整套解决方案:优采云采集器(www.ucaiyun.com)
优采云 发布时间: 2022-10-12 12:24整套解决方案:优采云采集器(www.ucaiyun.com)
优采云采集器提供网页内容采集功能,用户可以通过本软件快速采集多个网页内容、文字内容采集、图片内容采集,视频内容采集,无限采集内容,你需要的所有网页资源都可以通过本软件快速采集,并且支持过滤设置,可以自定义过滤方案。不符合规则的内容不会是采集。对于采集完成的内容,可以选择直接保存为本地文件,也可以选择立即将采集的内容发布到web,也支持保存采集 到数据库。还是提供了很多操作方案,可以满足大部分用户采集web资源的需求。官方还为新用户提供了详细的帮助教程。快速学习采集 网络资源!
软件功能
1、规则定制——通过采集规则的定义,可以搜索到所有网站采集几乎任何类型的信息。
2、多任务和多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得——所见即所得,在任务采集过程中得到什么,过程中遍历的链接信息、采集信息、错误信息等会是及时反映在软件界面上。
4、数据存储——数据自动保存到采集边缘的关系型数据库中,可以自动适配数据结构。软件可以根据采集的规则自动创建数据库,里面的表和字段也可以通过数据库导入方式灵活的将数据保存到客户现有的数据库结构中。
5. 断点继续挖矿——停止采集后可以从断点处恢复信息采集任务,不再担心采集任务被意外中断。
6、网站登录——支持网站Cookies,支持网站可视化登录,即使网站登录时需要验证码,也可以采集。
7. 计划任务 - 此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制——采集的范围可以根据采集的深度和URL的标识来限制。
9、文件下载——可以将采集接收到的二进制文件(如:图片、音乐、软件、文档等)下载到本地磁盘或采集结果库。
10、结果替换——可以按照规则将采集的结果替换为自己定义的内容。
11.有条件的保存——可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12.过滤重复内容——软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13. 特殊链接识别 - 使用此功能可以识别 JavaScript 中动态生成的链接或其他更古怪的连接。
14. 数据发布——已经采集的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
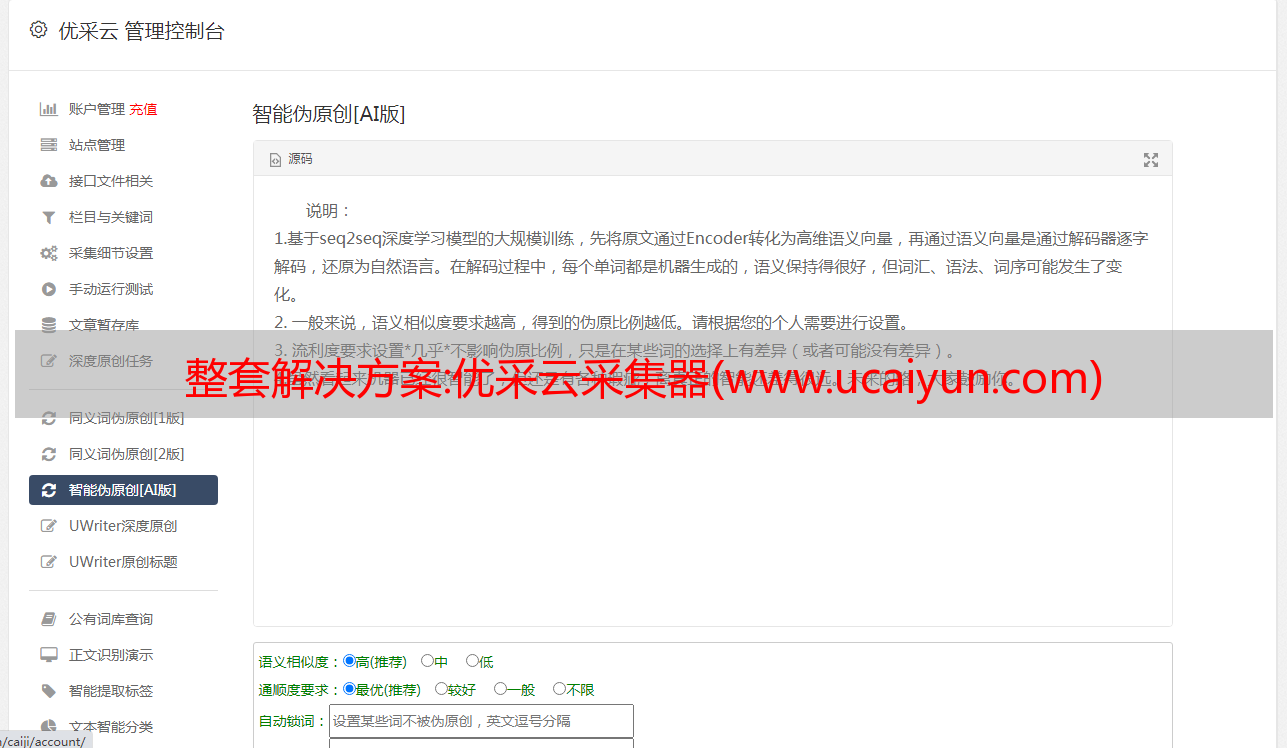
15、预留编程接口——定义多个编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
软件功能
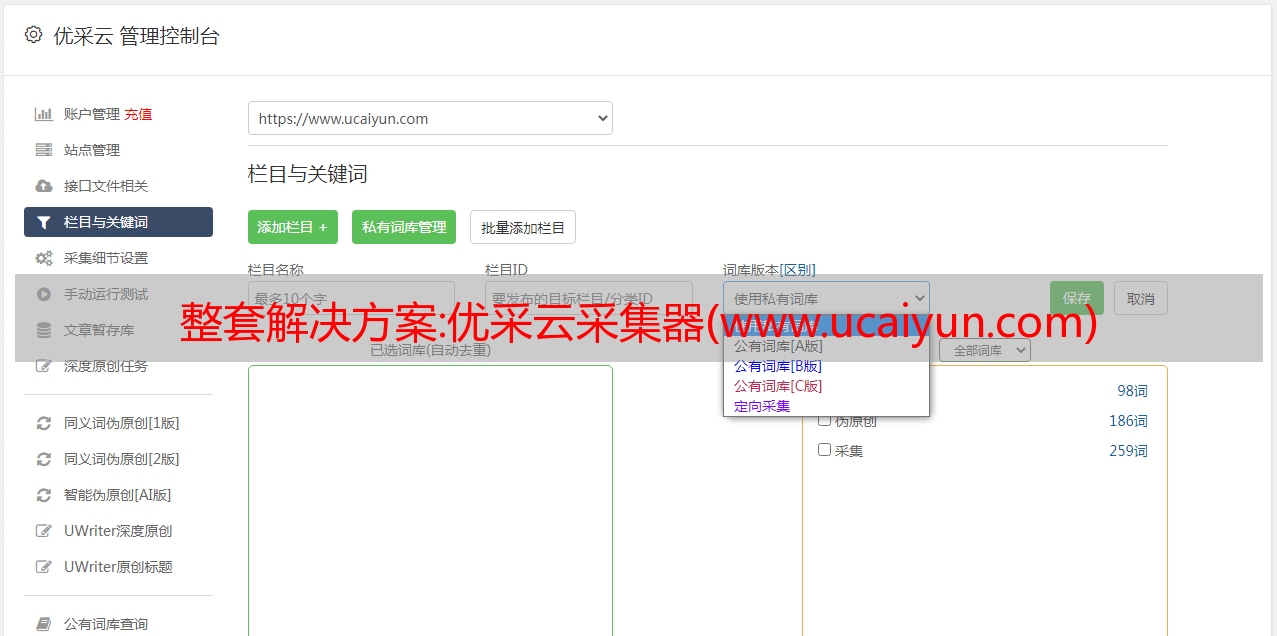
1. 优采云采集器快速提供网页资源采集,可自定义采集规则
2.软件提供新的任务规则设置,可根据提示添加采集规则
3.支持起始URL设置,需要在软件中设置采集的URL范围
4.可以将网址粘贴到软件采集中,一次可以粘贴多个地址
5.可以选择批处理方式快速生成采集的地址,也可以选择从本地导入采集的地址
6.支持通过mssql数据库导入采集的地址,登录数据库即可导入采集的内容
7.设置分页,记得设置内容标签的数据源:在默认页面和内容分页源码中
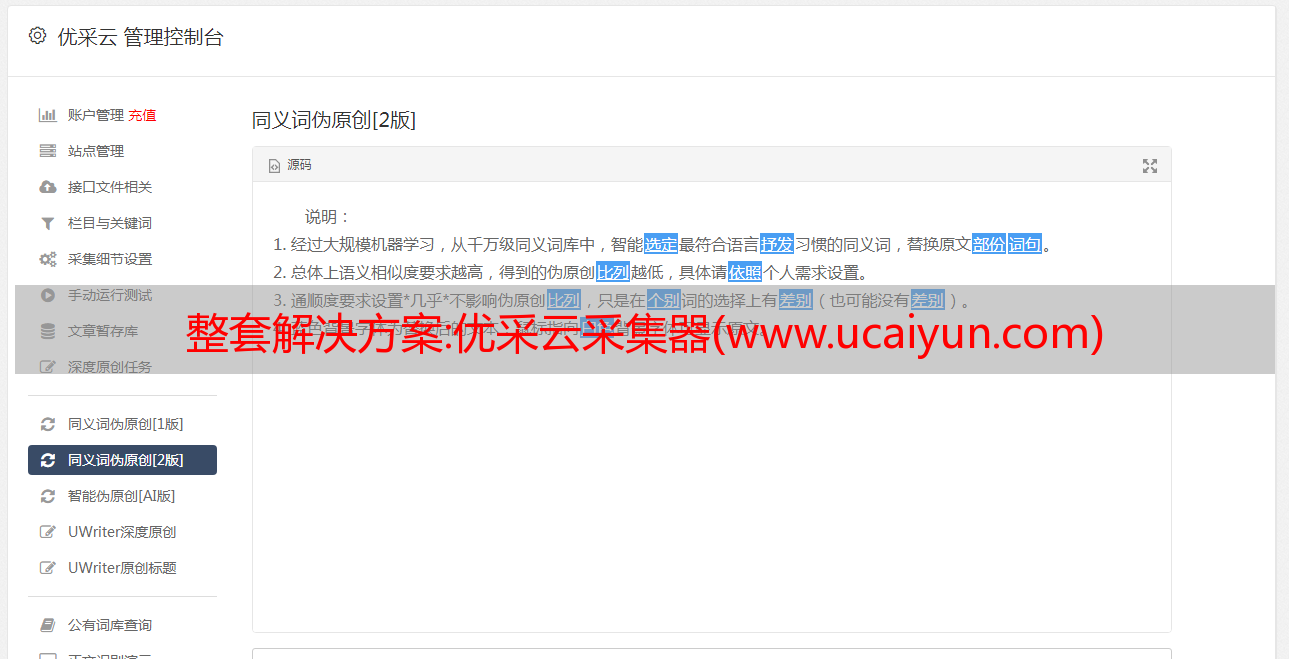
8.支持循环功能,可以循环添加新内容作为新记录,可以用分隔符连接上一条记录,在上一条记录之后循环
9.支持关联多页功能,可从软件默认页面获取地址
10.支持关联区域,可以在软件中添加多个区域,先指定区域,然后根据提取方式获取数据
11.可以设置最大内容页数,每次最大采集个数,提取数据时忽略大小写
使用说明
1、安装优采云采集器到电脑,点击下一步完成安装
2.启动软件提示登录界面,可以注册新账号登录
3.进入软件会自动检测内核版本,可以选择升级到新版本
4.软件的使用还是比较复杂的,可以去官方网站查看帮助教程
5.如图,添加一个新的采集任务,可以在这里设置URL,设置获取内容的方式
6.提示URL添加功能,将需要采集的URL直接复制到软件中,或者选择批处理模式
7.还支持将文本中的地址直接导入软件,或从数据库中添加采集的URL
8.内容采集规则设置,数据获取方式:从源代码获取数据,生成固定格式的数据,结合已有标签
9.发布规则,可以选择将采集的内容直接发布到网页上,可以选择导入数据库,也可以保存为本地文件
10、任务运行线程和时间:本项设置的任务运行时,可在任务运行管理窗口动态修改,实时生效。
解决方案:运用Python实现WordPress网站*敏*感*词*自动化发布文章
很多用WordPress建网站的朋友都有这样的烦恼,网站建好了,没有时间自己写文章,慢慢放弃了,还有一些朋友在浏览器中采集了很多喜欢的博客网站地址,因为URL的采集太多太复杂了,从现在开始很少打开它。事实上,只需几行代码,我们就可以充分利用Python和WordPress来构建我们自己的文章抓取网站。它主要使用python报纸xmlrpc模块来实现网页抓取,通过常规匹配抓取网页内容,并使用xmlrpc自动发布到WordPress部署网站。然后使用克朗德进行定时抓取。
第一部分:抓取目标页面的文章
#得到html的源码
def gethtml(url1):
#伪装浏览器头部
headers = {
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
req = urllib2.Request(
url = url1,
headers = headers
)
html = urllib2.urlopen(req).read()
return html
<p>
#得到目标url源码
code1 = gethtml('https://www.baidu.com')#示例
#提取内容
content1 = re.findall('(.*)',code1)#示例
#追加记录采集来的内容
f1 = open('contents1.txt','a+')
#读取txt中的内容
exist1 = f1.read()</p>
第二部分:通过文章发送到字优
def sends():
for i in range(len(content1)):
u=content1[i][0]
url='https://www.baidu.com'+u
a=Article(url,language='zh')
a.download()
a.parse()
<p>
dst=a.text
title=a.title
#链接WordPress,输入xmlrpc链接,后台账号密码
wp = Client('http://www.python-cn.com/xmlrpc.php','username','password')
post = WordPressPost()
post.title = title
post.content = dst
post.post_status = 'publish'
#发送到WordPress
wp.call(NewPost(post))
time.sleep(3)
print 'posts updates'</p>
最后,通过crontab定期运行程序,采集指定文章发送的WordPress。
0 12 * * 2 /usr/bin/python /home/workspace/python-cn/python-cn.py

