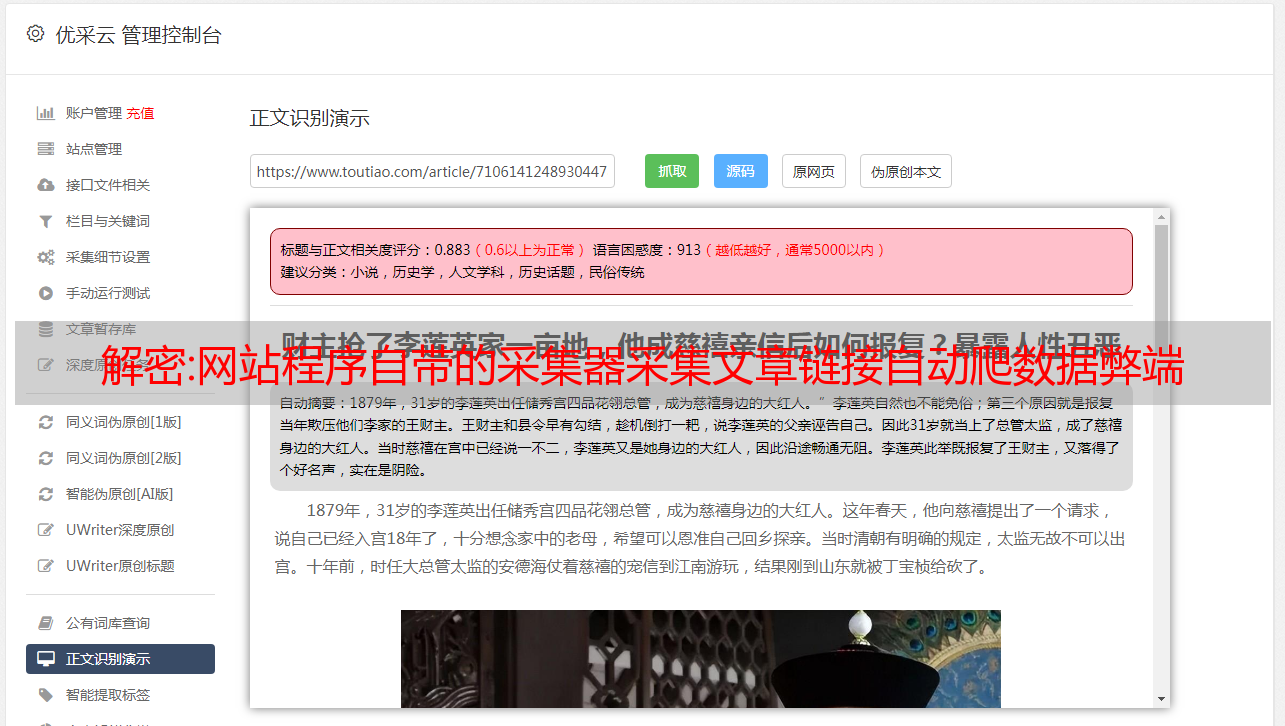
解密:网站程序自带的采集器采集文章链接自动爬数据弊端
优采云 发布时间: 2022-10-11 20:15解密:网站程序自带的采集器采集文章链接自动爬数据弊端
网站程序自带的采集器采集文章链接自动爬数据,弊端是每次爬取的数据库存储容量比较小,如果服务器不大的话很可能需要不断的清理存储空间。后台建议用爬虫来采集,可以看看爬虫工具,一定程度上减少网站服务器负担。
可以尝试一下看雪爬虫,
rss订阅软件:订阅我的文章-订阅助手
可以借助爬虫工具比如fileminer
请先看你要抓取什么数据,然后你就知道你应该用什么方法了。
推荐下scrapy,自带傻瓜式开发,
用googleapi
可以试试scrapy
爬虫最小是多小,有效的话,最小几兆。
工欲善其事必先利其器啊。
免费api服务:登录|thepiwplazation/spillowlibui
robotinfo-technicalpagesforwebframeworksscopusstocksnapshotcoderecorder
requests+images
imdb
feeds队列
用requests就够了,剩下的转移到队列上,慢慢翻页。
requests请求并获取python的imagehtml模块。
python的api还有点复杂啊,我这边我建议你用阿里开源的数据处理系统taobaodataminer配合。通过一个api接口可以大大提高爬虫的工作效率,而且所有图片及css样式都可以用javascript、css等方式存储,包括复杂的处理数据以及接入分析。

