汇总:新人才网优化解决方案-SEO研究中心(温州文章智能采集上传)
优采云 发布时间: 2022-10-14 16:12汇总:新人才网优化解决方案-SEO研究中心(温州文章智能采集上传)
温州文章智能采集上传(温州文章智能采集上传网页,可获取页面标题(图片))
新人才网络优化解决方案-SEO研究中心概述
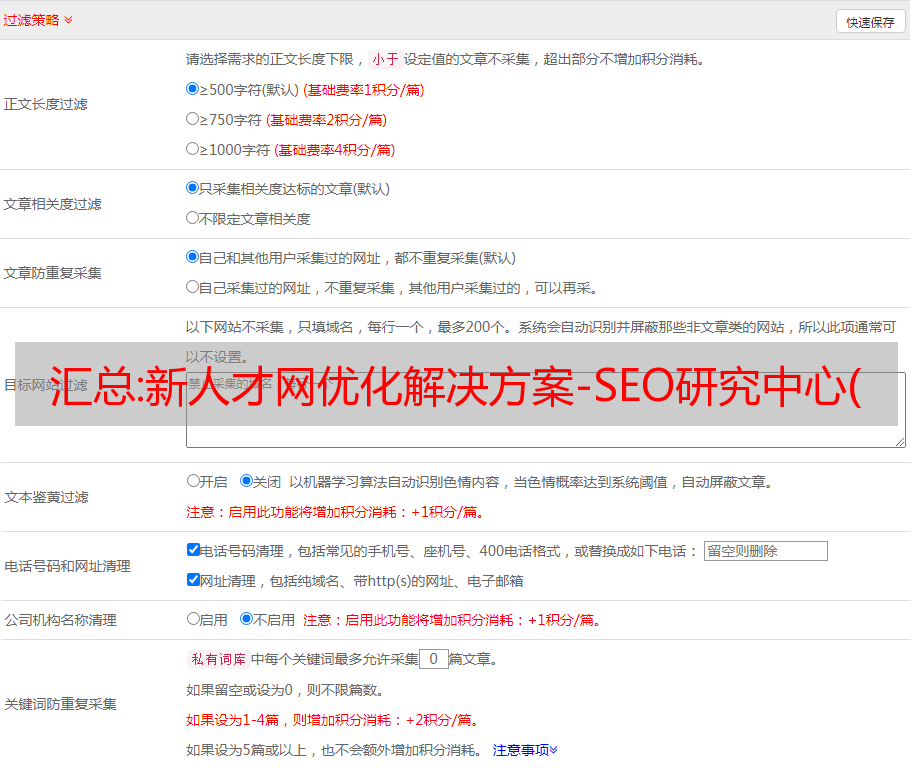
新人才网优化解决方案-SEO研究中心 新人才网网站数据分析网站名称:新人才网网站:/综合人才网,是昆明最全的在线人才信息网网站。相关数据分析:排名:PR值:4 百度指数:1410 谷歌指数:8220 关键词:昆明人才网、昆明人才招聘网、昆明招聘网、昆明人才市场、新人才网、昆明招聘会、昆明求职网、昆明人才求职网 1、反向链接分析 a) 外链数:2164(雅虎参考值) b)首页链接点数:50(高权重链接) 情况,现场优化是分为4个项目,从低到高,分别为无、差、好、优。具体分析如下: a) 网站 是否针对title和description进行优化 b) 网站 针对长尾优化 关键词 否 c) 网站 是 网站 为内部链接优化 已优化 d) 页面标签是否在 网站 上优化 否 e) 网站 上的页面是否经过微调 否 f) 网站中的 URL 路径是否是否优化 g) 较长 URL 的布局是否实现 网站 号中的尾随关键字 否 h) 是否在站号中进行面包屑路径优化 否:表示不进行优化。差:表示已经进行了优化操作,但优化方法比较粗糙, 好:表示有一定程度的优化,但不完全优秀:已由专业的网站 优化团队全面优化 3. 反向链接资源分析 a) 主页附属链接未正确使用 i。建议将相对链接数保持在 45 以内 ii. 删除不合格的链接(包括广山|百度的*敏感*敏感*字*,建议清除此链接,否则会受到影响。
太原人才网| 请及时删除或联系站长商讨开通时间。建议每天检查一次会员链接。) 优化方案指南 1. 标题和MATE描述 原标题和描述建议为:昆明人才网| 昆明人才招聘网-昆明人才招聘网-昆明人才市场-新招聘人才网-昆明人才招聘服务重点推荐修改为:昆明新人才招聘网-昆明人才招聘门户。2. 关键词布 a) 长尾关键词 寻找挖掘 300 个高流量行业的建议 关键词。(作用:主要用于内页长尾关键词的布局,增加整个网站的流量。长尾关键词竞争力低有利于排名,数量有利于关键词 挖矿来源:优采云对已有统计背景排序关键词;2.行业用语关键词;3.百度相关搜索关键词排序。b) 所有长尾关键词目录分类 a) 推荐首页关键词为1到3加三个名称关键词(例如:信息化建设、个人网络管理、个性化数据定制) (关键词 3 代表页面,5 代表百度) b) 长尾 关键词 布局 1.长尾关键词 必须在页面描述中收录页面标题,并且 文章title 和 2.length关键词 末尾的页面必须在内部相互链接(称为内部链接)。3.长尾关键词必须出现在<
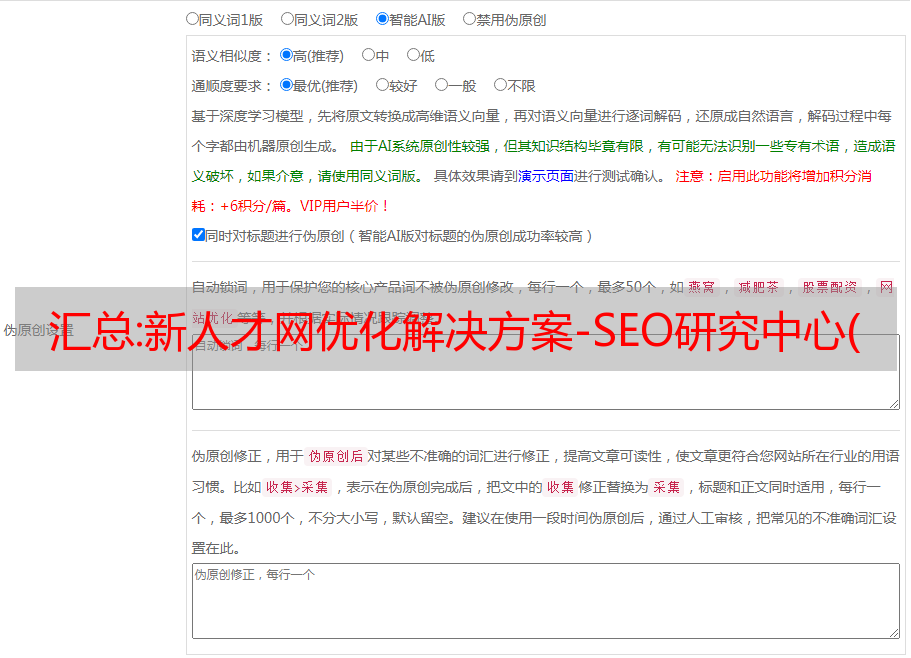
4、长尾关键词的排列应该自然地体现在文章中,而不是人为的添加。(否则会影响用户的阅读,可能会怀疑关键词叠加) c) 长尾关键词外链优化 在所有资源站点中,都有对应的关键词链接。(功能:)资源站包括:自己的网站博客、论坛资源及其他附属的网站资源。推荐博客作为长尾 关键词 外部链接资源。(目前国内大约有500个博客门户,可以用博客群发软件操作,推荐) d) 关键词优化首页1.优化首页标题a)确定三个主主页的菜单键(功能) Word:) b) 主菜单关键字应该没有了
采集内容管理平台(企业版可以零代码搭建各种简单的信息业务系统)
优采云采集器是一个网站采集器,自动采集云相关文章并发布给用户网站。它可以自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则,全网即可采集。内容采集完成后,会自动计算内容与设置关键词的相关性,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、固定链接插入、自动标签提取、自动内链、自动图片匹配、自动伪原创、内容过滤替换、电话号码和URL清洗、定时A采集等一系列SEO功能,百度主动投稿等。用户只需设置关键词及相关要求,即可实现全托管、零维护的网站内容更新。网站的数量没有限制,无论是单个网站还是大站群,都可以轻松管理。
行业实践:MongoDB在信息资源共享建设的应用实践
成立于1950年代,具有60多年历史的中心(以下简称“中心”)提供以软科学为特色的服务;中心服务提供的产品是大量专业化、高质量的专业技术报告。如何更好地利用这些海量文献促进工作发展,是当前面临的核心问题。
为此,信息化部门开始建设“信息资源共享系统”(以下简称“系统”)。该系统的建设目标和意义是:
2.系统使用技术
2.1 系统建设要点
经研究,中心认为可以借鉴百度、搜狗等网民常用的互联网检索系统。互联网用户检索各种网页,而该系统的用户检索中心拥有的文件。基于此,我们需要考虑以下几点:
1、如何将大量的文档存储在一个数据平台的中心,这个平台不仅要保存好文档,还要提供高效的查询和导出服务。
2. 一个文档往往有几万个汉字。如何让用户以最快的速度了解本文档的内容,从而判断内容是否符合用户的要求。
一方面,用户应该能够找到相关文档,另一方面,检索速度应该满足一般标准:对用户请求的响应时间不超过 3 秒。
从这点来看,传统的工程建设方式(比如基于关系型数据库)已经不够用了,所以这里介绍一下大数据、互联网等符合要求的技术。
2.2 系统构建技术
系统建设所采用的技术如下: MongoDB,用于大型数据库存储的文档数据库;微服务SpringBoot,提升检索质量,方便前后端分离;和用于文档文字处理的自然语言处理 (NLP) 技术。下面简要介绍这些。
2.2.1 MongoDB数据库
本系统部门使用的数据库版本为3.6,部署服务器操作系统为windows server 2008。由于服务器硬件和操作系统软件的性能质量比较一般,所以数据库在系统运行中的性能并不是最优的.
2.2.2 微服务和SpringBoot
微服务最重要的特点是,由于服务很小且可独立部署,因此不再需要繁琐的操作来更改应用程序的小部分。SpringBoot是Java领域微服务架构的最优落地技术,Spring Boot 2.0+MongoDB 3.6方案是本系统采用的服务端方案。
2.2.3 自然语言处理
自然语言处理(NLP)以语言为对象,以计算机作为语言研究的有力工具,在计算机的支持下对语言信息进行定量研究。这里我们使用两个重要的部分:
1.自动汇总。一种信息压缩技术,利用计算机按照一定的规则自动提取文本信息,并将其采集成简短的摘要。
2. 关键词提取。从文本中提取一些与这个 文章 的含义最相关的单词。关键词是从报告和论文中选择的一个词或术语,用于表达全文的主题内容信息,用于文献索引。
摘要和关键词在系统构建中有着重要的应用,是工作不可缺少的基础和前提。本系统使用 java 工具包 ansj 来执行这样的工作。
另外,中心出品的文档存储格式基本有:pdf、word、excel、ppt格式。因此,系统使用相应的tika软件包提取文件中的文本内容,然后自动抽象并关键词提取文本内容。
3. 系统设计
系统的主要功能模块由以下两个模块组成:信息采集和信息检索。
中心利用“信息采集”模块对批量上交的大量文件采集进行处理,并将处理结果保存在数据存储中。用户可以使用“信息检索”功能检索采集的结果,并对检索结果进行详细读取等操作。这里需要注意的是,本文所使用的示例文档均来自公共新闻网站。
3.1 信息采集
3.1.0 工作流程
单据采集进入系统的流程步骤如下:
1. 文件采集
2.全文提取
3.自动总结和关键词提取
4.文档间相关性计算
本模块内容如下:文档采集、全文提取、自动摘要和关键词提取、文档间相关性计算。文章不仅介绍了各个子模块的工作内容,还用图例展示了工作效果。
3.1.1 文件采集
文件采集 在后端服务器上实现。批量准备大批量的文档,逐一读取,生成元数据(年份、作者、部门等)。将文档本身和生成的元数据保存到数据库中。
图 1. 服务器上的准备文件为 采集。可以看到“文润玉皇阁.docx”是一个示例文件,文件大小为9MB。
图 2. 采集 之后的文档存储在 MongoDB 数据库 (GridFS) 中。从图中可以看到数据库中存储的文档“温润如玉冠小屋.docx”。数据库管理员可以将文档完全下载到本地。
图 3. 显示为该文档生成的元数据(部门:管理办公室,年份:2019,类别:报告……)。需要注意的是,这些文档在数据库中整体存储为pdf/doc/ppt格式文件,用户无法查看和搜索其内容。
3.1.2 全文提取
读取上一步保存的文档,读出所有文本内容,然后将这些内容保存到数据库中(MongoTemplate技术)。
图 1. 存储在数据库中的全文。由于文献内容较多,读者只能看到部分内容。事实上,全文有一万多字。
3.1.3 自动总结和关键词提取
使用NLP处理软件包自动生成摘要关键词提取“温润如玉的长荣航空皇家桂冠小屋.docx”中提取的全文,并存入数据库(MongoTemplate技术)。
图 1.“长荣皇家皇冠客舱.doc”自动摘要生成的内容。
图 2. 提取的 关键词。从该文档中提取的关键词有:Evergreen、Airline、Business Class、Lounge、Seat、Laurel Class、Taipei等。
3.1.4 文档间相关性的计算
当用户发现一个对他的工作有用的文档时,他一定想进一步了解一些相关的文档。系统在后台计算每个文档的相关度,获取与该文档相关的一批文档,并保存起来供用户使用。
该函数背后的数据科学原理是可信度计算:关键词同时出现在文档1和文档2中的数量与文档1关键词的数量的比例,值为(0,1 ] ,值越大,相关性越高。采集到《长荣航空的桂冠小屋,温暖如玉.docx》的相关文档如下,可以看出,这些文档都是关于民航飞行的。
3.2 信息检索
3.2.0 工作流程 本功能面向中心的广大用户。用户可以使用该功能模块在网页上进行相关搜索。系统一般可以用下图来说明各个操作的工作流程:
该功能涉及系统的三层结构:web前端、运行在服务器JAVA EE平台上的微服务架构、文档数据库MongoDB。
服务器部署的微服务概览如下图所示:
该功能模块可以分为以下几个子模块:关键词检索、文献信息浏览。
3.2.1 关键词搜索
信息检索模块主要面向中心用户。它提供了类似于百度检索的功能:用户在文本查询框中输入关键词后,页面返回一批相关文献数据,用户可以查看详情。内容。系统提供文件名检索、目录(摘要和关键词)检索和全文检索。
图 1. 用户搜索文件名中带有“engine”的文档。用户提交关键词“引擎”后,网页显示相关文献采集。如果文档过多,用户可以点击分页查看更多内容。本次检索到72条相关文献,左侧显示了这72条记录(分类、年份、作者、部门等)对应的分类和摘要
图 2. 显示每条记录(文档)呈现给用户的内容。包括文件名、摘要(字数过多会截取前几个交叉)、关键词、安全级别、年份等。
3.2.2 浏览文献信息
如果用户想了解更多关于其中一个查询结果的信息,用户可以打开一个新页面来查看它。
图 1. 显示用例“Pratt & Whitney 推出新的航空发动机 MRO 服务品牌 EngineWise”
该功能不仅显示一个文档的详细信息,还显示与该文档相关的其他文档的简要信息(推荐阅读)。
图 2. 显示与“Pratt & Whitney 推出新的航空发动机 MRO 服务品牌 EngineWise”相关的其他文献。可以看出,这篇和相关的文献都是关于发动机维修(MRO)的。
4.系统运行
系统目前拥有收录近42万份文档(360GB),可供中心工作人员查询下载。系统运行良好,平均用户请求响应时间小于2.5秒。
5. 未来工作
未来的工作可以分为事务性工作和系统功能扩展两部分。事务性工作。
信息扩展采集:力争到2022年达到70万条数据(500GB)。
系统功能扩展:模仿百度、搜狗等互联网检索系统。一些有益的功能:智能检索,提升用户体验,更重要的是在使用过程中不断发现新的知识点。

