解决方案:为什么网站一直SEO优化甚至是做百度快速排名都没效果?
优采云 发布时间: 2022-10-12 16:20解决方案:为什么网站一直SEO优化甚至是做百度快速排名都没效果?
网站排名是一项持续的工作,几乎每天都有,所以如果没有新的网站,它必须非常紧迫。有人会问,为什么有的网站在网站上优化了,排名稳步上升,有的网站优化了却没有效果。以下和 网站 排名将根据可能的原因进行查看。你做什么工作?
SEO Daniel Lin Hanwen 独家发布。一、服务器响应及设置
许多公司的服务器是阿里云和西部数据,包括静安。毕竟是国内知名的服务商。然后我们在服务器中选择这块。首先一定要记录文件,然后用国内的服务器,一般的网站不一定在程序中,服务器不需要是好服务器,可以选择虚拟主机测试,你可以在网站的时候更换服务器,当然可以
要设置这件作品,我们需要知道我们严格按照制造商的要求设置的选项。如果设置不好,后果很严重。
2. 关键字定位和网站文章更新
SEO Optimized Keyword Targeting就是你想做的词,你要探索和传播哪个词,展开文章标题和文章,然后通过词库编辑,包括页库,包括页面关键字布局,那么我们在做网站的时候,首先要想清楚,你需要做什么,有一个关键词是什么?
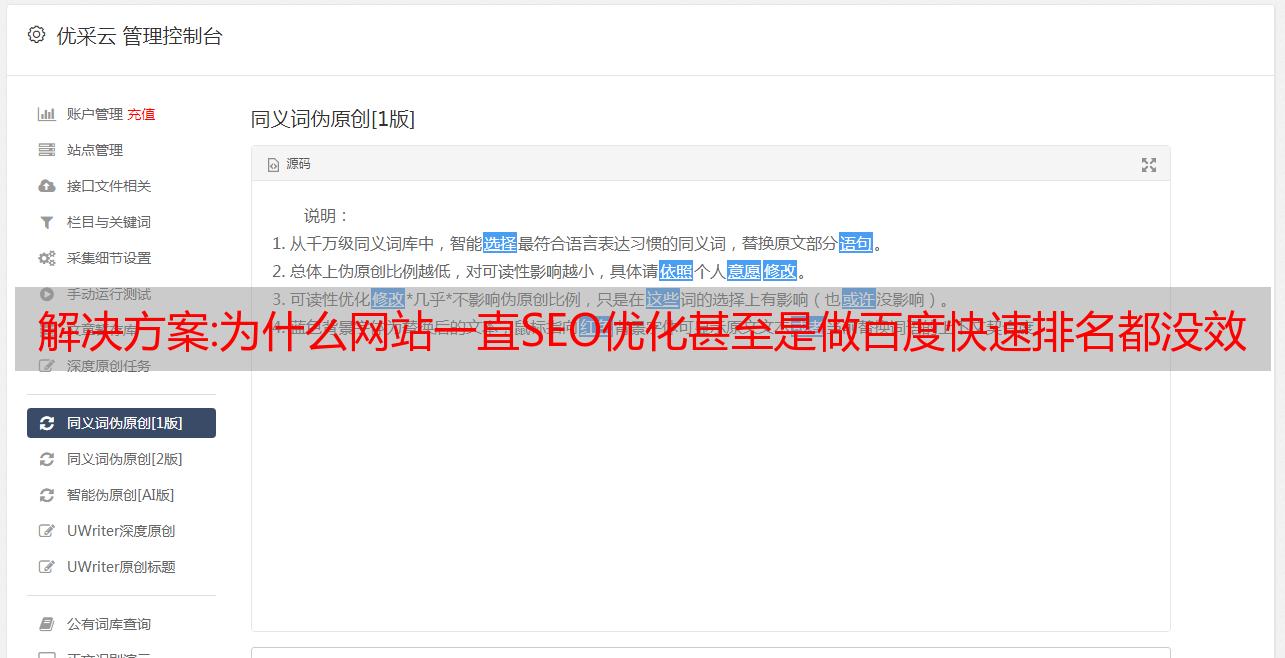
保证词库,有稳定的SEO优化词编辑文章,然后每天更新?你做过SEO优化搜索引擎优化吗?包括每日更新是否到位?我们必须知道这一点。
三、网站一般操作
1.网站验证百度站长;2.主动、自动、手动推送网站数据;
3、百度加速,如果是国外服务器,请忽略;
4、百度统计每日观察;
5、日志分析;
6、百度地图提交;
7、观察竞争对手数据;
8、查看最新官方更新算法,及时调整网站状态;
9、定期更换好友链,释放外链。
如果你没有改过以上,你没有,请检查你是否及时重复网站源代码,最近的百度突击重复模板。
以上就是《为什么网站SEO优化甚至百度快速排名都没有效果?》的全部内容。其他相关问题可以咨询SEO Daniel Lin Hanwen。
解决方案:php批量修改怎么实现,PinPHP购物分享系统2
由于繁忙的一段时间,这一发展已被搁置。今天我看了PinPHP的新版本,一时兴起,我写了关于这批采集实现的文章,没想到写它差不多一两个小时就能实现,虽然写起来比较简单,但也可以帮助一个关键采集一个分类。非常感谢PinPHP团队的发展
好好做开源程序,哈,八卦先,在代码上。
附加的源文件:要下载源代码,请点击此处的>>
.html items_collect PinPHP_V2 修改主要针对模板文件进行。
添加了“批量采集当前分类”按钮:
JS 实现:
(函数($){
当前
var argArray,str,strSplit,strUrl,collectTimer,nLen,count=0,errCount=0;
$(“#btnCollectCurrent”).bind(“click”,function(){
arg数组 = 新数组();
$(“#items_cate_list tr”).每个函数(索引,元素) {
$(this).子项(“td”).每个函数(索引,元素) {
var aTag = $(这个).子(“a”);
if(atag.length>0){
var str=$(aTag).attr(“href”).replace(“javascript:collect(”,“”).replace(“)”,“”).replace(“;” ,“”“).replace(”'“,”“),);
var strSplit = str.split(“,”);
var strUrl = '?page=1&a=taobao_collect_jump&m=items_collect&cate_id='+strSplit[0]+'&关键字='+$.trim(strSplit[1]);
argArray.push(strUrl);
}
});
});
$(“#collecting”)显示();
文本(“#info 采集...”);
nLen = argArray.length;
collectTimer = setInterval(function(){
如果(计数>=nLen) {
清除间隔(collectTimer);
$(“#collecting”).隐藏();
$(“#info”).文本(“采集已完成”);
返回;
}
$.ajax({
网址:阿格阵列[计数],
类型:“获取”,
数据类型:“html”,
异步:假,
成功:函数(){
$(“#info”).文本(“采集...总共“+nLen+”当前正在执行“+计数+”采集失败“+错误计数+”);
计数++;
},
错误:函数(){
错误计数++;
计数++;
}
});
},1000);
});
})(jQuery);
达到的效果:
目前,仅实现当前所选分页采集子类的批处理采集。
从代码中可以看出,它也被拼接采集URL,然后由Ajax定时,这次使用同步采集,当测试发现是异步的
其中一些分类采集失败,可能是因为请求被丢弃了。采集间隔设置为 1 秒,以确保请求完成并防止在类过多时阻塞
导致浏览器冻结。要采集可以为多个页面修改 page 参数,请暂时设置为 1 页
var strUrl = '?page=1&a=taobao_collect_jump&m=items_collect&cate_id='+strSplit[0]+'&关键字='+$.trim(strSplit[1]);
附加的源文件:要下载源代码,请点击此处的>>
总结
如果您认为编程之家网站的内容还不错,欢迎向程序员推荐编程之家网站。

