教程:优采云·关键词网址采集器v2.2.3.2
优采云 发布时间: 2022-10-11 16:26输入关键字采集各个搜索引擎的URL、域名、标题、描述等信息
支持百度、搜狗、谷歌、必应、雅虎、360等。每个关键词600到800,采集如
关键词可以很方便的找到引擎参数,就像在网页中输入关键词查找一样,
如果需要在百度搜索效果URL中收录bbs的关键词,请输入“关键词 inurl:bbs”。
保存模板引用数据:#URL#
采集的原创网址
#标题#
URL对应的页面标题
#域名#
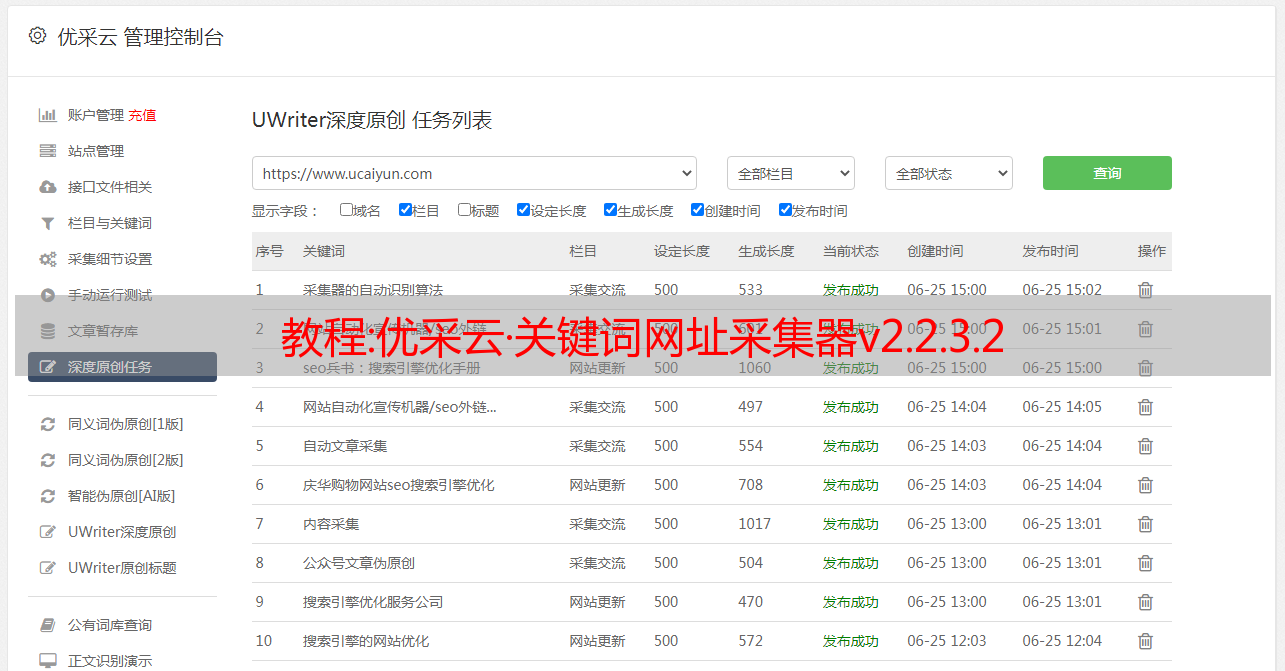
原网址的域部分,如“”中的“”
#顶级域名#
取原创URL的顶级域部分,如“”中的“”
#绘画#
页面标题下方的一段描述性文字
Excel导出:
csv 是一个文本表格,可以显示为与 Excel 兼容的多列多行数据。只需在保存模板中设置为:
"#URL#","#title#","#description#"
此格式为csv格式,每一项用引号括起来,多项用逗号分隔,然后保存扩展名填写csv
问题总结:
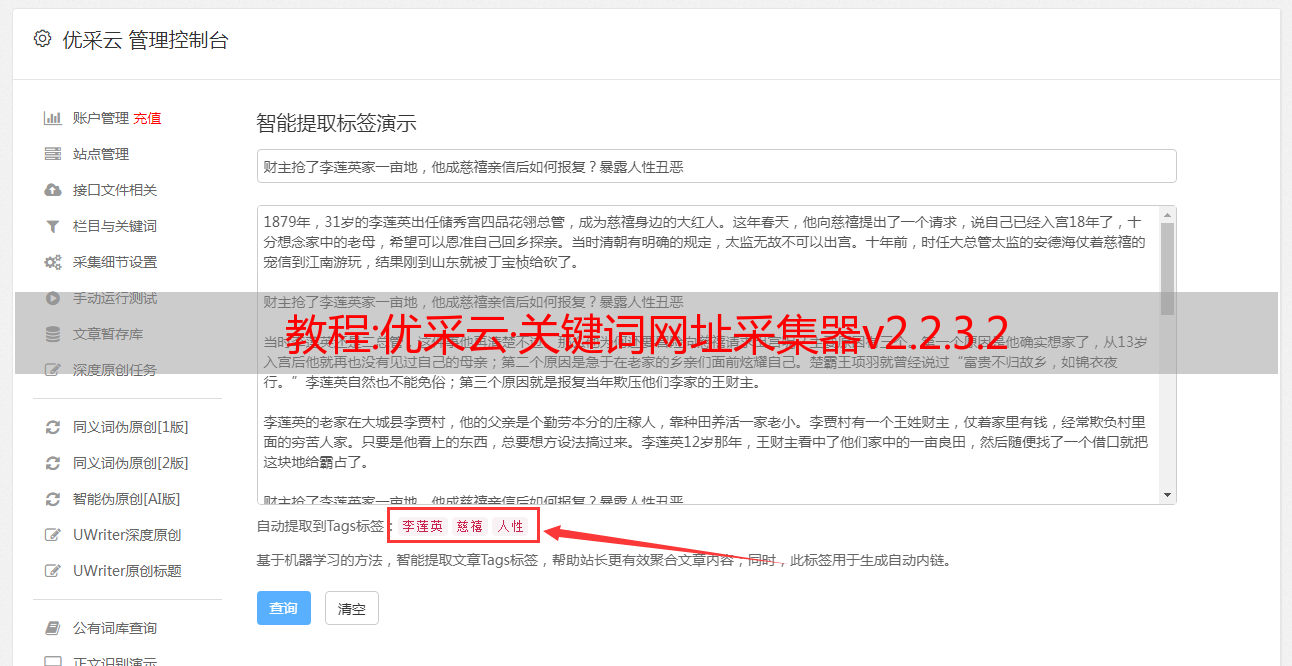
1. 为什么过了一段时间收不到?
这可能会采集到搜索引擎太多的约束。一般可以通过更改IP(如使用VPN更改IP)的方式继续采集。如果不改,只能等搜索引擎取消屏蔽后再继续采集。百度的拦截时间一般是半小时到几个小时。
不过即使现在验证码被屏蔽了,软件也会弹出手动输入的验证码(百度、谷歌)
2、为什么不同批次的关键词采集的结果中有些URL重复?
尤其是在只引用了#域名#或#顶级域名#之后,这种部分URL重复出现的情况很多。这也是正常的,因为每个网站的内页可能收录很多主题,不同的关键词可能会采集到不同的网站的内页。引用域名的时候,同样的网站不同内页的域名效果自然是一样的。
另外,软件中的自动去重是针对本次采集效果的内部去重,上一次采集的效果不为本次去重规划。假设两个集合的效果中有些URL重复,可以合并在一起,使用软件去重(优采云·文本去重加扰器)。
3、为什么采集到的url的主题不匹配关键词?
是因为引用了#domain#或者#top-level domain#后,取了域名部分,域名打开网站的首页,采集到的原创URL可能不是首页,但是网站的某个文章的内页,内页收录关键词的主题,所以被搜索引擎录入,被软件采集。但是,在获取域名后,您打开的域名首页不一定收录关键词。
为了比较采集是否正确,可以在保存模板中输入:#title#
, 并将其保存为 htm 文件。采集后可自行打开文件查看对比。
教程:织梦采集侠v2.9
插件介绍
梦采集人是基于站群DED站群的专业织梦系统/cms软件,可以根据采集、RSS和页面监控等进行关键词,伪原创SEO优化后进行更新发布,无需编写采集规则!
使用教程
第 1 步:
首先登录后台织梦模块-上传新模块-安装采集人
第 2 步:
替换破解的文件:
有三个文件 dede,收录和插件
dede :直接覆盖到网站的根目录
包括:直接覆盖到网站的根目录
插件 :直接覆盖到网站的根目录
网站默认背景是 dede,如果不修改后台目录,则会直接覆盖它,如果修改了后台访问路径,则将背景替换为您修改的名称。
例如,如果修改 dede 以进行测试,则覆盖测试目录
PHP 版本必须为 5.3+
指令自动采集
按照说明,在页脚模板中添加标签

