事实:从整站的采集任务量中采集title爬取网站关键词
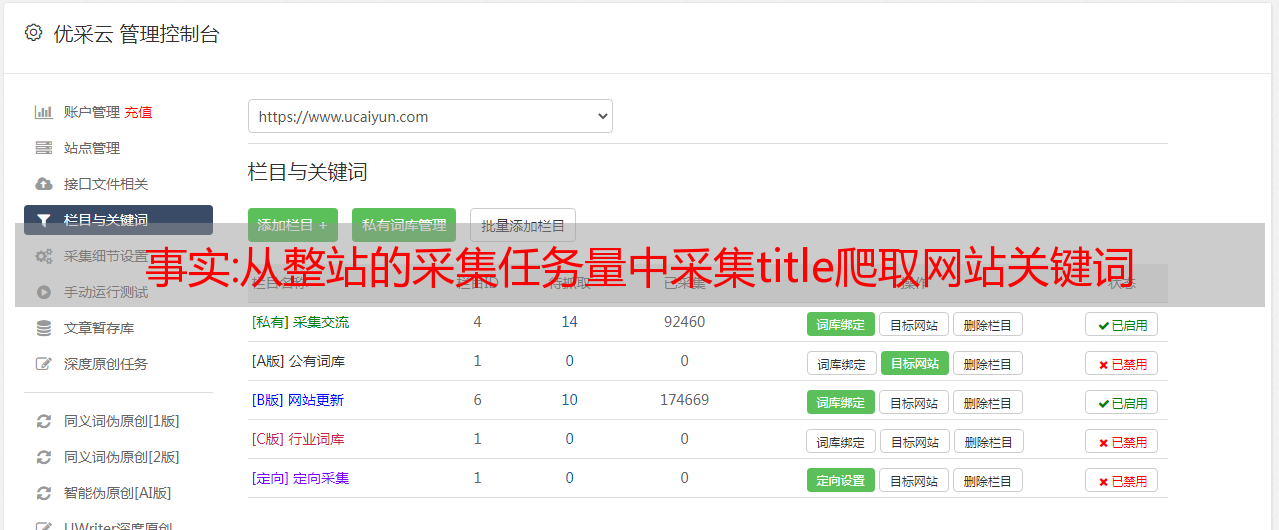
优采云 发布时间: 2022-10-13 17:18自动采集子系统爬虫分析之一baiduspider首先,介绍一下小爬虫系统的基本框架:抓取一条网站的title;爬取网站大多数信息;反爬虫系统检测;寻找有效目标,同时满足缓存、性能、代码、配置的需求;完成,抓取某条信息。爬虫分析小爬虫是一个小系统,小系统想爬取a网站的内容,我们先考虑怎么爬取,爬取网站有多少网页,考虑是否要爬取这个网站的内容。爬取某网站的网页数:网页爬取量=页数*10_100=10*100*10_100(。
1)title从整站的采集任务量中采集title爬取网站关键词title就是网站标题,这些内容对爬虫来说,采用requests库。即#!/usr/bin/requests#-*-coding:utf-8-*-#@date:2018-5-16url=""#@return:json格式数据list.parse("start")采集后的json数据:title=json.loads(json.dumps(requests.get(url)))#加载时加上参数,获取正则,即爬取某个部分title包含123网站的response带有path对象即页面的路径。
#@date:2018-5-16url=";slot=2&city=zhonghe&meta=engine_code&start="+requests.get(url)#加载页面下加载正则即li=requests.get("/"+title)(。
2)网页url,title,text,包含关键词url是无序数组,根据url调用相应函数start=requests.get(url,headers=str.split("/"))#打印转发源站#@date:2018-5-16url=""+requests.get(url,headers=str.split("/"))#打印爬取源站return的对象:#@date:2018-5-16url=""+start+"/"+text这里由于涉及函数有两个,本文简单考虑三个。
由于url是无序列表,如果遇到有next,那么next中会有循环信息,以至于爬取不全面。不需要的时候在,如果需要全部内容,需要加上参数@next即第i个元素#@date:2018-5-16url=";page="+start+""#@date:2018-5-16url=";page="+start+""#@date:2018-5-16url=";page="+start+""(。
3)源站下采集链接常见爬虫用下载器。#@date:2018-5-16url=""+requests.get(url,headers=str.split("/"))如果正则匹配源站下有且已存在的url,返回parsed,否则则返回none。爬取到的文件下直接改none即可,不去爬取网页是否有相应文件。requests.post方法可以传递参数url,next,deleurlclassfilerequest:def__init__(self,cookie,downloadurl):self.cookie=c。

