详细解析:Java性能分析神器-JProfiler详解(转)
优采云 发布时间: 2022-10-11 03:09详细解析:Java性能分析神器-JProfiler详解(转)
前段时间在为公司的项目做性能分析,从简单的Log分析(GC日志、postgrep日志、hibernatestatitistic),到通过AOP采集软件运行数据,再到PET测试。,但总感觉像是在原创时代工作,不可能以简单流畅、极其清晰的方式获得想要的结果。花了一些时间整理学习了之前用过的各种jvm调优和内存分析的工具,包括jps、jstack、jmap、jconsole,JDK自带的,还有IBM的HeapAnalyzer等。虽然这些工具都提供了很多的功能,但它的可用性和便利性远没有 IntelliJ 用于 Java 开发的水平。偶然在云栖社区发现有人推荐Jprofiler,安装了版本使用,发现是神器,特此推荐给大家。首先,我声明这个软件是用于商业用途的。网上有很多关于 lisence 的帖子。我会在这里转发,但我绝对不会推荐大家使用破解版!
#36573-fdkscp15axjj6#25257
#5481-ucjn4a16rvd98#6038
#99016-hli5ay1ylizjj#27215
#40775-3wle0g1uin5c1#0674
#7009-14frku31ynzpfr#20176
#49604-1jfe58we9gyb6#5814
#25531-1qcev4yintqkj#23927
#96496-1qsu1lb1jz7g8w#23479
#20948-11amlvg181cw0p#171159
然后,转到云栖上的一个文章,然后慢慢开始我们的Jprofiler之旅。
1.什么是JProfiler
JProfiler 是由 ej-technologies GmbH 开发的性能瓶颈分析工具(该公司还开发部署工具)。
其特点:
2.数据采集
Q1。既然 JProfiler 是一个性能瓶颈分析工具,那么这些分析的相关数据是从哪里来的呢?
Q2。JProfiler 如何采集和显示这些数据?
(图2)
A1。分析的数据主要来自以下两部分
1.部分分析接口来自jvm**JVMTI**(JVM Tool Interface),JDK必须>=1.6
JVMTI 是一个基于事件的系统。分析代理库可以为不同的事件注册处理函数。然后它可以启用或禁用选定的事件
例如:对象生命周期、线程生命周期等信息
2.部分来自instruments类(可以理解为类的重写,增加了JProfiler相关的统计功能)
例如:方法执行时间、次数、方法栈等信息
A2。数据采集原理如图2所示
1.用户在JProfiler GUI中发出监控命令(通常通过点击按钮)
2. JProfiler GUI JVM通过socket(默认端口8849)向被分析jvm中的JProfile Agent发送指令。
3. JProfiler Agent(如果不了解Agent,请看文章Part 3“启动模式”)收到指令后,将指令转换成相关事件或需要监控的指令,注册到JVMTI 或者直接让JProfiler Agent JVMTI 执行一个功能(比如dump jvm内存)
4、JVMTI根据注册的事件采集当前jvm的信息。例如:线程的生命周期;jvm的生命周期;类的生命周期;对象实例的生命周期;堆内存的实时信息等
5. JProfiler Agent将采集好的信息保存在**memory**中,并按照一定的规则进行统计(如果所有数据都发送到JProfiler GUI,对被分析的应用网络会有比较大的影响)
6. 返回 JProfiler GUI Socket。
7. JProfiler GUI Socket将接收到的信息返回给JProfiler GUI Render
8. JProfiler GUI Render 渲染最终显示效果
3.data采集方法及启动方式
A1。JProfier采集 方法分为两种:Sampling (sample采集) 和 Instrumentation
注意:JProfiler 本身并没有指明 采集 类型的数据,这里的 采集 类型是 采集 类型用于方法调用。因为JProfiler的大部分核心功能都依赖于方法调用采集的数据,所以可以直接认为是JProfiler的数据采集类型。
A2:启动模式:
四。JProfiler 核心概念
过滤器:需要分析什么类。有两种类型的过滤器收录和不收录。
(图4)
Profiling Settings: Receipt 采集 strategy: Sampling and Instrumentation,一些数据采集细节可以自定义。
(图5)
Triggers:一般用在**offline**模式下,告诉JProfiler Agent什么时候触发什么行为来采集指定信息。
(图 6)
实时内存:关于类/类实例的信息。比如对象的数量和大小,对象创建的方法执行栈,对象创建的热点。
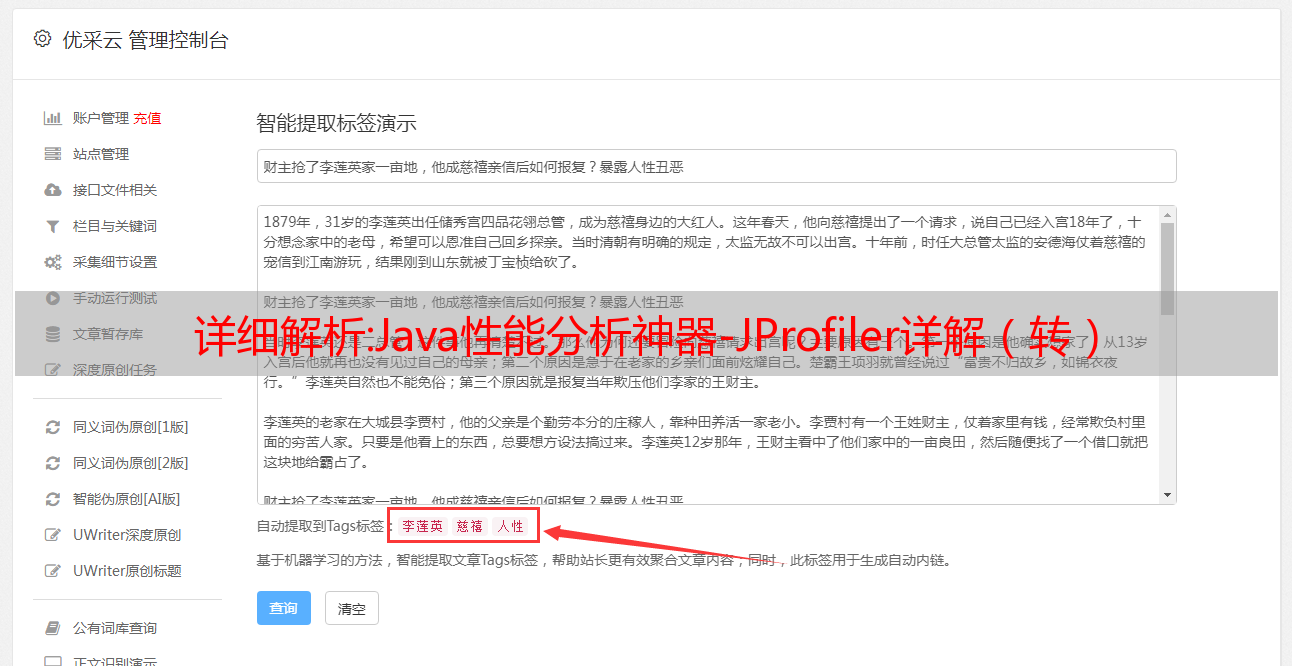
(图 7)
Heap walker:静态分析一定时间内采集到的内存对象信息,功能强大,好用。传出引用、传入引用、最大对象等。
(图 8)
CPU视图:CPU消耗分布和时间(cpu时间或运行时间);方法执行图;方法执行统计(最大值、最小值、平均运行时间等)
(图 9)
线程:当前jvm所有线程的运行状态,持有锁的线程的状态,可以dump线程。
(图 10)
Monitors & locks:所有线程持有锁和锁信息
(图 11)
遥测:趋势图(遥测视图),包括堆、线程、gc、类等。
五、实践
为了方便实践,使用JProfiler8自带的一个例子来帮助理解上述相关概念。
JProfiler 自带的例子如下: 模拟内存泄漏和线程阻塞的场景:
具体源码参考:/jprofiler install path/demo/bezier
(图 12)
(图13Leak Memory模拟内存泄漏,模拟阻塞模拟线程间锁的阻塞)
A1。首先我们来分析一下内存泄露的场景:(勾选图13中的Leak Memory来模拟内存泄露)
1、在**Telemetries->Memory**视图中,会看到下图的场景(查看过程中可以间隔执行Run GC功能):见下图蓝色区域,老年代 gc (**trough**) 后内存大小缓慢增加(理想情况下,这个值应该是稳定的)
(图 14)
点击Live memory->Recorded Objects中的**record allocation data**按钮,开始统计一段时间内创建的对象信息。执行一次**Run GC**后,查看当前对象信息的大小,点击工具栏中的**Mark Current**按钮(其实就是标记当前对象个数。执行一次Run GC,然后继续观察;执行一次Run GC,然后继续观察....最后看看哪些对象在不断GC,数量一直在增加,最后看到的信息可能类似于下图
(图15绿色为标注前的数量,红色为标注后的增量)
分析刚刚记录在Heap walker中的对象信息
(图 16)
(图 17)
点击上图中实例最多的类,右键**Use Selected Instances->Reference->Incoming Reference**。
发现Long数据最终存放在**bezier.BeierAnim.leakMap**中。
(图 18)
在 Allocations 选项卡中,右键单击其中一种方法以查看特定的源代码信息。
(图 19)
【注】:此时问题已经很清楚了。明白为什么图17的实例数一样,为什么fullgc后内存无法回收(老区的一个对象leakMap,put的信息也会进入老区,如果leakMap无法回收,地图中收录的对象无法回收)。
A2。模拟线程阻塞的场景(勾选图13中的模拟阻塞,模拟线程间锁的阻塞)
为了方便区分线程,我将Demo中BezierAnim.java的L236的线程命名为test
public void start() {
thread = new Thread(this, "test");
thread.setPriority(Thread.MIN_PRIORITY);
thread.start();
}
<p>
</p>
正常情况下,如下图所示
(图 20)
在Demo中勾选“模拟阻塞”选项后,如下图(注意下图中的状态图标),测试线程的阻塞状态明显增加。
(图 21)
观察**Monitors & locks->Monitor History**一段时间后,你会发现出现锁的情况有4种。
首先:
AWT-EventQueue-0 线程持有对象锁,处于等待状态。
下图代码表示Demo.block方法调用了object.wait方法。这还是比较容易理解的。
(图 22)
第二:
AWT-EventQueue-0 持有 bezier.BezierAnim$Demo 实例上的锁,测试线程等待线程释放它。
注意下图底部的源代码。这个锁的原因是Demo的blcok方法在AWT和测试线程中。
将被执行并且方法被同步。
(图 23)
第三和第四:
测试线程会继续向 Event Dispatching Thread 提交任务,从而导致对 java.awt.EventQueue 对象锁的竞争。
提交任务的方式如下代码:repaint()和EventQueue.invokeLater
public void run() {
Thread me = Thread.currentThread();
while (thread == me) {
repaint();
if (block) {
block(false);
}
try {
Thread.sleep(10);
} catch (Exception e) {
break;
}
EventQueue.invokeLater(new Runnable() {
@Override
public void run() {
onEDTMethod();
}
});
}
thread = null;
}
(图 24)
6. 最佳实践 JProfiler 会给出一些特殊操作的提示。这时,最好仔细阅读说明。“标记当前”功能在某些场景下非常有效。Heap walker 一般静态分析 Live memory->Recorder objects 中的对象信息,这些信息可能会被 GC 回收,导致 Heap walker 中什么也不显示。这种现象是正常的。您可以在工具栏中的“开始录制”工具栏中配置一次采集的信息。Filter 中的 include 和 exclude 是按顺序排列的。请使用下图左下方的“显示过滤树”来验证顺序。
(图 25) 七。参考 JProfiler 助手:
JVMTI:
相当给力:虎妞万能文章采集器 v3.7.8
虎牛软件出品的一款*敏*感*词*文章采集软件,只需输入关键字即可采集各种网页和新闻,还可以采集指定列表页(列页)文章。
特征:
1、网站栏目列表下的所有文章(如百度经验、*敏*感*词*)均可进行采集指定,智能匹配,无需编写复杂规则。
2、文章翻译功能可以将采集好的文章翻译成英文再翻译回中文,实现伪原创的翻译,支持谷歌和有道翻译。
3、输入关键词,即可采集到今日头条、微信文章、一点新闻、百度新闻及网页、搜狗新闻及网页、360新闻及网页、谷歌新闻及网页网页、必应新闻和网络、雅虎新闻和网络;批处理关键词自动采集。
4、依托虎牛软件独有的通用文本识别智能算法,可自动提取任意网页文本,准确率达95%以上。
通用文章采集器是各大搜索引擎采集文件和制作工具,使用可以提取网页文本的算法,多语言翻译,保证制作出来的文章类似于 原创。如果您需要大量 原创文章,请选择通用的 文章采集器。
Universal文章采集器是一款只需键入关键词即可采集各大搜索引擎的新闻推送和泛网页的软件。虎牛软件独家首创智能算法,可精准提取网页文本部分,保存为文章。支持去除标签、链接、邮箱等格式化处理,以及插入关键词功能,可以识别标签或标点旁边的插入,可以识别英文空格间距的插入。还有一个文章翻译功能,即可以将文章从一种语言如中文转成另一种语言如英文或日文,再由英文或日文转回中文,即一个翻译周期,
通用文章采集器智能提取网页正文百度新闻、谷歌新闻、搜搜新闻的算法强大的不时更新的新闻资源聚合,取之不尽的多语言翻译伪原创。你,只需输入 关键词
软件功能
1、软件首创的网页文本提取算法
2、百度引擎、谷歌引擎、搜索引擎的强聚合
3.不断更新的文章资源取之不尽,用之不竭
4. Smart采集 网站 的 文章 部分中的任何 文章 资源
5. 多语言翻译伪原创。你,只需输入 关键词
功能范围
1.按关键词采集Internet文章翻译伪原创,是站长朋友的首选。
2.适用于信息公关公司采集筛选、提炼信息材料
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。
虎女营销永久会员
支付宝扫描
微信扫一扫>奖励领取海报链接

