经验,介绍容器日志处理的通用方法和最佳实践。
背景
自2013年dotCloud开源Docker以来,以Docker为代表的容器产品以隔离性好、可移植性高、资源占用少、启动快等特点迅速风靡全球。下图显示了 2013 年以来 Docker 和 OpenStack 的搜索趋势。
容器技术在部署、交付等环节给人们带来了很多便利,但在日志处理领域也带来了很多新的挑战,包括:
如果日志保存在容器内,在容器销毁时会被删除。由于容器的生命周期与虚拟机相比大大缩短,创建和销毁都是正常的,所以需要一种持久化日志的方式;
进入容器时代后,需要管理的目标对象远多于虚拟机或物理机。登录目标容器排查问题会变得更加复杂和不经济;
容器的出现让微服务更容易实现,引入更多组件的同时也给我们的系统带来了松耦合。因此,我们需要一种既能帮助我们全局了解系统运行情况,又能快速定位问题现场、还原上下文的技术。
日志处理流程
本文以Docker为例,介绍容器日志处理的一般方法和最佳实践,包括:
容器日志实时采集;
查询分析和可视化;
日志上下文分析;
LiveTail - 云上的 tail -f。
容器实时日志采集
容器日志分类
采集Logs 首先,我们需要找出日志存在的位置。这里以两个常见的容器 Nginx 和 Tomcat 为例进行分析。
Nginx 生成的日志包括 access.log 和 error.log。根据 nginx Dockerfile,access.log 和 error.log 分别被重定向到 STDOUT 和 STDERR。
Tomcat 会生成很多日志,包括 catalina.log、access.log、manager.log、host-manager.log 等。tomcat Dockerfile 不会将这些日志重定向到标准输出,它们存在于容器内部。
容器产生的大部分日志都可以归结为上述情况。在这里,我们不妨将容器日志分为以下两类。
标准输出
使用日志记录驱动程序
容器的标准输出会被日志驱动统一处理。如下图所示,不同的日志驱动程序会将标准输出写入不同的目的地。
通过日志记录驱动程序 采集 的容器标准输出的优点是使用简单,例如:
缺点
使用 json-file 和 journald 以外的其他日志记录驱动程序将使 docker logs API 不可用。比如当你在宿主机上使用portainer管理容器,并且使用上述两种以外的日志驱动时,你会发现无法通过UI界面观察到容器的标准输出。
使用 docker 日志 API
对于那些使用默认日志驱动的容器,我们可以通过向 docker daemon 发送 docker logs 命令来获取容器的标准输出。使用这种方法采集log的工具有logspout、sematext-agent-docker等。下面例子中的命令意思是获取容器自2018-01-01T15:00:00以来的最新5条日志。
缺点
当日志量较大时,这种方式会给 docker daemon 带来很大的压力,导致 docker daemon 无法及时响应创建容器、销毁容器等命令。
采集 json 文件文件
默认的日志驱动程序会将日志以json格式写入主机文件,文件路径为/var/lib/docker/containers//-json.log。这样,采集容器标准输出的目的就可以通过直接采集host文件来实现。
推荐这种方案,因为它既不会使 docker logs API 不可用,也不会影响 docker daemon,而且现在很多工具都原生支持 采集host 文件,例如 filebeat、logtail 等。
文本日志
挂载主机目录
采集容器中文本日志最简单的方法是在启动容器时通过bind mounts或者volumes将宿主目录挂载到容器日志所在目录,如下图。
对于tomcat容器的访问日志,使用命令docker run -it -v /tmp/app/vol1:/usr/local/tomcat/logs tomcat挂载主机目录/tmp/app/vol1到访问日志中容器在目录/usr/local/tomcat/logs上,通过采集主机目录/tmp/app/vol1下的日志实现采集tomcat访问日志的目的。
计算容器rootfs挂载点
使用挂载宿主目录采集log的方法会侵入应用程序,因为它需要容器在启动时收录mount命令。如果 采集 进程对用户是透明的,那就太好了。实际上,这可以通过计算容器 rootfs 挂载点来实现。
与容器 rootfs 挂载点密不可分的一个概念是存储驱动程序。在实际使用中,用户往往会根据Linux版本、文件系统类型、容器读写条件等因素来选择合适的存储驱动。在不同的存储驱动下,容器的rootfs挂载点遵循一定的规则,所以我们可以根据存储驱动的类型来推断容器的rootfs挂载点,然后采集容器的内部日志。下表显示了某些存储驱动程序的 rootfs 挂载点以及如何计算它们。
Logtail解决方案
在充分对比采集容器日志的各种方法,综合梳理用户的反馈和诉求后,日志服务团队推出了容器日志的一站式解决方案。
特征
logtail解决方案包括以下功能:
支持主机上容器的采集主机文件和日志(包括标准输出和日志文件);
支持容器的自动发现,即当你配置了一个采集目标时,每当有满足条件的容器被创建时,容器上的目标日志就会自动采集;
支持通过docker标签和环境变量过滤指定容器,支持白名单和黑名单机制;
采集数据自动标记,即在采集的日志中自动添加容器名称、容器IP、文件路径等信息标识数据源;
支持 采集 K8s 容器日志。
核心优势
通过检查点机制和部署额外的监控流程来保证至少一次语义;
经过多次双11和双12的测试,以及阿里巴巴集团内部百万级的部署规模,稳定性和性能非常有保障。
K8s 容器日志采集
与K8s生态深度融合,非常方便采集 K8s容器日志是日志服务logtail解决方案的另一大特色。
采集配置管理:
支持采集通过WEB控制台进行配置管理;
支持采集通过CRD(CustomResourceDefinition)方式进行配置管理(这种方式更容易与K8s部署发布流程集成)。
采集模式:
通过DaemonSet方式支持采集K8s容器日志,即在每个节点上运行一个采集客户端logtail,适用于单功能集群;
通过Sidecar方式支持采集K8s容器日志,即在每个Pod中以容器的形式运行一个采集客户端logtail,适用于大型、混合、PAAS集群。
关于Logtail方案的详细说明,请参考文章综合改进、阿里云Docker/Kubernetes(K8S)日志方案及选型对比。
查询分析和可视化
完成日志采集工作后,下一步就是对这些日志进行查询、分析和可视化。以Tomcat访问日志为例,介绍日志服务提供的强大的查询、分析、可视化功能。
快速搜索
当容器日志为采集时,会携带容器名称、容器IP、目标文件路径等信息,所以在查询的时候可以通过这些信息快速定位目标容器和文件。查询功能的详细介绍请参考文档查询语法。
实时分析
日志服务的实时分析功能兼容SQL语法,提供200多种聚合功能。如果您有使用 SQL 的经验,您可以轻松编写满足您业务需求的分析语句。例如:
计算访问的前 10 个 uri。
统计当前 15 分钟内网络流量相对于前一小时的变化。
该语句使用同比链函数计算不同时间段的网络流量。
可视化
为了让数据更加生动,您可以使用日志服务内置的各种图表将 SQL 计算结果可视化,并将图表组合成一个仪表板。
下图是一个基于Tomcat访问日志的dashboard,展示了不良请求率、网络流量、状态码随时间变化趋势等信息。此仪表板显示多个 Tomcat 容器的聚合数据。您可以使用仪表盘过滤功能,通过指定容器名称来查看单个容器的数据。
日志上下文分析
查询分析、仪表盘等功能可以帮助我们掌握全局信息,了解系统的整体运行情况,但定位具体问题往往需要上下文信息的帮助。
上下文定义
上下文是指围绕问题的线索,例如日志中错误的上下文。上下文由两个元素组成:
下表显示了不同数据源的最小区分粒度。
上下文查询的挑战
在集中式日志存储的情况下,采集 端和服务器端都很难保证日志的原创顺序:
在客户端层面,一个主机上运行着多个容器,每个容器都会有多个需要采集的目标文件。log采集软件需要利用机器的多个CPU核对日志进行解析和预处理,通过多线程并发或单线程异步回调处理网络发送的IO慢问题。这可以防止日志数据按照机器上事件的生成顺序到达服务器。
在服务器层面,由于采用水平可扩展的多机负载均衡架构,同一客户端机器的日志会分散在多个存储节点上。根据分散的日志很难恢复原来的顺序。
原则
日志服务通过在每条日志中附加一些额外的信息以及服务器的关键词查询能力巧妙地解决了上述问题。原理如下图所示。
当日志为采集时,用于标识日志源的信息(即上面提到的最小区分粒度)会自动添加为source_id。对于容器场景,信息包括容器名称、文件路径等;
日志服务的各种采集客户端一般都会选择批量上传日志,多条日志形成一个数据包。客户端会向这些包写入一个单调递增的package_id,包中的每条日志在包内都有一个偏移量;
服务器会将 source_id、package_id 和 offset 组合为一个字段并为其构建索引。这样,即使各种日志在服务器上以混合状态存储,我们也可以根据source_id、package_id和offset,精确定位到一条日志。
如果想详细了解上下文分析的功能,请参考文章上下文查询,分布式系统日志上下文查询功能。
LiveTail - 云尾 -f
除了查看日志的上下文信息,有时我们还希望能够持续观察容器的输出。
传统方式
下表展示了如何在传统模式下实时监控容器日志。
痛点
通过传统方式监控容器日志存在以下痛点:
当容器较多时,定位目标容器耗时耗力;
不同类型的容器日志需要不同的观察方式,增加了使用成本;
关键信息查询展示不够简单直观。
功能与原理
针对这些问题,日志服务推出了LiveTail功能。与传统模式相比,具有以下优点:
可根据单个日志或日志服务的查询分析功能快速定位目标容器;
在不进入目标容器的情况下,统一观察不同类型的容器日志;
支持关键词过滤;
支持设置键列。
在实现方面,LiveTail 主要是利用上一章提到的上下文查询原理来快速定位目标容器和目标文件。然后,客户端定期向服务器发送请求以提取最新数据。
视频样本
也可以观看视频进一步了解采集的功能,容器日志的查询、分析和可视化。
参考
结尾
更令人兴奋的

