解决方案:智能采集组合文章的*敏*感*词*网页采集软件-专业的web1
优采云 发布时间: 2022-10-16 23:10解决方案:智能采集组合文章的*敏*感*词*网页采集软件-专业的web1
智能采集组合文章的*敏*感*词*网页采集软件-专业的web1.0站点的文章采集器最近对采集软件的需求程度越来越高,也因为工作的缘故,我搜索了很多爬虫大佬的需求,比如5118、小猪爬虫、nodejs篇的教程和软件。这次小米爬虫公众号粉丝二、三十万了,这种高规模的公众号粉丝,除了公众号开通原创权限和自媒体平台的大号,甚至给他们做图文是要放长线。
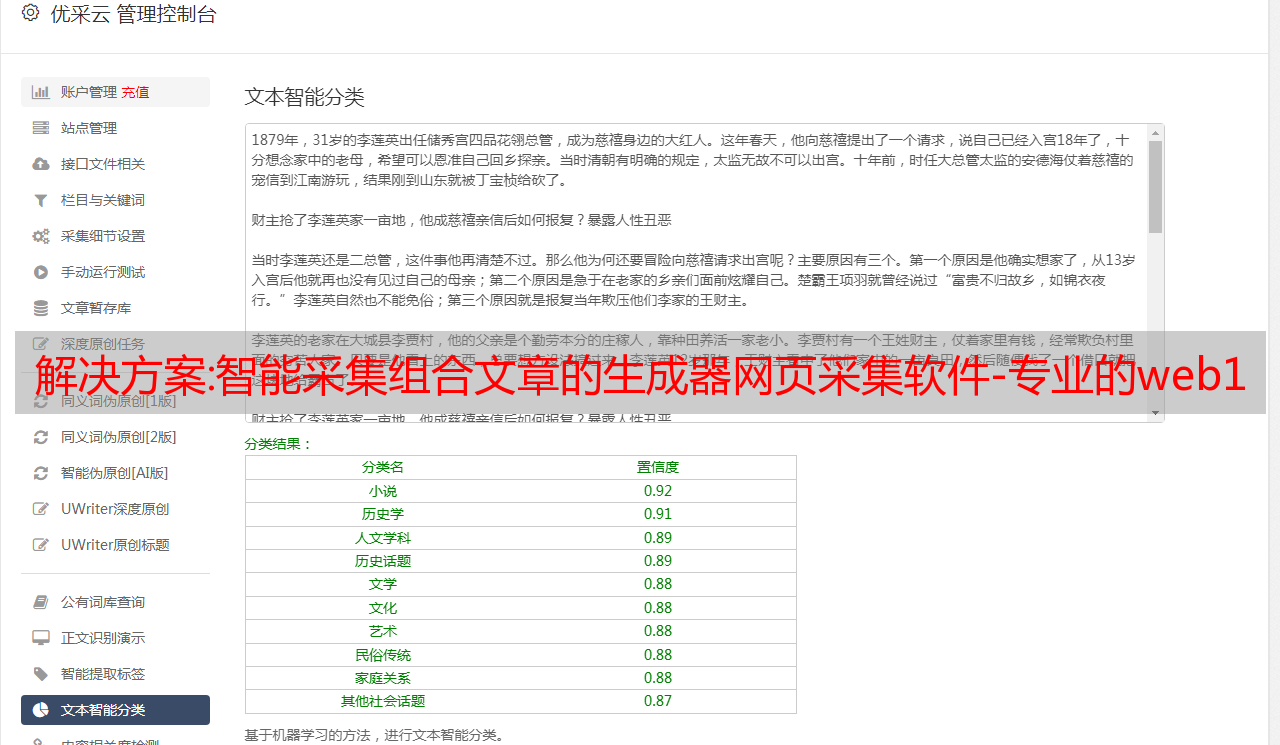
所以趁此机会,试用下我们的小米爬虫软件。软件是我们的开发在杭州太仓的产品团队和众多优秀的小米爬虫技术的高校专家一起研发的。什么是小米爬虫爬虫是指利用人工智能,自动发现某些平台上海量有效的内容,进行重复性、篇章性和数量性采集,为用户提供海量、高质量的内容服务的系统。在互联网发展的今天,我们依然要持续分析流量和总结规律,在快速更新的互联网爬虫库中寻找优质内容,对广告文章进行筛选和公众号文章采集。
作为一名初级爬虫,除了熟悉javascript语言,常见的数据格式是sql语言和html语言,目前还不会python,因此只能研究javascript,首先,先了解下我们要用到的requests库,这个库作为最常用的http库,爬虫初期主要使用。网络抓取——开始对网页进行抓取爬虫初期,对网页抓取是每天的工作,遇到限制需要爬取的网页,会开启抓包软件,比如我的浏览器自带的开发者模式,有限制抓取的网页我会手动保存到自己电脑上,当然也有直接抓包抓取,每个网站都有不同的限制方式,这就是我们需要找到的信息来源。
但是,我们爬虫中有一个和浏览器平台(大站点)有关的抓取代理,就是我们找到需要抓取的代理,但是每个人都有自己的代理,如何发现自己的代理呢?首先我们先发现源代码网址,然后去翻页,如果页数比较多,我们可以每次爬取一页,这样爬取效率就比较高。爬取下来后我们开始一一对比信息,但是后面会发现很多的不确定性,比如爬取的多位用户名,我们需要获取ip地址,这种网站如果用nodejs的web服务器,没有开发者工具打开,我们只能通过手工进行抓取。
爬取下来的内容可能会有错误,比如位置或者域名变更。我们并不是很清楚自己的代理是否每个人都有,所以需要一个匹配的代理池,这个还是很有必要的。最近爬取到第一十九万篇文章,对互联网采集初期的工作就算是告一段落了。接下来还会有抓取更多的互联网平台,比如贴吧,豆瓣,百度,搜狐等。爬虫实战——用过各个平台采集出来的信息复盘首先我们拿到第一十九万篇文章,抓包并抓取每篇文章的源代码:然后拿到代码,我们很快进行分析爬取,并且利用大白话讲了我们刚刚学习爬。

