解决方案:网页文章自动采集工具-网络爬虫,接口自定义!
优采云 发布时间: 2022-10-10 18:08解决方案:网页文章自动采集工具-网络爬虫,接口自定义!
网页文章自动采集工具-网络爬虫,接口自定义。关注“少数派”后回复“爬虫”获取。它就是互联网中各种信息类网站的文章页和评论页自动抓取工具,简单易用,大大提高我们整理工作效率。还可以对几乎所有网站进行搜索引擎爬虫的爬取。可以自定义采集网站的内容,如公众号文章、抖音文章、知乎文章等内容。即使你不会写爬虫,也可以充分享受爬虫的乐趣。
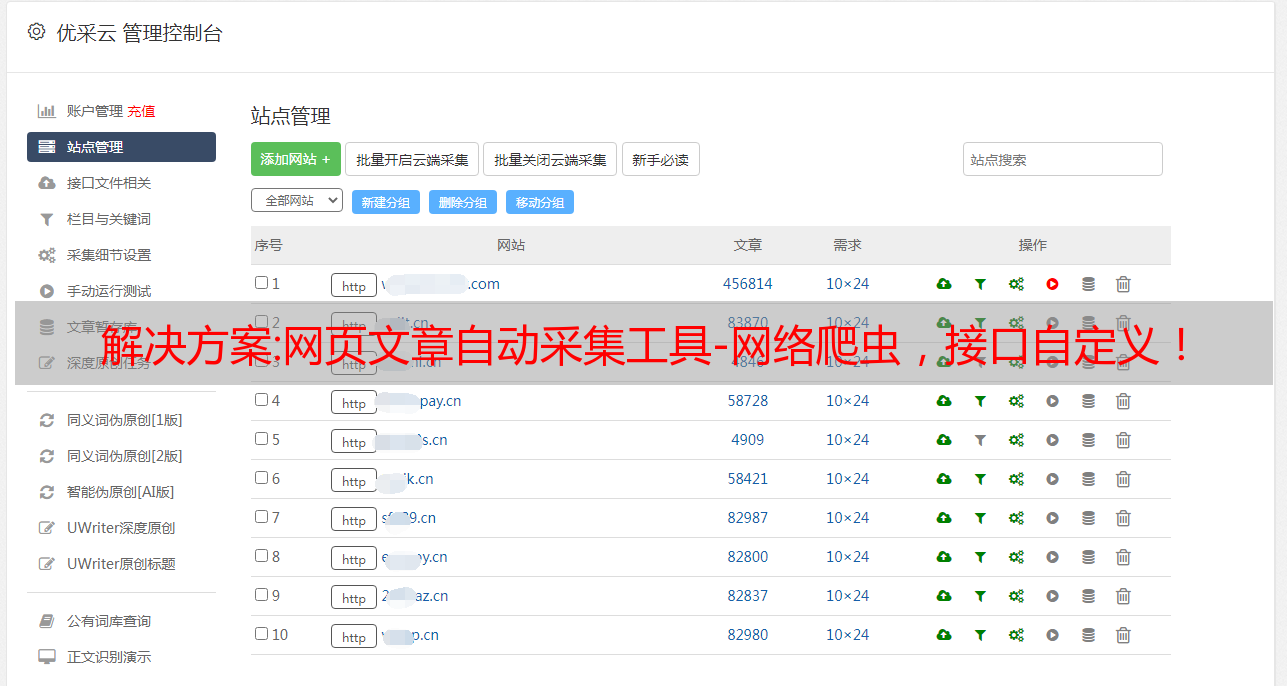
毕竟有时候,抓取文章,是可以当一个学习小老师的。下面给大家带来这个工具的一些用法和细节。主要用的chrome。1.准备工作下载在网络上一般提供了多种可用的工具。例如chrome插件、谷歌浏览器插件、360浏览器插件等。下载chrome网络爬虫插件,请下载该工具对应的chrome扩展,然后安装。这个插件是每个浏览器浏览器都会自带的,也可以通过第三方浏览器插件商店。
安装了chrome网络爬虫插件后,打开浏览器的主页,会发现有所不同。主页如下:此时,你可以选择左侧功能区的「扩展」按钮,去添加其他的插件。下面是少数派定制的完整的chrome网络爬虫编辑教程。同时为了让爬虫的扩展更加合理,还可以添加若干扩展,例如可以添加知乎文章爬取、微信文章爬取、豆瓣文章爬取等。(右侧图片中的工具已经在少数派回复过,保存自己的网址有什么奇怪的?)2.工具编辑每一个抓取到的文章页面、评论页面,它都必须要包含原始的页面和评论页,并且是文章标题和评论人作者的作者名单,否则它就只会获取到页面一部分而已。
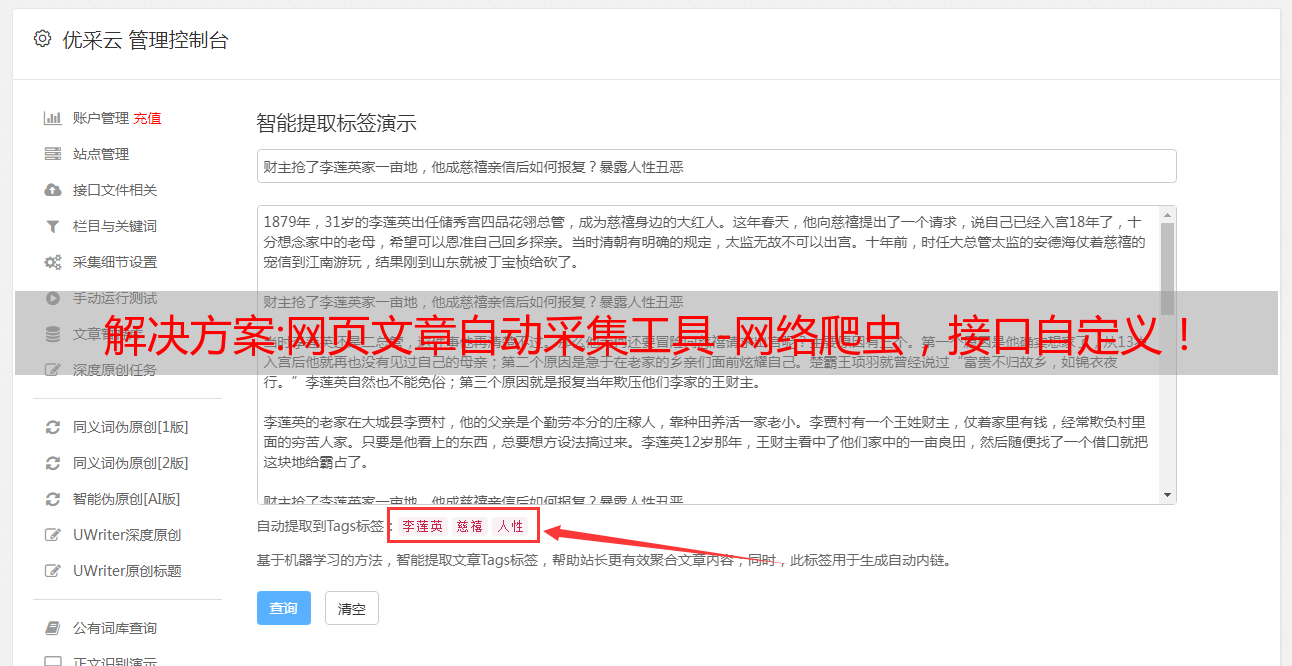
接下来给大家介绍几种方法。01.手动打开页面手动打开页面会有大量的点点点,此时你需要在浏览器的工具栏「扩展」里选择要抓取的页面。然后点击「进入页面抓取」按钮。此时,页面将加载到内存,后续将以缓存的形式保存在本地。需要注意的是,在浏览器里双击页面进入编辑页面,编辑评论页面的时候,评论是无法显示的。那么需要怎么在评论页抓取呢?02.爬虫内部代码如果你把爬虫定制好了,此时需要在评论页面编辑评论页的内容,并选择文章引用的资源。
此时,编辑此页面的代码。此时,评论页面内容被抓取到response对象中,我们可以通过response对象获取到原始的页面源码,接下来可以用xpath来获取每一段文字,进行爬取。03.爬虫配置最后还需要给爬虫的配置保存到本地,否则它就会以缓存的形式保存。此时,我们可以通过requests库来爬取到评论页,并对配置保存到本地。
3.采集报道作者看点你不能爬取任何评论,因为即使是知乎也可能被好几个小编甚至“职业作者”攻击。就算爬取了知乎文章评论,但知乎更改了新的文章结构,它仍然会被其他文。

