超强:防采集组合拳
优采云 发布时间: 2022-10-16 02:12超强:防采集组合拳
查看更多演示作品↑更多使用说明及支付方式请参考作者介绍
至强措施防止采集,搜索引擎友好
在这个世界上,有矛就有盾,有采集就有反采集。我几个月或几年积累的网站,在没有任何保护措施的情况下,很容易被其他人使用采集工具文章拾取。但归根结底,采集 工具也有弱点。批量采集需要获取大量文章链接。最有效的对策是增加文章链接的获取难度。,加上一点文章内容采集限制,基本属于地狱级。
获取网站的大量文章链接主要有两种方式:一种是批量生成正则的文章URL,另一种是通过列表分页批量提取. 对于第一种情况,Z-Blog默认会将文章动态链接301转为伪静态地址(这样采集太方便了),目前插件提供的第一个功能就是取消这个重定向。文章地址本身就很规律,怎么办?新站点可以更改伪静态规则,但旧站点似乎不应该随便移动。这时候就要用到“文章内容JS动态输出”功能,这会导致大部分采集工具孤单;这是第二种情况。无论您的 文章 链接多么复杂,只要列表是分页的,采集 工具总是可以使用选择器或常规提取。这时候,程序化禁用翻页才是王道!特别感谢建云用户的赞助!
插件功能↓
目前提供了关闭文章动态链接、限制列表翻页、文章内容JS动态输出三种防采集功能;
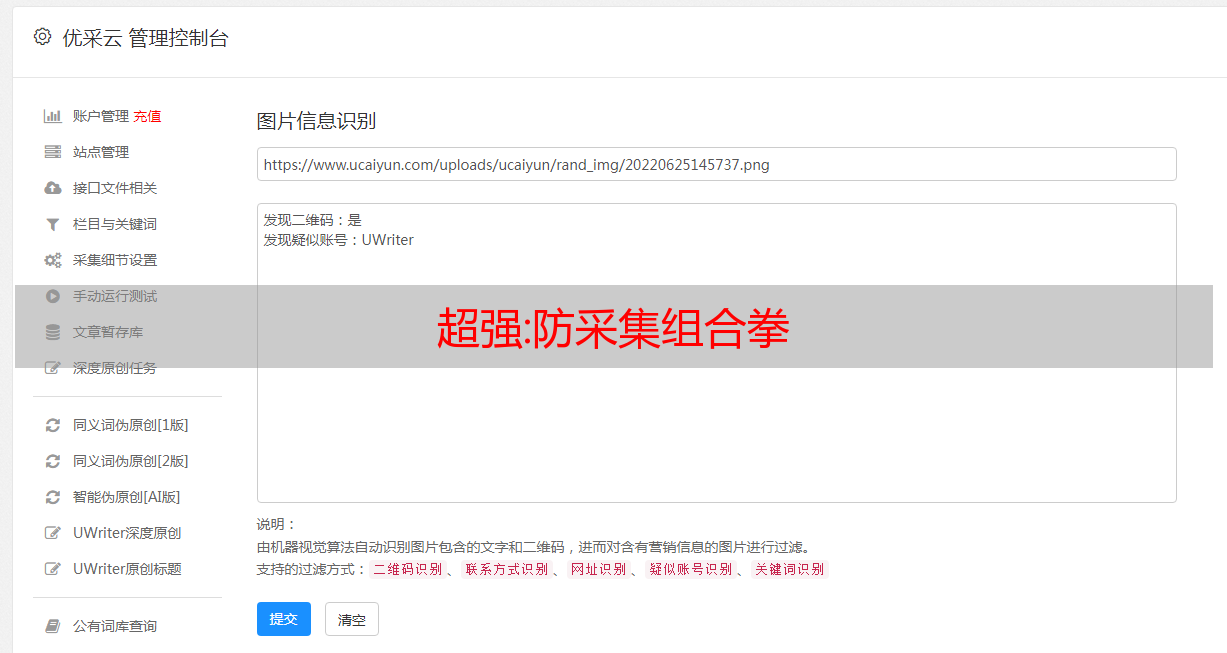
后两个功能对搜索引擎友好,不影响真蜘蛛抓取的内容;
自带搜索引擎白名单名称判断,简单的UA模拟难突破;
特别说明↓
※生成静态页面网站不适用于本插件!目前支持的搜索引擎:百度、谷歌、神马、360、今日头条、搜狗、必应;
※开启文章内容JS动态输出后,通过文章的内容挂载界面显示的其他内容可能会受到影响,需自行权衡选择;
※目前插件只针对程序采集,如果需要禁止手动手动复制等功能,建议使用“网站控制神器[VIP]”插件;
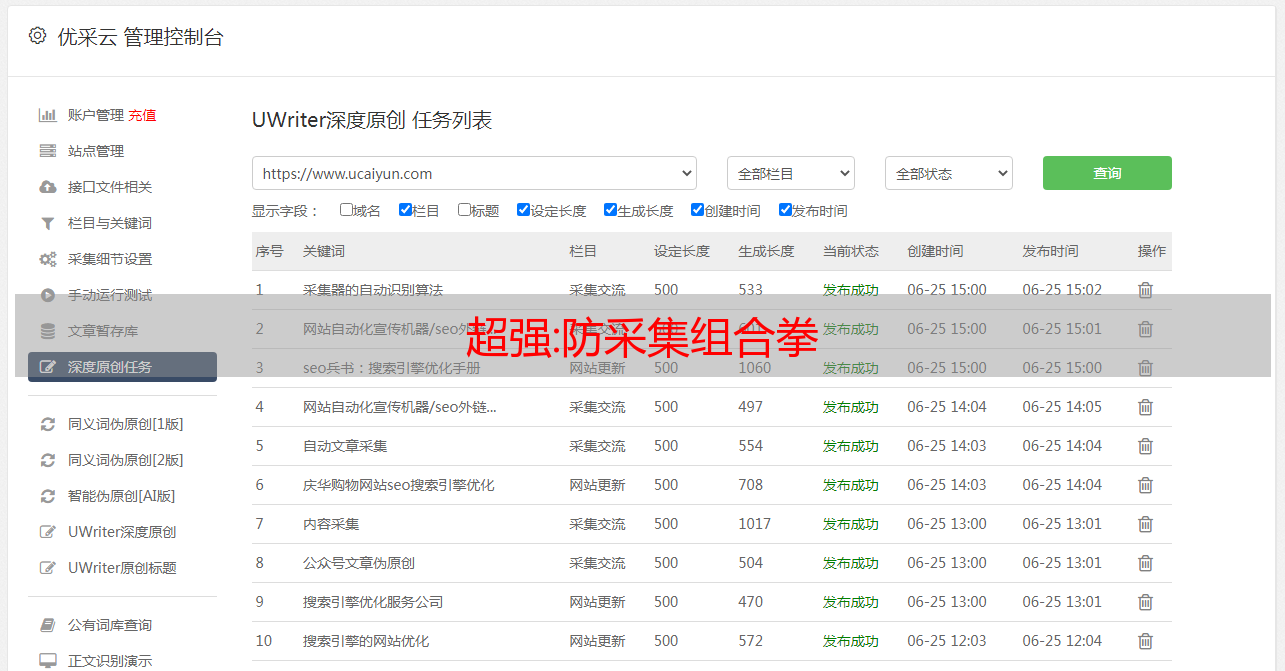
※从演示网站首页第6页开始,普通访问者将显示404。10月1日之后,文章查看源码看不到内容的文字;
查看附图↓
什么?有人说隐藏翻页栏,少显示页码可以防止采集?!太天真了~
有人说在文章的内容中添加随机字符和签名会阻止采集?嗯,反正就是增加了更换成本,喜欢的话~
可怕:又臭又硬的"专利描述"里隐藏着最原始的信息
SEO归根结底始终是一门玄学,这一点是毋庸置疑的,后面会解释。
大多数人总是在追逐权威,却不愿意自己做研究。
只有使用所有可用的工具并获得所有可能的信息,您才能领先于他人。
从我开始做SEO到今天,SEO相关的内容里还有“伪原创”这几个字,导致太多新的SEOer还在想着通过简单的修改替换,增删改段, , 特殊字符可以使搜索引擎误以为这是一个 原创 内容。
但实际上,除了少数幸存者偏差之外,伪原创从头到尾都逃不过搜索引擎的各种算法,搜索引擎也不一定会将目标网站降级为各种原因,但如果只是简单地识别一段内容是否重复,搜索引擎的算法太多了。
除了伪原创,SeoEr 还有很多可以避免的错误。作为一名SEO人员,了解搜索引擎的各种算法(不是指石榴、青萝卜等公开的惩罚算法)和工作原理是非常有必要的,相当于得到了一个*敏*感*词*。不幸的是,搜索引擎不会告诉我们,那么我们在哪里可以尽可能多地了解这些呢?
专利网站
科技公司在“发明”一种技术手段(很多发明其实是相似的)时,一般都会申请相应的专利。专利项收录对专利的具体描述,包括专利的目的、原理、场景、步骤等。、效果等。
搜索引擎本身就是一个庞大的系统。从爬取、收录、建库、索引、查询、缓存等,会涉及到很多算法、技术手段、思路,一般以专利的形式提交。
早些年从事SEO的时候,经常在业余时间阅读这些专利,发现了很多优化思路,有的甚至是专门写给大家的。如果你再犯错误,那将是真的不能说足够。
我一般会看各种可以查询专利的网站,因为每个网站不一定都是完整的。作为补充,我主要推荐这两个:
诱饵:
苏帕特:
其他专利查询网站可以在百度上搜索,你可以找到自己觉得方便好用的。我不知道这块的性质,他们应该都调用相关部门的数据。
如何使用这样的网站?比如我们想知道百度的搜索引擎技术采用了哪些方法,那么在搜索框中搜索百度,返回的结果都是百度提交的专利信息:
如果您查询的公司名称相似,您必须首先确认目标公司的完整工商名称。或者,您可以使用组合查询:
通过这种方式,您可以查找一些特定的专利信息并将其限制为某个申请人。
下面我们来看一些例子,其中一些是我早年保存的专利描述:
名称:文档检测方法及设备应用年份:2011 描述:本发明提供一种文档检测方法,包括:获取文档对应的段落特征信息;将文档的段落特征信息与至少一个现有文档的段落特征信息进行比较;根据比对结果,判断是否存在与该文档相似的现有文档。本发明通过段落特征信息检测文档,可以更准确地比较文档之间的相似度,避免文档切分处理的作弊行为,查询效率高,服务器处理压力小。文档检测方法用于改进对在线文档版权属性的检测,可以在文档上传时检测到文档,避免后期检测文档版权属性时对服务器造成不必要的压力;有文档版权属性检测,效率更高。
由于种种原因,该专利描述又臭又硬,以至于除了审稿人之外,没有人愿意看到它。让我们翻译一下这个内容,看看它反映了什么信息: 本发明提供了一种文档检测方法:这是一种用于检测文档的技术手段。目标是从文档中获取该文档对应的段落特征信息(在搜索引擎眼中,一个网页就是一个文档):假设该文档是:a、获取a的段落特征(如长度、字符、词干、位置距离、上下文等)将文档的段落特征信息与至少一个现有文档的段落特征信息进行比较:计算文档a的段落特征信息(一般转换为md5、hash、矢量等 ) 和存储在数据库中的文档集以与以前相同的方式计算。根据比对结果判断是否存在与该文档相似的文档:如何判断我们不关心,目标是判断现有数据库中是否存在与某个文档相似的文档。很明显,这是一种文档重复检查的方法。本发明通过段落特征信息检测文档,可以更准确地比较文档之间的相似度,避免文档分割处理的作弊行为:该方法使用段落特征,“避免了文档分割的需要”。分片作弊”很明显,这个方法用来识别那些伪原创文章转置、修改、并分段 文章 段落。文档检测方法用于提高在线文档版权属性的检测:这里可以理解为识别原创。
至于描述中的其他内容,据说是为了避免服务器压力等等,如果不是重要信息我们可以忽略,不管这个技术手段发明的目的是什么,都不重要,重要的事情是我们知道它有这个手段。我们看到描述中提到了“在线文档”和“版权”,我们大概可以猜到这种技术手段应该应用在“百度文库”上。该专利于2011年申请,2009年推出“百度文库”。
那么作为百度公司,这种方法会不会应用到搜索引擎计算网页的重复次数文章,至少我们可以肯定:在搜索引擎文章判断权重的步骤中,至少有这个方法或者有更高级的判断重量的方法。
其实在权重判断领域,有很多方法: “I-Match”算法:基于单个特征提取 “Shingle”算法:基于多个特征 “SpotSig”算法:基于停用词 “SimHash”算法:基于哈希值,是一种比较优秀的算法。有兴趣的可以找相关文档了解一下。你会发现,我们的很多作弊手段在科技眼里都是非常幼稚的。早期在判断大量标题是否高度相似时参考了“Shingle”算法(完全一致好判断,但高度相似不好判断),再加上倒排索引逻辑和Python哈希数据结构,
如果你知道这些信息,你还会使用那些低级的伪原创战术吗?这是 2011 年申请的专利,但至少在几年前,低级 伪原创 方法仍然很流行。
名称:搜索内容提供方法及搜索引擎应用年份:2014 描述:本发明提出一种搜索内容提供方法及搜索引擎,其中搜索内容提供方法包括:搜索引擎获取用户对目标内容的历史搜索词和目标内容的历史搜索词。搜索词产生的搜索结果的历史操作信息;搜索引擎根据历史操作信息预测用户需求维度;搜索引擎根据用户需求维度获取每个用户需求维度对应的资源数据;搜索引擎接收到与目标内容相关的搜索词,根据用户需求维度展示各个用户需求维度对应的资源数据。本发明的搜索内容提供方法可以保证用户搜索内容的准确性和质量,方便用户从搜索引擎提供的搜索内容中选择需要的资源,降低用户的搜索成本,提高用户的搜索体验.
这项专利所涉及的内容,显然是根据用户的历史行为数据进行排序的。当用户搜索一个关键词时,这个关键词所涉及的内容肯定是之前搜索过的,那么之前搜索过的人,他们搜索了哪些相关词条,搜索后,他们是如何点击的这些搜索结果,他们浏览了多长时间,哪些被关闭了,等等。
关于用户行为数据,第三代搜索引擎主要是通过超链接分析来影响排名,而第四代搜索引擎真正是利用用户行为数据来影响排名。通过这个专利,除了了解用户行为数据对于排序很重要之外,我们是否可以思考一下:在历史搜索结果中,一个页面经常被用户关闭,关闭后他们继续查看其他搜索结果,是不是正确的?你能解释一下这个页面没有解决用户的需求吗?搜索引擎会降低此类页面的排名吗?这个信息非常重要!!!最重要的是不仅要有推断他人的能力,还要有推断他人的意识!
说明:本申请公开了关键词的推送方法及装置。该方法的具体实现包括:获取关键词集合和文本集合,其中,关键词集合包括至少一个关键词,文本集合包括至少一个文本。确定第一个关键词与文本集中各个文本的关联程度,其中,第一个关键词为关键词集合中的任意一个关键词;确定文本集中与第一关键词的关联度超过预定关联度阈值的文本的比例;并根据超过预定比例关键词的比例向终端发送第一个。这个实现实现了关键词压缩和准确的推送。
还有其他可能的应用。
这项专利显然是为了竞标。关于关键词与创意的匹配,创意是搜索广告中的标题、描述、图片等。做过竞价的人都知道,广告素材匹配会影响点击率和整个账户。质量密切相关。像这样的内容,相信很少有人会读亚星,但在任何一个领域,想要有所突破,就必须研究这些别人不想碰的东西。至少这些东西可以让我们免去报名那些割韭菜的培训课程,因为看他的课程目录,我们知道这些内容不值得你花钱。另外,文章想要表达的是,我想尽可能主动地获取信息。信息的缺乏造成了差距。我也在百度官方社区论坛看到了技术专利的相关资料,然后就想到去这种地方了解,当然他们不会告诉你从专利中了解他们的搜索引擎算法网站 ,所以推断其他事物的意识在这里也很重要。所有这些信息都可以公开查询,只要你主动,它们都在那里。例如,我最近在看这些:所有这些信息都可以公开查询,只要你主动,它们都在那里。例如,我最近在看这些:所有这些信息都可以公开查询,只要你主动,它们都在那里。例如,我最近在看这些:
最后,解释一下为什么SEO终究是一门玄学?SEO不是一门自然科学。它的所有知识都间接地反映在商业公司设计的搜索引擎功能上。商业公司正在追求利润最大化。搜索引擎只是为公司服务的工具,所以规则是可以改变的。也就是说:无论您的优化方法多么正确,无论您的网站内容多么高质量,搜索引擎都没有法律或道德义务首先对您的页面进行排名。在SEO中,一定要正视这个逻辑,端正心态,否则随时会有炸掉百度大厦的心态。

