解决方案:ICMS也能用的CMS采集发布插件
优采云 发布时间: 2022-10-17 02:09解决方案:ICMS也能用的CMS采集发布插件
Icms插件让我们无需任何专业技能即可轻松管理我们的网站,操作简单易用,快捷方便的可视化页面让我们管理自己的爱站。Icms插件有关键词挖矿、网站文章自动管理和网站数据屏显管理。可以实现我们的Icms网站的挂机管理。
我cms是一个比较小众的cms,但在同类产品的对比中,我cms突出了轻量级、功能强大、源码简洁、系统安全等特点,提供一个开源接口,让我们的Icms插件可以轻松管理我们的Icms。
1. 关键词 挖矿
关键词作为我们网站的灵魂,我们需要仔细分析,不断挖掘。Icms插件可以通过关键词挖矿功能让我们的关键词一直流行。通过搜索引擎下拉词和相关词挖掘,我们可以利用我们核心的关键词 >联想匹配大量相关词,通过关键词的自动排名,我们可以挑出关键词 和适合我们的长尾 关键词 网站。
2.全网采集
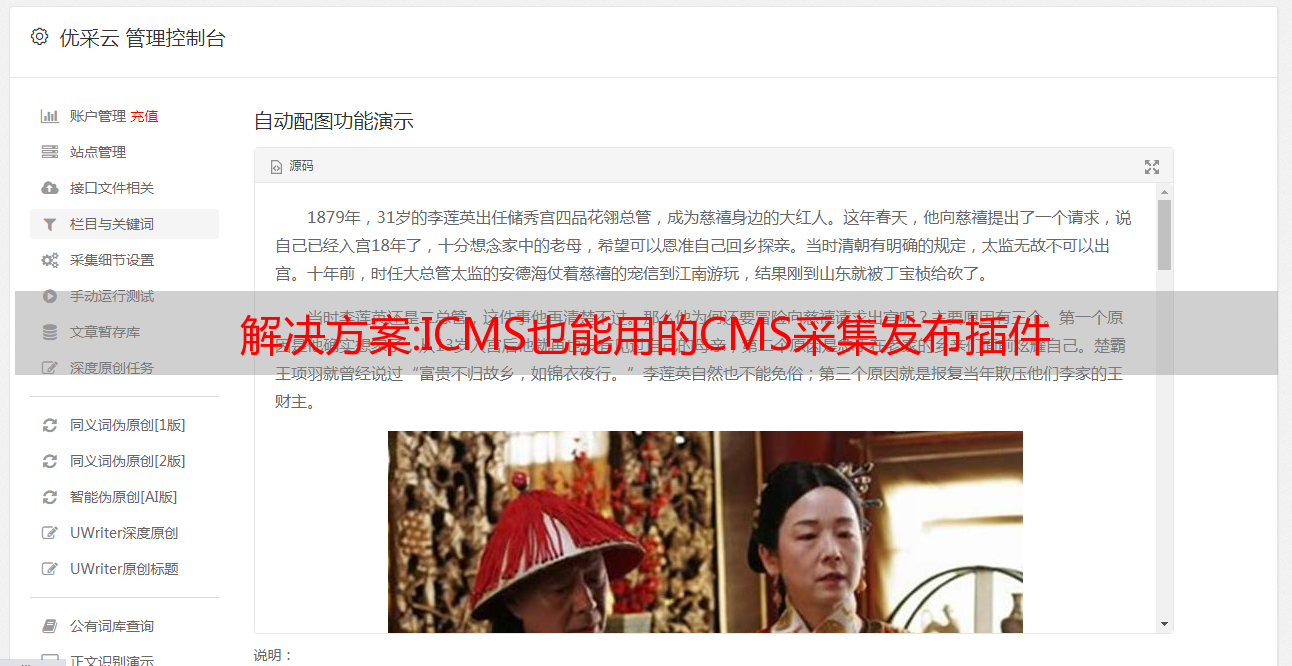
我cms网站每日更新文章是我们SEOER的日常工作。如何保持网站文章被搜索引擎点赞和被用户点击的质量是我们关心的问题。用户通过搜索词找到自己的答案,我们通过我们的关键词构建构建和提高关键词排名,让用户更容易点击。所以我们的网站文章更新也和我们的关键词密切相关。
Icms 插件具有 关键词采集 并指定 网站增量监控采集。Icms插件可以进行全网文章采集、排名第一的文章采集和流行的网站监控。我们可以实现海量网站文章素材合集,源源不断的文章素材可供我们使用。
3. SEO管理
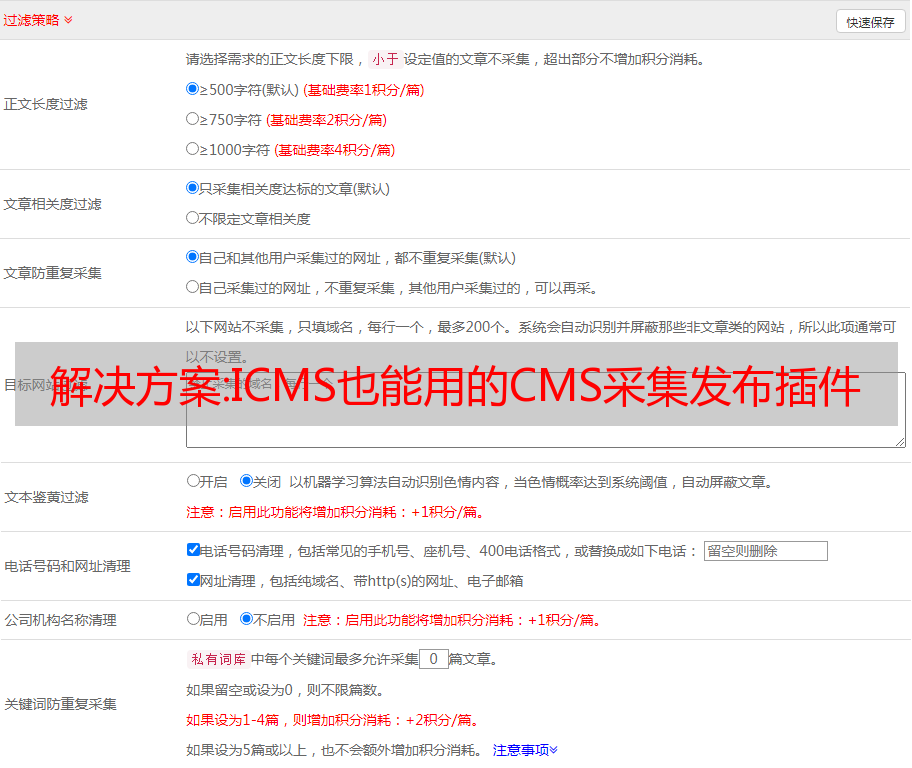
有素材和文章不足以提升我们对网站收录和关键词的排名,而我们的文章满足了用户的需求,我们还需要拿考虑到搜索引擎的规则,通过在两者之间找到一个平衡点,可以让文章快收录,获得一定的排名。当然,这个过程需要坚持,因为SEO本身就是一个慢速搜索引擎。建立信任的缓慢过程
Icms 插件可以在我们的 文章 上执行 SEO。通过可视化的操作页面,我们可以批量管理我们的文章的标题、段落、关键词。关键词密度控制、段落插入等,让我们的文章 更喜欢原创。同时还可以对我们原创素材中的图片和敏感词进行处理,支持替换或删除敏感词,清除原图水印,替换原图。
4. 网站数据管理
icms插件可以对我们的网站收录进行批量查询和内链抓取,适合我们多站站长同屏管理我们的网站 . cms在插件中,您可以通过生成的数据和曲线,方便的查看和对比我们的数据信息如收录、蜘蛛的数量等,方便我们的网站 管理。
Icms作为基于PHP+Mysql架构的轻量级开源内容管理系统,采用OOP(面向对象)框架。采用MVC框架开发,拥有高效开源的内容管理系统,不断更新维护。这是我们许多新站长cms 的选择。
通过Icms插件,我们可以方便、全面的管理我们的网站,无需来回操作多个插件和网站。在批量管理和挂机操作方面,我们也让我们有更多的时间来分析我们的 SEO 策略。Icms 插件的讲解到此结束。如果喜欢,记得点赞哦。
直观:这篇采集器程序实现爬虫程序实现程序实现原理是写给那些觉得采集难
当您想从某个网站中采集文章时,需要提供文章地址,但是我们不能先复制文章地址再使用软件进行采集它。在网站上,通常有一个列表,这个列表就是文章的地址。这里我以dux主题官网和大前端为例进行说明。
采集大前端设计类别下的所有文章,首先找到类别地址:,在这个类别地址中,我们可以看到有很多文章地址,把所有文章 地址 ,您可以进行下一步的内容采集。在此之前,我们还需要在分类地址中找到每个页面的规则,否则只提供分类的首页地址,我们只能得到大约10篇文章文章的地址(一页文章 数量以)分类)。
点击大前端设计类的第二页,可以看到它的地址是,和第一页不同,但是我们还是可以通过修改下面的页码参数正确访问第一页的内容。页面为1,所以我们可以确定大前端dux主题类别文章列表的地址规则为*
打开机车,新建采集任务,配置分类文章列表的URL规则如下:
各种采集器爬虫程序的实现原理普及
使用【地址参数】替换地址格式中更改的地方,然后选择【地址参数】作为要更改的数字。目前大型前端设计类有9页,我这里填9页。
获取文章地址
获取文章的地址也很简单。在浏览器中使用F12查看文章列表中的文章链接,如下:
各种采集器爬虫程序的实现原理科普文章
这里需要注意一点,我没有使用标签来查找文章的地址,因为在整个页面中,不仅文章的标题会有标签,为了防止地址我们不需要找网站编号怎么样采集,这里使用的条件都是打标签的。机车规则配置如下:
各种采集器爬虫程序的实现原理
在内容 URL 获取下,选择手动设置规则。自动可能找不到我们需要的地址,一般选择手动。那么抽取规则就是上图中红框内的网页结构元素,然后用【参数】和(*)替换我们需要的和我们忽略的,【参数】就是我们需要的,(*)表示match all,比如我们没有必填的文章标题,标题会改变,所以使用match all。
提取规则中[参数]匹配的数据可以从拼接地址中获取,比如我上面匹配的文章地址。在拼接地址中填写【参数1】,获取提取规则中的第一个参数。使用 [参数] 匹配数据。另外,拼接地址可以采用“固定地址[参数1]”的形式进行拼接。例如,提取规则中只取文章的ID,拼接地址填写“[参数1].html”。
测试采集的效果如下:
各种采集器爬虫程序的实现原理
我们每页有10篇文章文章地址成功采集,然后输入内容采集。
内容采集
集合的内容主要包括采集器是什么两个方面,一是文章的标题,二是文章的内容。采集原理是模拟访问文章页面,获取文章页面的所有源码。源代码具有 文章 内容和 HTML 标记。然后从源代码中提取标题和 文章 内容。一般有三种提取方法。第一个比较原创,找到唯一的字段,然后使用字符串截断来提取目标内容。二是使用正则表达式提取,这种方法需要能写正则表达式。第三种比较简单,使用Xpath规则提取,浏览器自带xpath规则,不用自己写,
各种采集器爬虫程序的实现原理
机车配置如下:
各种采集器爬虫程序的实现原理
填好规则后,可以用下面的测试看看提取出来的内容有没有问题。
content采集 规则也是如此,这里不再赘述。
当您采集的内容不需要或需要替换时,您可以使用替换规则对其进行修改。
各种采集器爬虫程序的实现原理普及
其中一些功能是收费的,机车采集器V9无限版的共享采集器是什么,免费工具供大家使用。集合部分就是这样,下一章是关于发布规则的。

