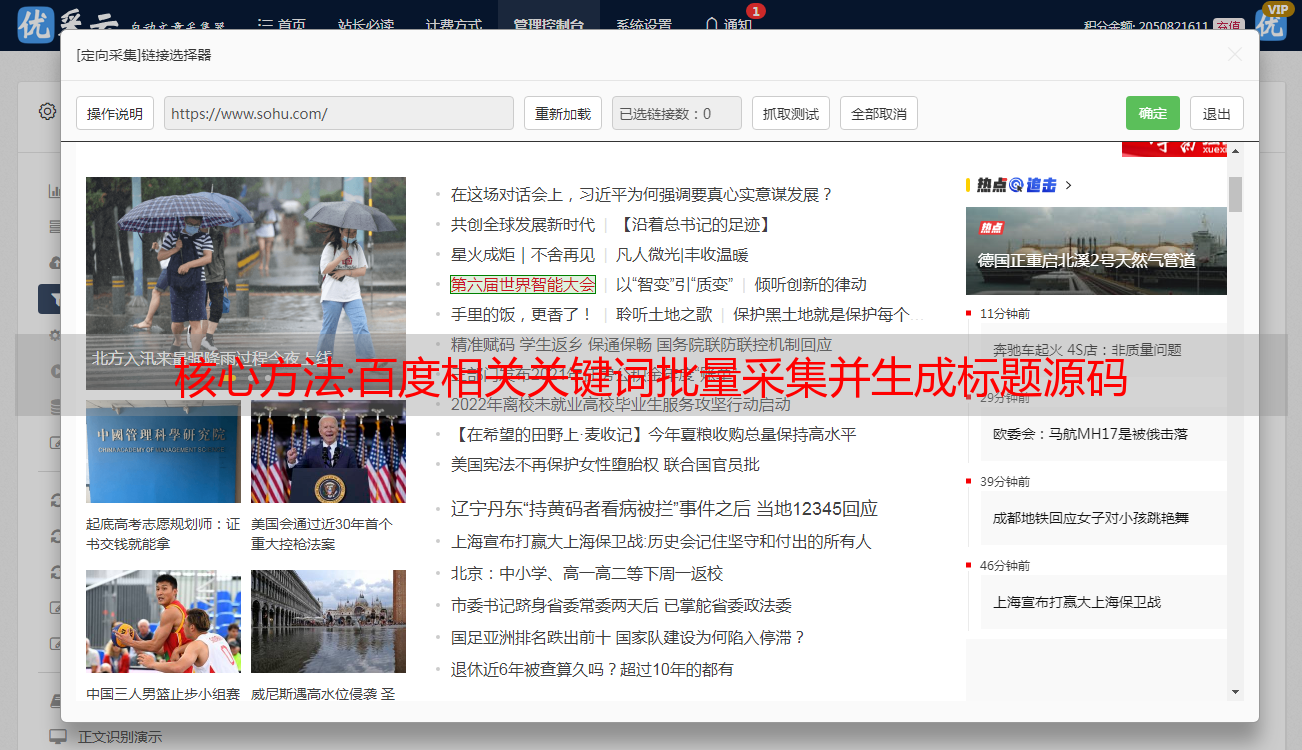
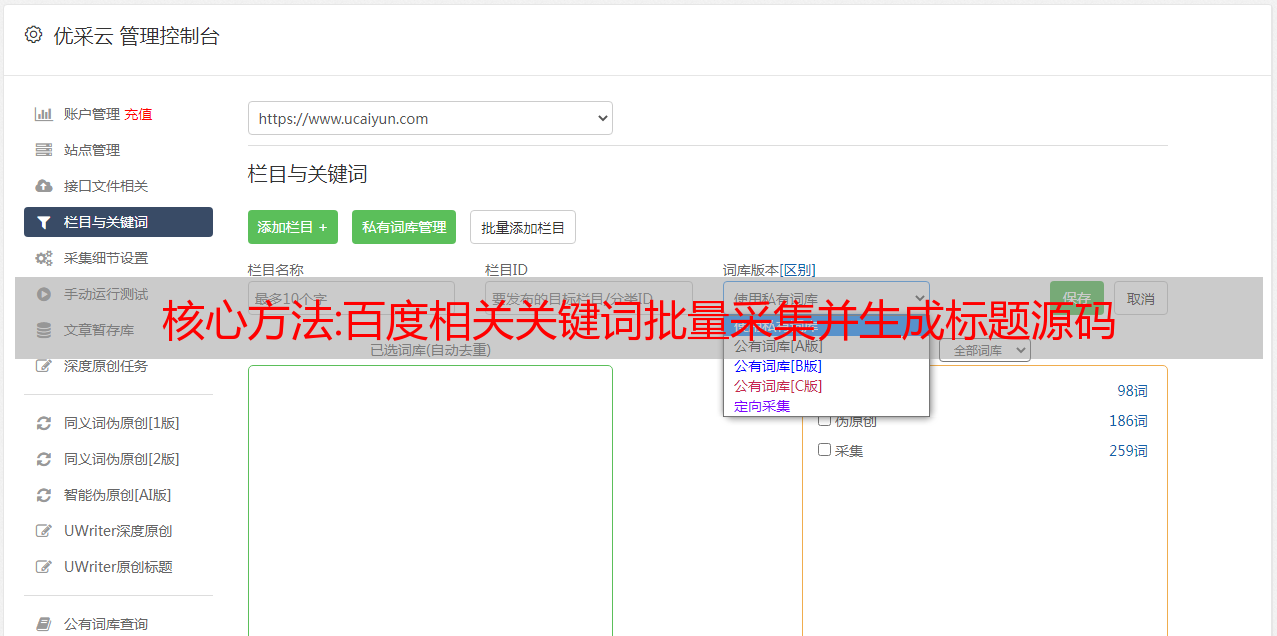
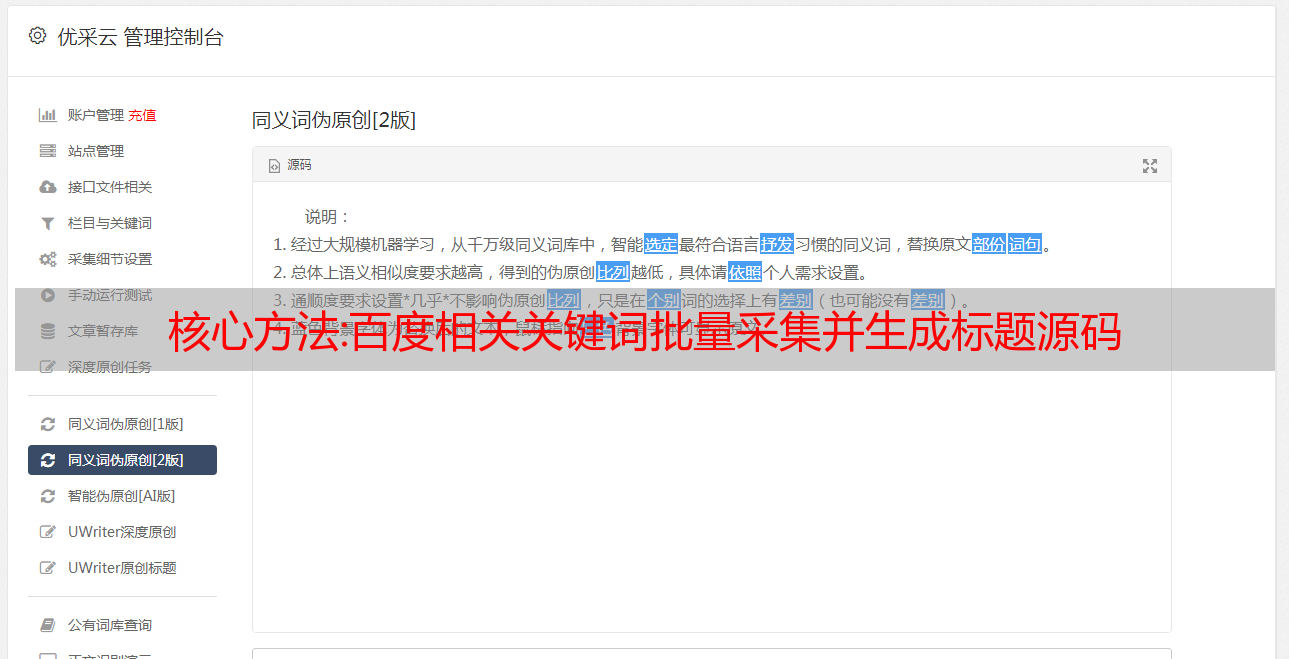
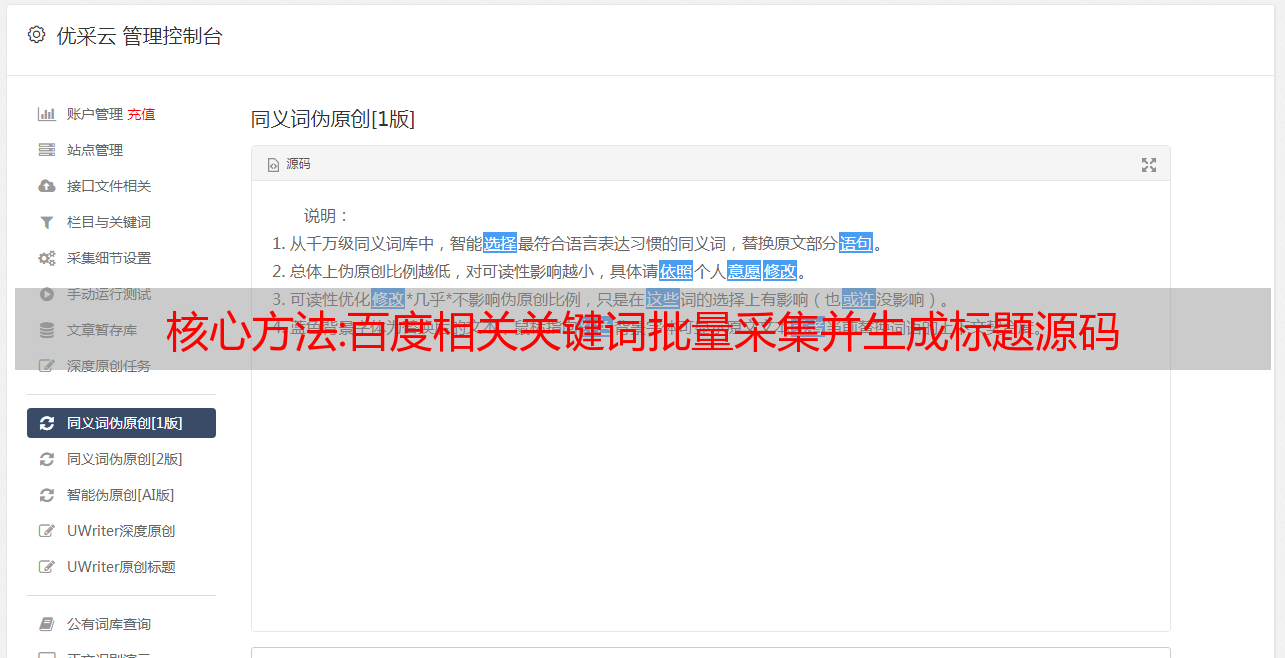
核心方法:百度相关关键词批量采集并生成标题源码
优采云 发布时间: 2022-10-10 06:11
嗡嗡声一个咬人的嗡嗡声标题*敏*感*词*。API 有一个想法来制作 Buzzfeed...buzzfeeder?惊人!这是如何做到的。该函数应该利用单词函数来获取标题的随机复数单词。例如, word() + ' 很有趣!将返回一个随机单词,后跟“It's fun!”。使用 str(num) 获取随机数。这对于诸如“狗令人惊叹的 26 个原因”之类的头条新闻非常有用!将您的函数添加到随机字典中。基本上只需将 1 添加到 d 最高编号的键并将其用作您的键。该值应该只是您的函数的名称(而不是字符串!)。创建一些 Buzzfeed-y。任何我认为 unBuzzfeedlike 的东西都不会被接受。提交拉取请求!请。
成熟的解决方案:采集亚马逊全部类型数据的完整开源解决方案
Exotic Amazon 是采集整个网站 的完整解决方案,开箱即用,包括大多数 Amazon 数据类型,并将永久免费和开源。
其他电商平台数据采集的方法和流程基本类似,业务逻辑可以在本项目的基础上进行修改和调整。它的基础设施解决了*敏*感*词*数据面临的所有问题采集。
困难与挑战
在反爬方面,亚马逊基本采用常见的反爬方式,如cookie跟踪、IP跟踪、访问频率限制、访问轨迹跟踪、CSS混淆等。
使用 selenium、playwright、puppeteer 等浏览器自动化工具。采集Amazon 数据也会被检测到。puppeteer-extra、apify/crawlee等工具都提供了WebDriver隐身功能,所以这个问题在一定程度上得到了缓解,但还没有完全解决。
上述工具并不能解决访问轨迹跟踪的问题。检测到无头模式。如果爬虫在云端运行,为了提高性能,通常不安装GUI,但即使WebDriver不可见,也可以检测到无头模式。
即使解决了以上问题,在*敏*感*词*采集下还是有很多困难:
如何正确轮换 IP?其实仅仅轮换IP是不够的,我们提出了一个叫做“隐私上下文轮换”的概念,如何用单台机器每天提取上千万的数据点?如何保证数据的准确性?如何保证调度的准确性?如何保证分布式系统的弹性?对于使用 CSS 混淆的字段,它的 CSS Path/XPath 可能每个网页都不一样,Regex 也不容易提取。在这种情况下如何正确提取字段?
幸运的是,现在,我们有开源成熟的解决方案。
得益于 PulsarR(中文)提供的完整的 Web 数据管理基础设施,整个解决方案由不超过 3500 行的 kotlin 代码和不到 700 行的 X-SQL 组成,可提取 650 多个字段。
*敏*感*词*审查 - 每日更新开始
git clone https://github.com/platonai/exotic-amazon.git
cd exotic-amazon && mvn
java -jar target/exotic-amazon*.jar
# Or on Windows:
java -jar target/exotic-amazon-{the-actual-version}.jar
打开 System Glances,一目了然地查看系统状态。
抽取结果处理抽取规则
所有提取规则都是用 X-SQL 编写的。数据类型转换和数据清洗也由强大的 X-SQL 内联处理,这也是我们开发 X-SQL 的一个重要原因。一个很好的 X-SQL 示例是 x-asin.sql,它从每个产品页面中提取 70 多个字段。
将提取结果保存在本地文件系统中
默认情况下,结果以 json 格式写入本地文件系统。
将提取结果保存到数据库
有几种方法可以将结果保存到数据库中:
将结果序列化为键值对,并将其保存为 WebPage 对象的字段。WebPage是整个系统的核心数据结构。将结果写入兼容 JDBC 的数据库,例如 MySQL、PostgreSQL、MS SQL Server、Oracle 等。自己编写几行代码,将结果保存在您希望的任何地方 技术特点

