最新版本:在线文章采集软件(在线文章采集软件下载)
优采云 发布时间: 2022-10-16 19:11目录:
1.文章采集软件免费版
易于使用的文章采集器,我们不需要输入采集规则来进行全网采集,文章为文章 我们对 采集器 感兴趣,有 关键词文章采集 和可视化名称 网站文章采集,这很有用,因为我们不需要输入很多命令,只需点击鼠标即可完成文章采集的工作。
2. 网站文章采集器
3. 文章采集生成原创软件
关键词采集我们需要输入我们的核心关键词,选择我们需要的相关平台如自媒体采集,就可以完成采集任务设置,关键词采集器通过关键词自动匹配大量实时热点文章,为我们提供大量文章创作材料。
4. 热门文章采集器
视觉指定采集,对我们网页感兴趣的可以点击鼠标完成指定采集设置,支持英文网站采集等外语,并且内置翻译功能,导出到本地或者发布给我们cms是一键翻译,支持段落标签保留。
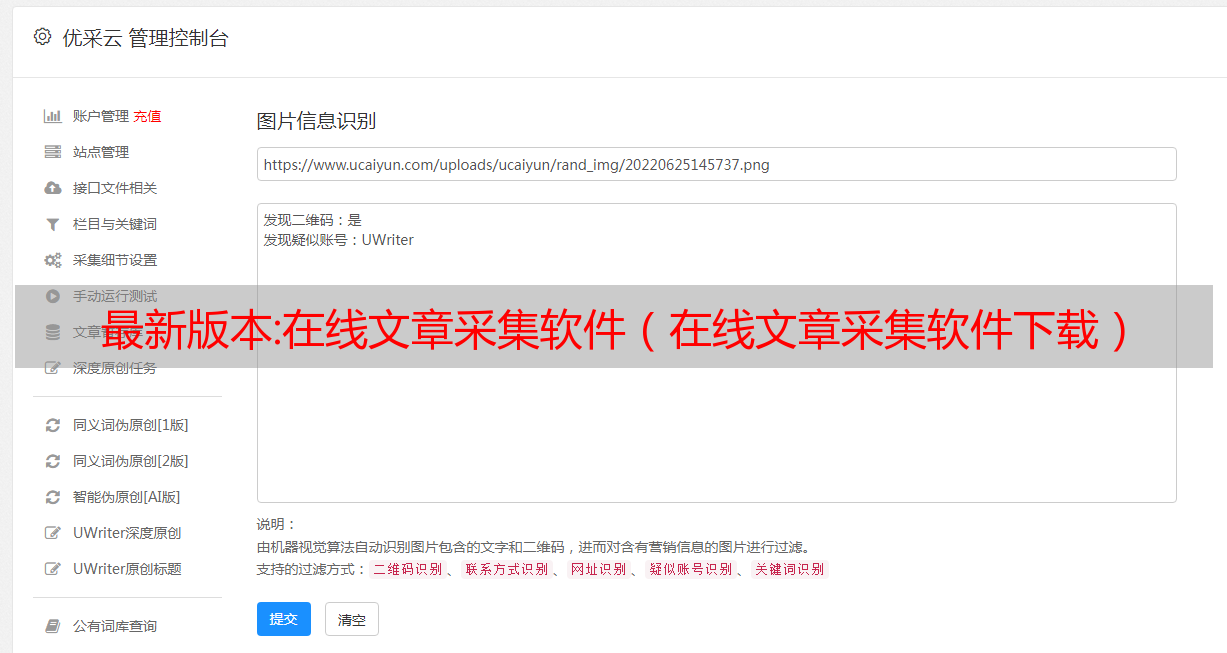
5. 图形采集软件
通过指定采集的监控页面功能,我们可以监控固定页面采集,应用于实时更新的网站内容采集,也可以评论论坛采集,让我们实时关注舆论动向,调整我的论坛节奏。
6.微信文章采集软件
网站优化离不开我们的原创美容和搜索引擎优化(SEO),什么是原创内容,对于搜索引擎来说,可以为用户提供解决方案,不能确定是抄袭文章就是原创,所以伪原创如果它可以提升用户体验,也是一种原创如果我们希望我们的SEO策略有效并且我们的受众信任我们,而且它也很容易实现。
7.通用文章采集器Android
继续阅读以发现在为任何在线渠道创建新的 文章 时要实施的一些最佳实践
8. 网站信息采集软件免费
仔细检查和校对我们的内容,在新内容上点击“发布”之前要做的第一个动作当然是审查它记住,事实上,原创也包括自我原创——(经常)不小心复制并发表自己以前的作品,但声称是 原创
9. 网站文章自动采集发布
因此,请确保我们投入足够的时间来执行所有必要的检查,以保护我们的内容免受任何复制或自我复制问题 检查内容的可读性、语法、结构和关键字是否听起来重复或非原创,请在公开之前标记它并确保了解我们 文章 的底部。
10.采集文章的软件
如何始终如一地创建我们的 原创 内容,如果我们正在为在线商店编写产品描述,这可能会特别棘手。在这些情况下,很容易将完全相同的内容用于仅颜色不同或适合项目的东西但是, 尝试在每个描述中保留 原创 至关重要。
要有创意,为每件单品添加一些独特的东西,无论是谈论特定颜色可能适合什么心情,还是我们如何佩戴该物品
文章采集器的分享就到这里了。什么样的文章采集器好用?当然是基于用户体验,降低用户学习成本。强大的采集器,如果你喜欢这个文章,不妨采集并连续点赞3次。
最新版:python爬虫之selenium库,浏览器访问搜索页面并提取信息
一、硒简介
如果链接简单,爬虫可以使用requests库通过链接提取页面信息,比如抓取豆瓣top250视频信息,链接简单易懂。参考:爬取豆瓣top250视频资料
但是如果遇到一些搜索等基于js动态加载的网页,上面就不适合了,比如爬虫b站,搜索“爬虫”页面,第一页链接如下,第二页是一个很长而不规则的链接。使用请求库难以提取页面。
https://search.bilibili.com/all?keyword=%E7%88%AC%E8%99%AB&from_source=webtop_search&spm_id_from=333.1007&search_source=5
针对上述情况,我们可以直接通过浏览器访问各个页面,然后提取页面。当然,让爬虫自己打开浏览器,输入要访问的内容,然后提取页面元素。此过程将使用 selenium 库。
Selenium 实际上是一个支持各种主流浏览器的自动化测试工具。遇到python,selenium就变成了爬虫的利器。
二、安装selenium 配置环境变量 1、安装
pip install selenium
下载浏览器驱动,我用的是Chrome浏览器,所以只下载Chrome驱动,当然也可以下载其他浏览器驱动。下载链接:ChromeDriver,找到与您的浏览器相同或最接近的版本。
2.配置环境变量
下载解压后,配置环境变量。
解压,然后创建一个存放浏览器驱动的目录,例如: D:\Python\Driver ,将下载的浏览器驱动文件(例如:chromedriver、geckodriver)放到这个目录下,这里是chromedriver。
我的电脑 -> 属性 -> 系统设置 -> 高级 -> 环境变量 -> 系统变量 -> 路径,将“D:\Python\Driver”目录添加到Path的值中。例如:路径字段;D:\Python\驱动程序
关于环境变量不生效的问题:
1:尝试驱动浏览器,直接放到python安装目录下。
2:配置好环境变量后,重启电脑生效(我只是重启生效)
三、打开浏览器自动搜索 1、浏览器自动访问
代码,打开浏览器,访问。
#导入 web 驱动模块
from selenium import webdriver
#创建了一个 Chrome 驱动
driver = webdriver.Chrome()
#驱动访问网页
driver.get("https://www.bilibili.com/")
#代码完成后,关闭浏览器
#driver.quit()
以上,执行代码自动打开浏览器
2.输入关键字并搜索
分析代码可以看到搜索框和按钮键的类元素值为nav-search-input和nav-search-btn
找到元素后,使用 find_element 方法定位元素。有很多方法可以找到它。
id定位:find_element_by_id()
name定位:find_element_by_name()
class定位:find_element_by_class_name()
link定位:find_element_by_link_text()
partial link定位:find_element_by_partial_link_text()
tag定位:find_element_by_tag_name()
xpath定位:find_element_by_xpath()
css定位:find_element_by_css_selector()
上面也可以使用 driver.find_elements(By.ID, 'xxx') 来对应值。
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
我可以使用类值来定位这里。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.bilibili.com/")
#找到元素值
input = driver.find_element(By.CLASS_NAME,'nav-search-input')
button = driver.find_element(By.CLASS_NAME,'nav-search-btn')
#输入关键词
input.send_keys('爬虫')
#点击按钮
button.click()
注意:如果上面的错误信息提示没有By类型,需要从mon.by导入包 import By
执行效果:
以上基本搜索动作就完成了。
四、切换窗口提取网页信息
现在您已经有了一个网页,您可以使用之前学习的 BeautifulSoup 库来提取页面代码元素。
1.切换窗口
由于搜索页面是重新打开一个页面,所以还需要在代码中进行切换,否则默认为第一页。
window_handles:获取页面句柄,返回值是一个list列表。
switch_to.window:切换页面。
#获取所有页面句柄
windows = drive.window_handles
#切换页面为最后一个句柄,也是最后一个页面
drive.switch_to.window(windows[-1])
#print(windows)
上面得到的 print(windows) 句柄值为:
['CDwindow-EED0C1AE55C6A49DE55D69130254EC0F', 'CDwindow-D04BF7FFBEA89EFB93A990733008FD92']
2.获取页面源代码提取元素
切换页面后,使用 page_source 获取页面源代码。
获取源代码后,可以提取元素并找到对应的类值。这里提取的值是,视频名称,up main,播放音量,时长,链接,日期。
最终代码是:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
driver.get("https://www.bilibili.com/")
input = driver.find_element(By.CLASS_NAME,'nav-search-input')
button = driver.find_element(By.CLASS_NAME,'nav-search-btn')
input.send_keys('爬虫')
button.click()
windows = driver.window_handles
#print(windows)
driver.switch_to.window(windows[-1])
#等待5秒
time.sleep(5)
#获取源代码
html=driver.page_source
soup = BeautifulSoup(html,'lxml')
list = soup.find(class_='video-list row').find_all(class_="bili-video-card")
for item in list:
#print(item)
video_name = item.find(class_='bili-video-card__info--tit').text
video_up = item.find(class_='bili-video-card__info--author').string
video_date = item.find(class_='bili-video-card__info--date').string
<p>
video_play = item.find(class_='bili-video-card__stats--item').text
video_times = item.find(class_='bili-video-card__stats__duration').string
video_link = item.find('a')['href'].replace('//','')
print(video_name,video_up,video_play,video_times,video_link,video_date)
driver.quit()
</p>
执行结果为:
【爬虫1000集】目前B站最完整的爬虫教程,包含所有干货内容!这还没人看,我不更了! python大讲堂呀 24.6万 29:14:25 www.bilibili.com/video/BV1bL4y1V7q1 · 4-25
2020年Python爬虫全套课程(学完可做项目) 路飞学城IT 150.8万 43:30:57 www.bilibili.com/video/BV1Yh411o7Sz · 2020-7-9
Python超强爬虫8天速成(完整版)爬取各种网站数据实战案例 Python网红Alex 51.6万 20:39:05 www.bilibili.com/video/BV1ha4y1H7sx · 2020-12-7
Python爬虫实战教程:批量爬取某网站图片 python学习者 80.5万 09:31:34 www.bilibili.com/video/BV1qJ411S7F6 · 2019-11-13
【附源码】全网最新的Python爬虫教程+实战项目案例,超适合小白练手的实战项目!(最新录制) Python王子秦老师 3.6万 41:15 www.bilibili.com/video/BV1gd4y1i75v · 10-8
Python课程天花板,Python入门+Python爬虫+Python数据分析5天项目实操/Python基础.Python教程 IT私塾 400.8万 20:24:40 www.bilibili.com/video/BV12E411A7ZQ · 2020-3-20
尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例) 尚硅谷 55.8万 22:19:04 www.bilibili.com/video/BV1Db4y1m7Ho · 2021-9-1
2022年Python爬虫小白到大神-网络爬虫+反爬虫(爬取各种网站数据)完整版包含20个项目案例,学完可自己爬取! Python人生苦短 6.1万 14:40:56 www.bilibili.com/video/BV1rv4y1K7yV · 5-4
Python超强爬虫5天速成(完整版)爬取各种网站数据实战案例 Python网红Alex 7300 18:53:17 www.bilibili.com/video/BV1BD4y1k7Po · 10-9
【Python爬虫】清华大学20小时讲完的Python爬虫项目实战,全程干货无废话!建议收藏~ H顾兮儿 424 55:46:15 www.bilibili.com/video/BV1QN4y1A7oc · 10-10
【2022最新】32个Python实战项目,练完即可就业,从入门到进阶,基础到框架,你想要的全都有,建议码住,允许白嫖!实战_项目_练手_小白_爬虫_编程_科技 张妹儿丫 113 40:44:18 www.bilibili.com/video/BV1PR4y1R7Xc · 13小时前
写爬虫真的会坐牢吗? 知安局 60.5万 12:06 www.bilibili.com/video/BV1KK4y1s7iK · 2021-1-22
【全套34课时】2022最新完整版Python爬虫入门教程+实战项目案例,网络爬虫教程,零基础小白可学,学完可做项目*敏*感*词* Python精选教程 811 19:43:13 www.bilibili.com/video/BV1D8411x7Kx · 10-10
3小时搞定 Python爬虫项目(爬取数据+数据整理+数据可视化) Python牛牛牛 6.6万 29:32:59 www.bilibili.com/video/BV1hS4y1b7EJ · 5-14
2021年最新Python爬虫教程+实战项目案例(最新录制) 路飞学城IT 68万 14:40:22 www.bilibili.com/video/BV1i54y1h75W · 2021-3-5
【Python爬虫教程】花9888买的Python爬虫全套教程2021完整版现分享给大家!(已更新项目)——附赠课程与资料 小猿Python的主页 49.2万 40:10:11 www.bilibili.com/video/BV1ZT4y1d7JM · 2021-10-8
月薪1w的程序员 爬淘宝被判3年 写爬虫别碰这3条! 麦叔编程 20.1万 07:56 www.bilibili.com/video/BV1ih411a7PK · 2021-6-14
Python爬虫开发实战从入门到精通大神崔庆才零基础视频52讲全 T博士云课堂 1.9万 12:15:35 www.bilibili.com/video/BV1pf4y1H72c · 2021-8-29
卧槽!原来Python爬虫可以这么玩?学完这10个练手案例,说明你才是真的入门了!!! 图灵python 7764 39:20 www.bilibili.com/video/BV1Jd4y1i7cH · 10-9
3小时搞定 Python爬虫项目(爬取数据+数据整理+数据可视化) 路飞IT学城 5.5万 02:16:47 www.bilibili.com/video/BV1Ry4y1V7PE · 2021-8-18
【爬虫篇】《极客Python之效率革命》 鱼C-小甲鱼 18.4万 01:47:55 www.bilibili.com/video/BV1wp411o7dz · 2018-5-20
黑马程序员Python爬虫基础,快速入门Scrapy爬虫框架 黑马程序员 27.9万 04:17:09 www.bilibili.com/video/BV1jx411b7E3 · 2017-8-22
爬虫一小时,完事一分钟【第二弹】 苦瓜不可以 9.7万 05:18 www.bilibili.com/video/BV1Hr4y1w71G · 2020-11-10
【十大案例 源码完整】后悔没早学Python爬虫,省时又省力⚡凭实力摸鱼丨全网图片、视频、数据...一键获取! 彭有才Python 1.1万 02:52:35 www.bilibili.com/video/BV14T411P7TD · 10-8
Python爬虫编程基础7天速成(2022全新合集)Python入门+数据分析,0基础小白的入门级别教科书! 图灵学院教程 4.7万 51:00:54 www.bilibili.com/video/BV1Fa411q75C · 4-11
【爬虫1000集】目前B站最完整的爬虫教程,包含所有干货内容!这还没人看,我不更了! Python万能胶 14.7万 14:40:56 www.bilibili.com/video/BV1qB4y1D77o · 6-4
2022最新Python爬虫教程小白零基础速通(涵盖所有核心知识)立刻收藏! 图灵学院教程 2.6万 17:38:51 www.bilibili.com/video/BV133411F7Cp · 7-20
【python爬虫1000集】目前B站最完整的爬虫教程,包含所有干货内容!这还没人看,我不更了! 数据分析女王 73 14:40:56 www.bilibili.com/video/BV11N4y1A7cj · 14小时前
【敢称全站第一】B站最强的Python爬虫进阶教程!自学必看,帮你少走99.9%的弯路~学不会你找我(爬虫JS逆向/逆向算法/逆向混淆/APP逆向/爬虫实战) 彭有才Python 2.3万 07:49:30 www.bilibili.com/video/BV1sG411n7Zf · 7-18
2022自学爬虫,这一套就够了,别再乱学其他。 眨塑炊俺未沼臻 3.2万 15:45:05 www.bilibili.com/video/BV1JP4y1u72J · 3-18
Python爬虫全套教程,*敏*感*词*教学 ,学完即可接单!!! Python善善 2.1万 04:10:56 www.bilibili.com/video/BV13e4y197vg · 7-22
终于拿到了!(完整版)Python超强爬虫7天速成爬取各种网站数据 【python3.8爬虫基础+实战】 编程界-小蜗牛 3.2万 23:57:57 www.bilibili.com/video/BV1rL411G7ep · 2021-10-20
代码总是学完就忘记?100个爬虫实战项目!让你沉迷学习丨学以致用丨下一个Python大神就是你! python基础入门 8.4万 71:15:41 www.bilibili.com/video/BV1SA4y1976A · 4-14
(正版独家)Python教程巅峰之作,听觉上的享受(Python入门,Python爬虫,数据分析) IT私塾 22.2万 31:25:34 www.bilibili.com/video/BV1yY4y1w7r8 · 8-5
Python爬虫实战教程:爬虫爬取某APP批量图片,脸红。 天美不会建模啊 3.5万 39:07 www.bilibili.com/video/BV18v411q76u · 2020-7-22
2022自学爬虫全套,学完可接项目(无私分享) 小北不熬夜啊啊 3.8万 13:43:02 www.bilibili.com/video/BV1iu411C79S · 4-16
Python爬虫从基础到精通,企业级讲解,集集干货,*敏*感*词*带项目案例实战 图灵Python何老师 2.5万 45:20:00 www.bilibili.com/video/BV1Yi4y1S7Pi · 4-8
一单最少50块,学完爬虫就能实现,2021年最新python爬虫教程,从入门到实践,通俗易懂(完结) 左上角的猫 2.2万 14:23:31 www.bilibili.com/video/BV1Pg411V768 · 2021-9-1
【Python教程】从入门到精通Python网络爬虫,核心技术、框架与项目实战,适合入门学习(小白定制版) 图灵学院教程 2.9万 39:08:57 www.bilibili.com/video/BV1R34y1h7jx · 5-16
【Python爬虫教程】爬虫写得好,牢饭吃的饱!Python 爬虫零基础入门到实战系列!(附课件源码资料) 人工智能与Python 11.7万 27:51:01 www.bilibili.com/video/BV1Hb4y167c9 · 2021-7-20
10天学完Python爬虫全套教程,现在分享给大家(B站最新) Python_子木 12.2万 24:57:21 www.bilibili.com/video/BV16f4y197D6 · 2020-8-11
【最强攻略】用魔法打败魔法,Python爬虫轻松通关羊了个羊!!! 咩咩数据分析大全 1.6万 19:41:57 www.bilibili.com/video/BV17D4y1i7nX · 9-20
这样就完成了单页的所有视频信息提取。
5.判断页面是否加载
对于上面的代码,切换页面后,有一段代码等待5秒。
time.sleep(5)
如果不加这行,有时会无法获取完整的信息,会报错。因为代码元素还没有加载,代码会被执行,导致无法获取元素值,会报错,所以必须加一个等待时间。错误如下:
Traceback (most recent call last):
File "D:\Python\test_selenium.py", line 42, in
video_name = item.find(class_='bili-video-card__info--tit').text
AttributeError: 'NoneType' object has no attribute 'text'
time.sleep(5) 也可以用于临时调试,但在实际环境中,尽量少用,因为实际环境和网络不同,5秒内可能加载不出来,会报错。所以需要一种灵活的方式,有三种等待方式。
1. 被迫等待
sleep(x) x 在 s 中,sleep 等待元素。
无论您的浏览器是否加载,程序都必须等待。时间到了,继续执行下面的代码,对调试很有用。
隐式等待和显式等待可以同时使用。
注:最长等待时间为两者中的较大者
2. 隐式等待
隐式等待是页面,implicitly_wait(x) x 单位是s。
一旦设置,这种隐式等待将在 WebDriver 对象实例的整个生命周期中起作用。它不针对某个元素,它是全局元素等待,即定位一个元素时,需要等待页面的所有元素都加载完毕,然后再执行下一个。陈述。
如果超过设置的时间,则抛出异常。
缺点:当页面有些js无法加载,但是它要找的元素已经出来了,会一直等到页面加载完毕(浏览器标签左上角的圆圈不再旋转),然后执行下一句。在某些情况下,会影响脚本执行速度
3.显式等待
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
该模块需要通过 from selenium.webdriver.support.wait import WebDriverWait 导入
配合这个类的 until() 和 until_not() 方法
程序每隔 poll_frequency 秒看一次,如果条件为真,则执行下一步,否则继续等待,直到超过设置的最大时间,然后抛出 TimeoutException。
WebDriverWait与expected_conditions结合使用,例如:
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
wait = WebDriverWait(driver,10,0.5)
element =wait.until(EC.presence_of_element_located((By.ID,"kw"),message="")
# 注意,如果省略message=“”,则By.ID外面是两层()
expected_conditions类提供的期望条件判断方法:
以下两个条件类验证title,验证传入的参数title是否等于或包含于driver.title
title_is
title_contains
以下两个条件验证元素是否出现,传入的参数都是元组类型的locator,如(By.ID, ‘kw’)
顾名思义,一个只要一个符合条件的元素加载出来就通过;另一个必须所有符合条件的元素都加载出来才行
presence_of_element_located
presence_of_all_elements_located
以下两个条件判断某段文本是否出现在某元素中,一个判断元素的text,一个判断元素的value
text_to_be_present_in_element
text_to_be_present_in_element_value
以下条件判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
以下条件判断是否有alert出现
alert_is_present
以下条件判断元素是否可点击,传入locator
element_to_be_clickable
以下四个条件判断元素是否被选中,第一个条件传入WebElement对象,第二个传入locator元组
第三个传入WebElement对象以及状态,相等返回True,否则返回False
第四个传入locator以及状态,相等返回True,否则返回False
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
最后一个条件判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
4.更改代码等待方式
3处等待,输入关键词,点击按钮,切换页面。
输入搜索框,然后确认。
wait=WebDriverWait(driver,10)
#等待定位元素值,并返回元素值
input = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'nav-search-input')))
#等待定位元素值,并等待是否可点击
button = wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'nav-search-btn')))
<p>
</p>
调整页面等待,By.CLASS_NAME定位一个class值,不是很准确,所以这里使用By.CSS_SELECTOR定位。
如果对 CSS_SELECTOR 规则不熟悉,可以直接查看源码并复制。当然,它不必是最低元素值。我可以去 div.video.i_wrapper.search-all-list 这里。
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#i_cecream > div > div:nth-child(2) > div.search-content > div > div > div.video.i_wrapper.search-all-list')))
最终代码是:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://www.bilibili.com/")
wait=WebDriverWait(driver,10)
#input = driver.find_element(By.CLASS_NAME,'nav-search-input')
#button = driver.find_element(By.CLASS_NAME,'nav-search-btn')
input = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'nav-search-input')))
button = wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'nav-search-btn')))
input.send_keys('爬虫')
button.click()
windows = driver.window_handles
driver.switch_to.window(windows[-1])
#time.sleep(5)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#i_cecream > div > div:nth-child(2) > div.search-content > div > div > div.video.i_wrapper.search-all-list')))
html=driver.page_source
soup = BeautifulSoup(html,'lxml')
list = soup.find(class_='video-list row').find_all(class_="bili-video-card")
for item in list:
#print(item)
video_name = item.find(class_='bili-video-card__info--tit').text
video_up = item.find(class_='bili-video-card__info--author').string
video_date = item.find(class_='bili-video-card__info--date').string
video_play = item.find(class_='bili-video-card__stats--item').text
video_times = item.find(class_='bili-video-card__stats__duration').string
video_link = item.find('a')['href'].replace('//','')
print(video_name,video_up,video_play,video_times,video_link,video_date+'\n')
driver.quit()
6.隐藏浏览器不运行界面
如果长时间运行,不可能一直打开浏览器。这时候就需要使用无UI的浏览器,或者隐藏浏览器无界面运行。
方法一:PhantomJS浏览器
PhantomJS是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是一个浏览器,但是里面的点击、翻页等与人相关的操作需要编程。
注意:最新版本的selenium(4.xx)已经放弃PhantomJS,会报错AttributeError: module 'selenium.webdriver' has no attribute 'PhantomJS'
要使用此浏览器,您需要卸载最新的 selenium 并安装 3.8.0 或以下版本。
pip uninstall selenium
pip install selenium==3.8.0
phantomjs下载地址: ,与安装chrome驱动一致,解压,配置环境变量。
安装完成后,将代码中的webdriver.Chrome()改为webdriver.PhantomJS()。
#driver = webdriver.Chrome()
driver = webdriver.PhantomJS()
方法二:配置选项无头模式
通过配置选项的无头属性。无头模式有可能被检测到并易于发现。
headless 属性配置 ChromeDriver 以使用 Selenium 以无头模式启动 google-chrome 浏览器。然后将参数传递给 webdriver.Chrome。
option = webdriver.ChromeOptions()
option.add_argument('--headless') # 设置option
driver = webdriver.Chrome(options=option)
方法三:在虚拟显示器上工作
推荐使用此方法在服务器上执行。建议在 Linux 服务器上执行此方法。因为windows容易出错,而且windows不支持某些包。
如报错:ModuleNotFoundError: No module named 'fcntl',原因是fcntl包不支持在window上运行。
1:Linux安装chrome并下载chromedriver驱动
Linux 安装 chrome
#下载64位
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
#安装
sudo dpkg -i google-chrome-stable_current_amd64.deb
sudo apt-get -f install
安装完成后查看chrome版本
ubuntu@ubuntu:~$ google-chrome --version
Google Chrome 106.0.5249.119
下载适用于Linux的chromedriver驱动,根据chrome版本在官网下载对应的驱动版本。
#下载
wget https://chromedriver.storage.googleapis.com/106.0.5249.61/chromedriver_linux64.zip
#解压
unzip chromedriver_linux64.zip
#复制到/usr/bin/
sudo cp chromedriver /usr/bin/
2:虚拟显示执行
在使用虚拟桌面之前,服务器需要安装 xvfb 以支持虚拟桌面
sudo apt install xvfb
安装包pyvirtualdisplay
pip3 install pyvirtualdisplay
输入包名,开启虚拟显示。
from pyvirtualdisplay import Display
display = Display(visible=0,size=(800,600))
display.start()
....
....
display.stop()
或者使用另一个包 xvfbwrapper,您也可以使用虚拟桌面。
安装包
pip3 install xvfbwrapper
倒入
from xvfbwrapper import Xvfb
display = Xvfb(width=1280, height=740)
display.start()
....
....
display.stop()
以上基本完成。

