干货:伪原创文章怎么弄 伪原创文章写法
优采云 发布时间: 2022-10-16 22:11干货:伪原创文章怎么弄 伪原创文章写法
伪原创文章你怎么知道的?只需直接使用老铁智能伪原创工具,这将使您的文章更加原创。文章伪原创非常快。只需几秒钟即可获得伪原创文章。如果你需要它,不要错过它!如果您需要下载软件和游戏,请来6z6z下载。
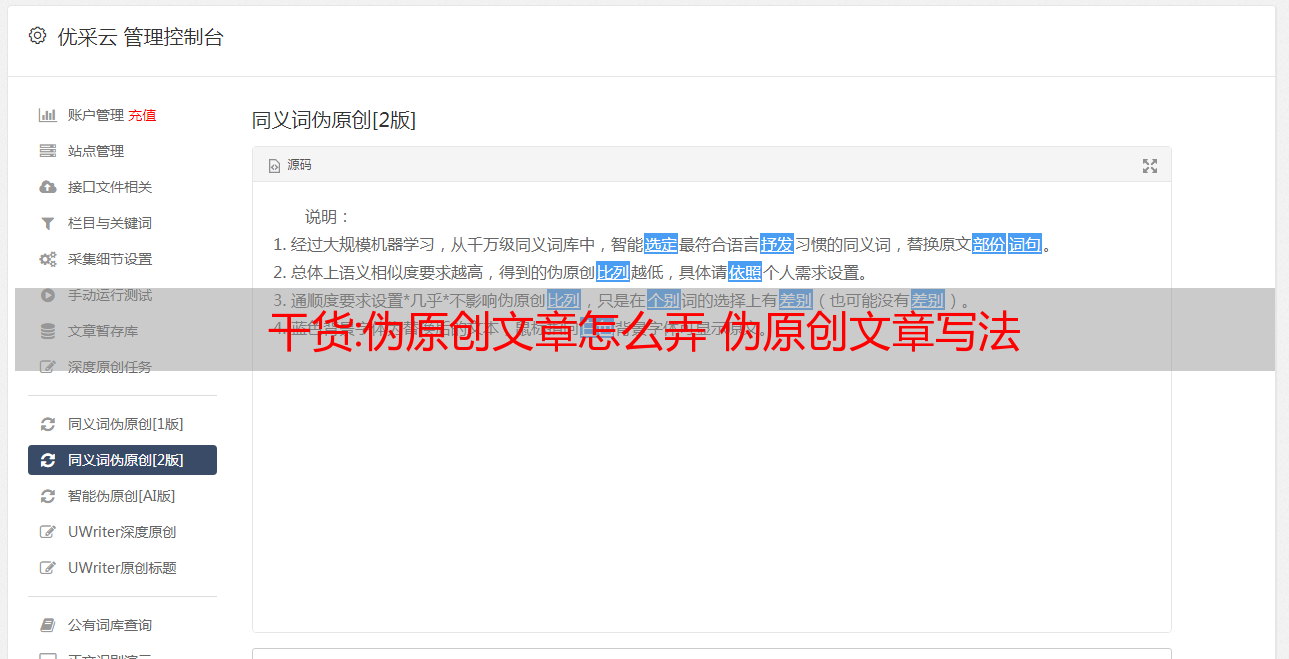
Laotie智能伪原创工具将使您的文章更原创,更流畅,并快速获得久违的网站排名。魔术伪原创工具功能:这款原创引擎工具是一个SEO工具,可以快速,专业地修改和处理在互联网上复制文章,并立即生成带有图形文章。
使用效果:文章更新频率快,100%原创,搜索引擎蜘蛛,不仅抓取文章内容,还抓取我们的图片,重量迅速增加。生成的文章与门户网站相同,每个文章都有相关的图片,并且在正确的位置,插入适当的关键词,句子流畅,所有搜索引擎反作弊算法都在几秒钟内被杀死。
更新说明: 1. 修复图片链接收录中文句点的问题。2. 修复了部分FTP无法正常上传的问题。3. 添加了开机自检数据包格式化。4.修改未填写标题而返回不完整内容的问题。5. 优化发布模块,解决发布编码问题。6. 添加了采集设置。可插入图像百度更注重用户体验,派生搜索结果缩略图和强大的图像引擎。因此文章插图和文字是王道。
技术贴:独立站SEO的发外链之踩坑日记(实战翻车)
该书从上面继续,说使用Python上传了100,000个产品,导致woocommerce程序崩溃,核心代码在下面发送:
核心库简介:
import pymysql
import time
from woocommerce import API
获取 API,当然,API 首先要求您生成它,网站:
wcapi = API(
url="http://你的网站",
consumer_key="key",
consumer_secret="key",
version="wc/v3",
timeout=500
)
数据处理和上传:
data = do_data(item)
itemttt = wcapi.post("products", data).json()
自定义数据处理功能:
def do_data(item):
data = {}
data["name"] = item[0] + "题目增加信息"
data["type"] = "simple"
<p>
data["regular_price"]: "100"
data["description"] = ''+ item[0] +''
data["regular_price"] = "99"
data["short_description"] = item[0] + "描述"
data["categories"] = [
{
"id": 26 #修改三
}
]
data1 = {}
testlist = []
data1["src"] = "图片地址"+item[2]#修改2
testlist.append(data1)
data["images"] = testlist</p>
Woocommerce程序在达到100,000时崩溃,但商店可以有100,000件商品吗?即使达到100,000(关键词到100,000),谷歌收录能走多少钱?我的商店倒闭了,所以我没有机会观察谷歌的收录。
现在只有一个选择:使用蟒蛇直接连接到WordPress的mysql进行POST炒作。当然,你需要模拟WordPress的POST操作来上传数据库,核心代码不会粘贴在这里,这是Python对mysql的炒作。
几天后,超过10万个页面上传并提交给谷歌,谷歌在新网站的完整收录在大约一个月内完成;但它是按比例进行的,虽然前十天收录相对较慢,但半个月后会达到峰值。我的100,000级网站10个天才收录一千页?你是什么意思?
人们把丑陋的钱来弥补,关键词我有,但是没有外部链接,那就写一个脚本并发送外部链接。首先想到的平台是推特,脸书,
我们先用Twitter练习吧,不过毕竟第一次发外链接,我也知道推特在互联网上的状态,反爬虫和反垃圾邮件的手段都是一流的(这是后记),但是不要试试,你从哪里知道水的深度呢?在剧作家身上,等等,发送反向链接需要文章标题和相应的链接,我去WordPress的mysql看了看,到底是什么,mysql的显示链接根本就不对应标题,因为WordPress可以选择几种网页连接形式,带有id,日期等等。
这是怎么回事?使用自动化发送反向链接肯定需要网页标题和相应的链接,只有一种方法:使用crafiy来抓取自己的网站?哦,真是个笑话,我显然可以控制数据库并编写爬虫来抓取它。似乎WordPress真的不适合我了,它只是一个黑匣子
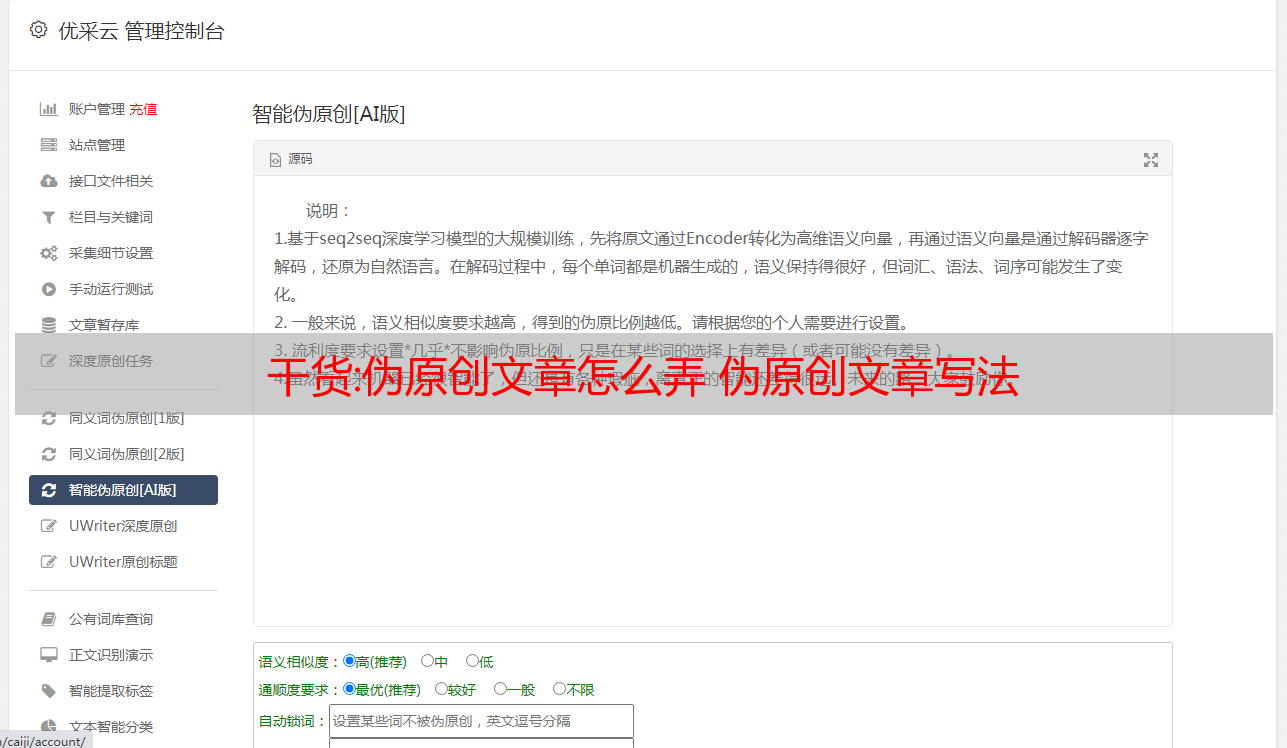
侦探看了一眼,幸好数据量非常小,爬虫在一小时内调整,爬虫在两个小时内爬行,标题和相应的链接都保存在mysql和剧作家中。
browser = playwright.chromium.launch()
context = browser.new_context()
cookies = “你的cookies”
context.add_cookies(cookies)
page = context.new_page()
# Go to https://twitter.com/home
page.goto("https://twitter.com/home",timeout=30000)
post_data1 = """if you need the {},you can go to {}\n""".format(data_s[1], data_s[0])
page.locator("[data-testid=\"tweetTextarea_0\"] div").nth(2).click(timeout=30000)
page.locator("[data-testid=\"tweetTextarea_0\"] div").nth(2).type(post_data1,timeout=30000)
page.locator("[data-testid=\"tweetButtonInline\"]").click(timeout=30000)
sleep_time = random.randint(20, 40)
time.sleep(sleep_time)
每个数据间隔是20~40秒,因为我知道Twitter有高压线,但不知道高压线在哪里。当它达到900左右时,Playwright报告了一个错误,当我登录时,我意识到Twitter已经阻止了我的垃圾邮件帐户。
但作为一个脚本孩子,你怎么能承认推翻,做不到推特呢?硬柿子不能捏,还没有软柿子吗?
每篇文章文章5个主题加上相应的链接,首先对2000篇文章文章,总共有10000个链接来体验。
发布后,等待谷歌收录。

