操作方法:文章自动采集器(文章自动采集软件有哪些)
优采云 发布时间: 2022-10-14 19:19操作方法:文章自动采集器(文章自动采集软件有哪些)
目录:
1.自动采集文章软件
易于使用的文章采集器,我们不需要输入采集规则来进行全网采集,文章为文章 我们对 采集器 感兴趣,有 关键词文章采集 和可视化名称 网站文章采集,这很有用,因为我们不需要输入很多命令,只需点击鼠标即可完成文章采集的工作。
2. 文章采集器哪个好用
3. 自媒体批处理采集文章软件
关键词采集我们需要输入我们的核心关键词,选择我们需要的相关平台如自媒体采集,就可以完成采集任务设置,关键词采集器通过关键词自动匹配大量实时热点文章,为我们提供大量文章创作材料。
4. 热门文章采集器
视觉指定采集,对我们网页感兴趣的可以点击鼠标完成指定采集设置,支持英文网站采集等外语,并且内置翻译功能,导出到本地或者发布给我们cms是一键翻译,支持段落标签保留。
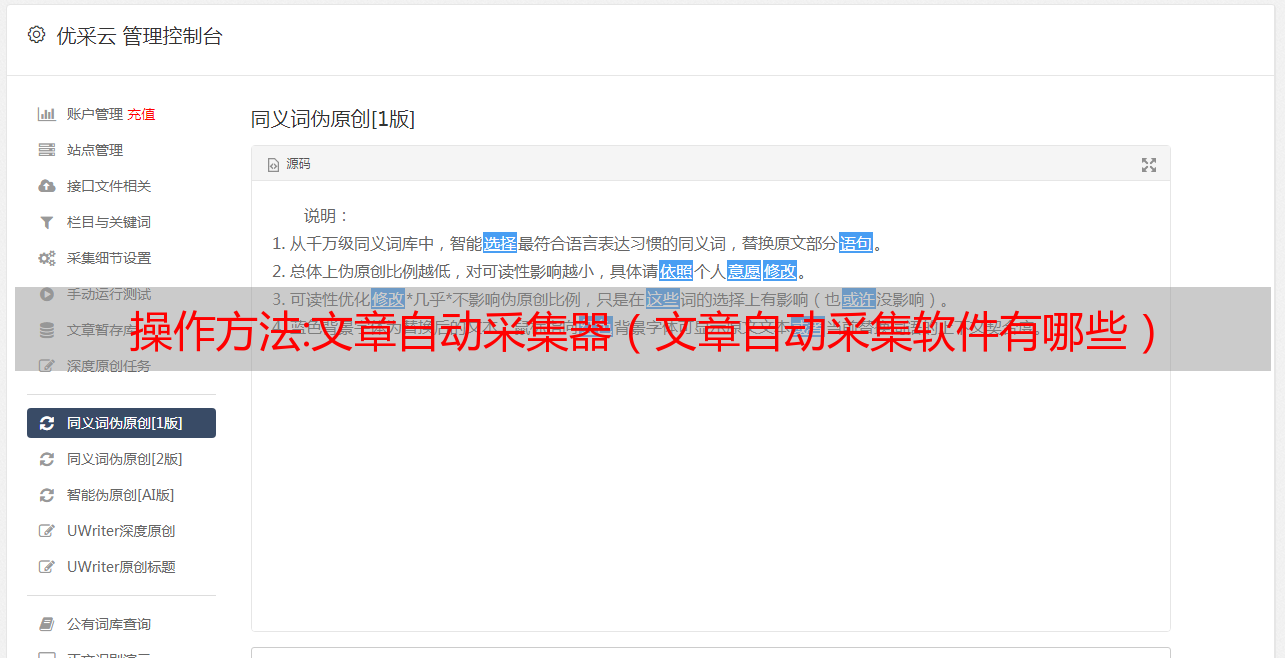
5.公众号文章采集软件
通过指定采集的监控页面功能,我们可以监控固定页面采集,应用于实时更新的网站内容采集,也可以评论论坛采集,让我们实时关注舆论动向,调整我的论坛节奏。
6. 网站文章采集器
网站优化离不开我们的原创美容和搜索引擎优化(SEO),什么是原创内容,对于搜索引擎来说,可以为用户提供解决方案,不能确定是抄袭文章就是原创,所以伪原创如果它可以提升用户体验,也是一种原创如果我们希望我们的SEO策略有效并且我们的受众信任我们,而且它也很容易实现。
7.通用文章采集器
继续阅读以发现在为任何在线渠道创建新的 文章 时要实施的一些最佳实践
8.文章采集器的作用
仔细检查和校对我们的内容,在新内容上点击“发布”之前要做的第一个动作当然是审查它记住,事实上,原创也包括自我原创——(经常)不小心复制并发表自己以前的作品,但声称是 原创
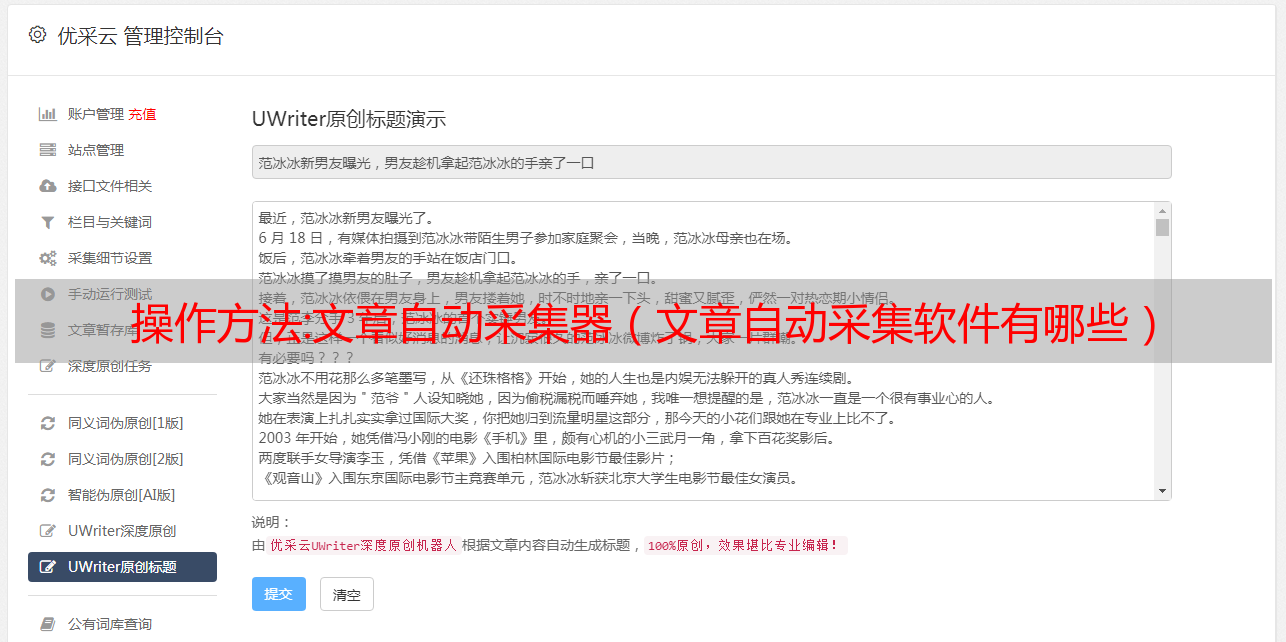
9. 文章采集生成原创软件
因此,请确保我们投入足够的时间来执行所有必要的检查,以保护我们的内容免受任何复制或自我复制问题 检查内容的可读性、语法、结构和关键字是否听起来重复或非原创,请在公开之前标记它并确保了解我们 文章 的底部。
10. 自媒体文章采集器
如何始终如一地创建我们的 原创 内容,如果我们正在为在线商店编写产品描述,这可能会特别棘手。在这些情况下,很容易将完全相同的内容用于仅颜色不同或适合项目的东西但是, 尝试在每个描述中保留 原创 至关重要。
要有创意,为每件单品添加一些独特的东西,无论是谈论特定颜色可能适合什么心情,还是我们如何佩戴该物品
文章采集器的分享就到这里了。什么样的文章采集器好用?当然是基于用户体验,降低用户学习成本。强大的采集器,如果你喜欢这个文章,不妨采集并连续点赞3次。
主题测试文章,仅供测试使用。发布者:小新SEO,转载请注明出处:
干货教程:用 PyQt5 写一个傻瓜式的一键数据采集软件
数据采集越来越成为互联网从业者的刚需。
从内部报告到外部市场动态,需要采集大大小小的信息和数据。爬虫无疑是最快最高效的常规数据采集的方法。但是,要写爬虫,必须有一定的编程基础,谁能受得了。市面上也有一些自助数据采集工具,如:优采云、优采云等,确实是在降低数据采集和门槛和方便数据采集的操作。但这些工具或多或少还是需要手动定义和选择规则。在State先生的“前爬虫生涯”中,遇到过很多生意人,有一个要求:直接把数据给我。如果答案是否定的,它会说:你给我一个工具,让我点击数据,它就会出来。其实我们可以使用PyQt5对爬虫程序进行封装打包,实现傻瓜式,一键式采集软件。这个特别适合普通商务人士,实时数据性能不高,但需要登录。网站。下面,我们以采集微信公众号后台数据为例,介绍使用PyQt5开发一键傻瓜式数据采集工具。核心采集代码就到这里了,我们只用采集微信公众号后台“整体账号状态”的数据作为演示:这个特别适合普通商务人士,实时数据性能不高,但需要登录。网站。下面,我们以采集微信公众号后台数据为例,介绍使用PyQt5开发一键傻瓜式数据采集工具。核心采集代码就到这里了,我们只用采集微信公众号后台“整体账号状态”的数据作为演示:这个特别适合普通商务人士,实时数据性能不高,但需要登录。网站。下面,我们以采集微信公众号后台数据为例,介绍使用PyQt5开发一键傻瓜式数据采集工具。核心采集代码就到这里了,我们只用采集微信公众号后台“整体账号状态”的数据作为演示:
我们使用 requests 库来处理 HTTP 请求,使用 BeautifulSoup 来解析和提取 HTML 文档的数据。其核心采集代码如下:
<p> def check_status(self):
try:
print("获取到的Cookie:", self.cookie)
print("获取到的Token:",self.token)
# 获取当前登录店铺和用户名
url = 'https://mp.weixin.qq.com/cgi-bin/home?t=home/index&token={token}&lang=zh_CN'.format(token=self.token)
wbdata = requests.get(url, headers=self.header, cookies=self.cookie).text
soup = BeautifulSoup(wbdata,'lxml')
nickname = soup.select_one("a.weui-desktop-account__nickname").get_text()
total_cnt = soup.select("em.weui-desktop-data-overview__desc")[2].get_text()
self.nickname = nickname
except Exception as e:
self.nickname = None
logger.error("获取用户信息出错:{}".format(repr(e)))
return (self.nickname, self.cookie)</p>
搭建图形界面因为微信公众号需要登录才能使用,所以我们使用PyQt5的QtWebEngineWidgets小部件在程序中嵌入浏览器,直接在程序中实现登录操作。
可以看到我们图形程序的主界面分为两个选项卡,通过QTabWidget选项卡部分实现。在第一个选项卡中,我们放置了一个 QtWebEngineWidgets QWebEngineView 小部件,用于显示网页和登录。在第二个选项卡中,我们放置了按钮小部件和文本输入小部件,用于控制数据采集 的进度和结果以及显示数据采集.
采集处理与控制 程序的图形界面构建完成后,我们需要对程序的功能进行处理。这些功能包括: 网页的cookie是我们获取登录状态的关键。在这里,浏览器配置文件是通过 QtWebEngineWidgets 的 QWebEngineProfile 组件实现的。QWebEngineProfile 有一个 cookie 存储,每个请求都会将 cookie 写入 QWebEngineProfile,我们将从这里读取最新的 cookie。数据采集的执行是通过“检查登录状态”按钮进行的,按钮的点击信号绑定了一个槽函数。slot函数调用QThread在子线程中执行数据采集。核心代码。而结果的输出,我们通过文本输出框来实现。
<p> # 在控制台中写入信息
def outputWritten(self, text=None):
cursor = self.label_1.textCursor()
cursor.movePosition(QtGui.QTextCursor.End)
cursor.insertText(text)
self.label_1.setTextCursor(cursor)
self.label_1.ensureCursorVisible()</p>
这样,在按钮的slot函数中,调用outputWritten方法在文本框中输出采集信息。最后的结果最终我们实现的效果是:打开程序,在“登录页面”标签页扫码登录微信公众号后台;然后切换到“操作页面”,点击“检查登录状态”按钮,程序会自动采集数据,最后输出到文本输入框。未登录时的效果:
登录状态下的效果:
按照同样的逻辑,我们可以在采集网页中实现其他数据,比如文章列表数据、观察列表用户数据等,或者其他网站数据。
您希望它以“Python GUI 开发视频教程”的形式呈现吗?点击下方“看”,给它一个去大厅的机会,给我一个鼓励!

