分享:哪里找自媒体文章素材?自媒体素材怎么找?自媒体素材采集工具
优采云 发布时间: 2022-10-09 20:11分享:哪里找自媒体文章素材?自媒体素材怎么找?自媒体素材采集工具
还和运营中的几位大佬合作,每天免费分享最新的自媒体实操讲解,还免费获得自媒体实操资料一份。
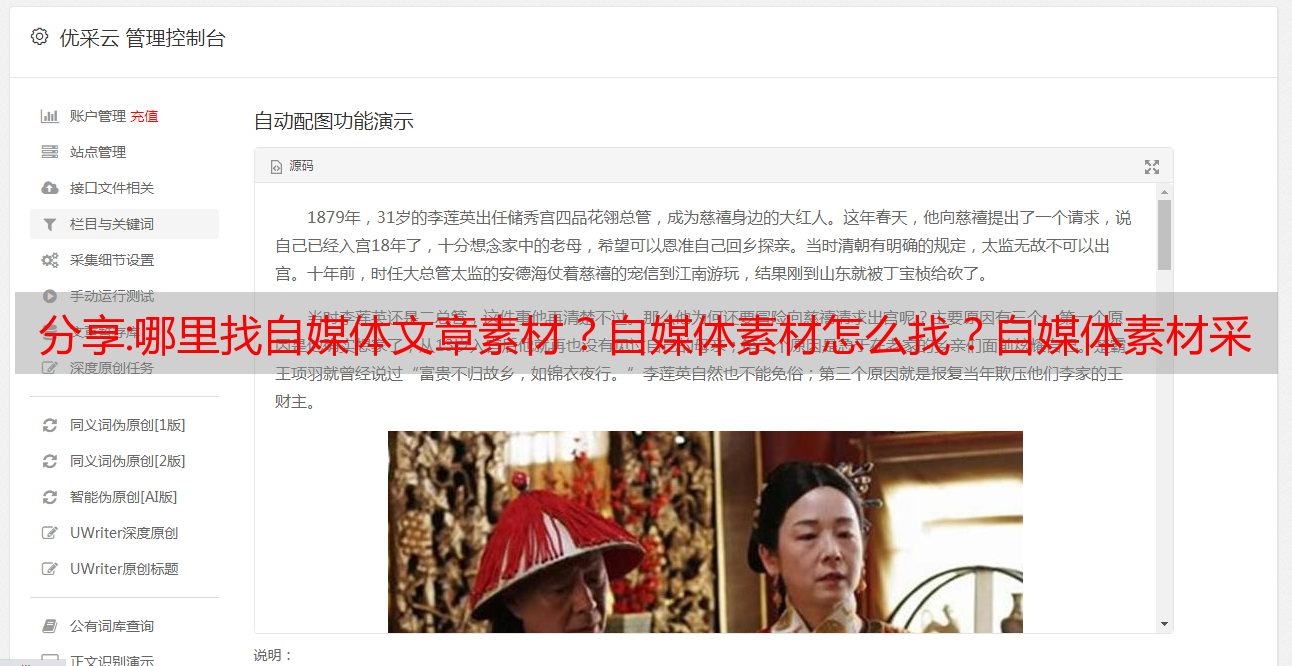
如果你没有时间和精力去分析采集各大媒体平台的实时热点,那么你需要一个好用的自媒体爆文采集工具——宜赞。该工具通过数据挖掘技术采集各大自媒体平台的实时信息。
点击爆文数据,通过综合分析,我们将其传递给您。我们可以通过不同的选择条件,快速获取各大平台的实时热点数据。
阅读更多 文章
在这个信息爆炸的时代,我们其实无时无刻不在阅读,知识阅读的渠道和方式各不相同。有些人通过 Moments 阅读 文章,有些人在 网站 上阅读 文章。
无论我们阅读文章的内容是什么,总会给我们一些印象,然后我们可以通过分析和修改来创造一个好的文章。
常用的方法:一种文章采集的方法
专利名称:一种文章采集方法
技术领域:
本发明涉及一种为各种网站文章自动采集的方法。
背景技术:
文章采集是根据用户定义的关键词字从各个网站中检索相关数据,并进行合理的拦截、分类、去重和过滤,然后保存作为文件或数据库。文章采集应用的关键是如何从众多的网站中获取到所需的准确内容到预期的中央资源库,然后快速使用。文章采集的核心技术是模式定义和模式匹配。模式属于人工智能的术语,是对前人积累的经验的抽象和升华。简单地说,它是从反复发生的事件中发现和抽象出来的规则,是解决问题的经验总结。只要是一遍又一遍地重复的东西,就可能有规律。文章采集 的大部分模式都不会被程序自动发现。目前几乎所有的文章采集产品都需要手动定义。但是模式本身是一个非常复杂和抽象的内容,所以开发者的全部精力都花在了如何让模式定义更简单更准确上,这也是衡量文章采集的技术竞争力> 。目前使用较多的是正则表达式定义和文档结构定义。传统的文章采集有几个问题: 1、采集是整个文章,需要手动页面处理才能使用;2、不能分栏采集;3. 采集 仅支持单个站点;4、采集的文章不能自动套用自己的网站格式发布,需要手动处理。
发明内容
本发明的目的是提供一种文章采集的方法,支持网站组的多站点采集,并且可以对采集进行分段采集 @文章和采集的子栏采集、文章可以自动套用自己的网站格式发布,无需人工处理。一种文章采集的方法,具体包括以下步骤:首先选择采集的来源,使用正则表达式制定采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容与目标站点的栏目绑定;启动采集文章时,首先搜索采集的来源,使用多线程技术,执行网站群组多站点采集; 根据设置的采集规则,将内容采集存放在对应的列下;如果需要自动发布,则调用 文章merge 模板进行发布。使用正则表达式制定采集规则是指输入需要采集的静态页面地址,确定地址中第N个“/”为需要采集的静态文件内容的地址并自动将其转换为正则表达式规则。关键信息处理方法是指确定需要采集的内容的文章标题或关键信息的字符串位置。本发明采用正则表达式定义的方法,根据用户自定义任务配置,批量准确提取目标网络媒体栏目中的新闻或文章,并转化为结构化记录(标题、作者、内容、采集时间、来源、分类、相关图片等),存储在本地数据库中供内部使用或外网发布,快速实现外部信息的获取,以及针对各类网站新闻采集@采集具有更快的速度和更高的精度。本发明可以自动和手动两种模式运行,系统定期自动将最新信息更新到指定站点,手动提供及时触发机制;它支持不同的信息采集使用不同的模式。本发明对文章采集的传统技术进行了改进,真正满足了用户的应用需求。;2. 每列可以自定义对应的采集任务,文章采集会自动存储在对应的列下;3.采用多线程技术支持网站组 4.结合模板弓引擎技术,文章采集可以自动套用网站模板自动发布。
如图。附图说明图1是本发明的逻辑流程图。
如图。图2为本发明实施例采集内容的字符串位置*敏*感*词*。下面结合附图和具体实施例对本发明作进一步详细说明。
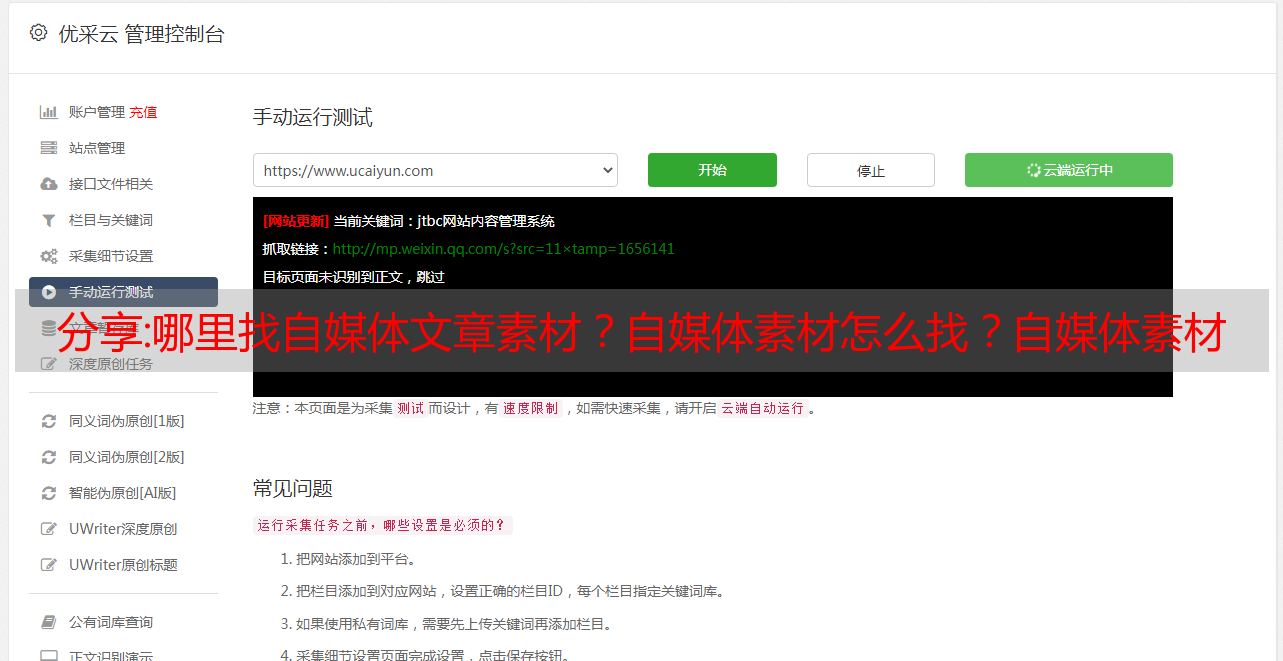
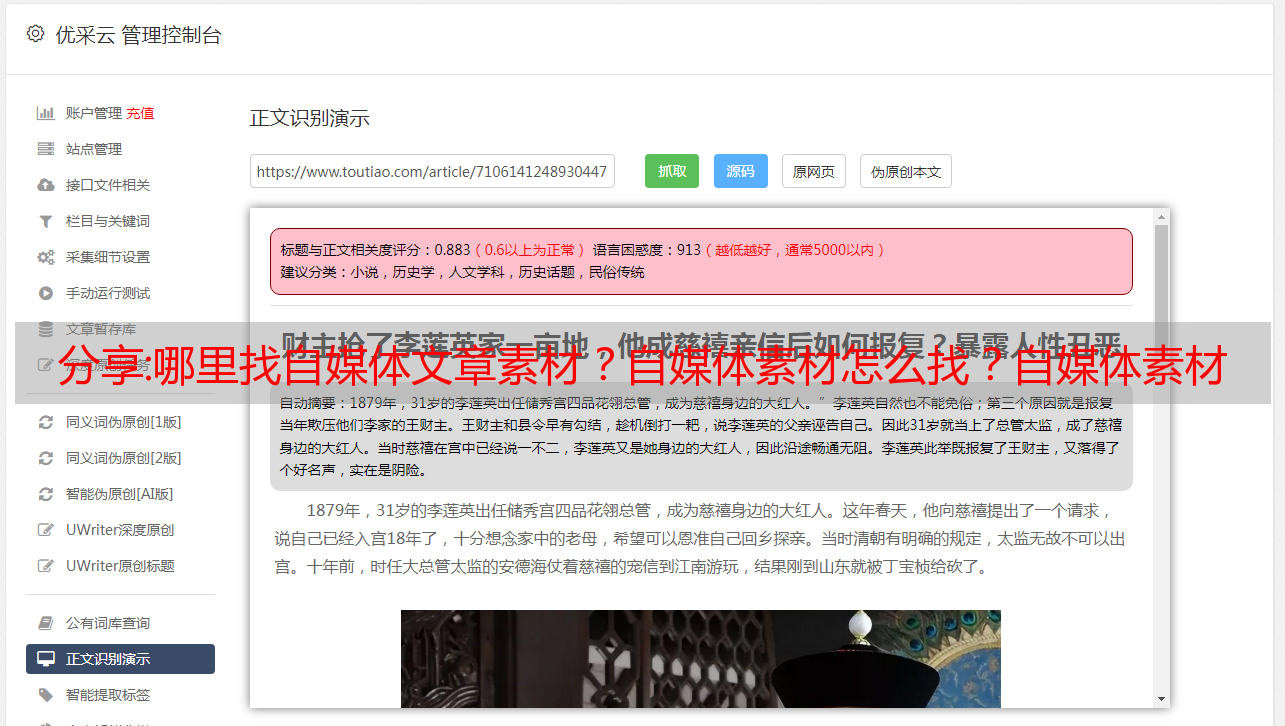
具体实施方式如图1所示。如图1所示,本发明的文章采集的方法具体包括以下步骤:首先选择采集的来源,利用正则表达式制定采集规则,使用确定采集内容范围的关键信息处理方法,并将采集的内容绑定到目标站点的列。使用正则表达式制定采集规则是指输入需要采集的静态页面地址,路径指向页面某列中的某一列为采集 >文章,判断第N个“/”开头的内容,自动转换成正则表达式规则。满足表达式规则的静态文件的内容将是 采集。关键信息处理方法是指确定采集内容的文章标题或关键信息的字符串位置(以图2为例)。由于每个网站的内容放置位置不同,所以在配置采集时,需要先找到想要的采集内容的字符串位置,采集才能准确获取数据. 采集的内容与目标站点的栏目的绑定是在采集的配置中,用户需要选择自己所属的栏目,或者在创建栏目时,用户可以选择指定的文章模板,启动采集时,通过栏目找到指定的文章模板,发布时合并生成静态页面。启动采集文章时,先搜索采集的来源,使用多线程技术,对网站进行多站点采集分组;根据设置的采集规则,将采集接收到的内容存放到对应的列中;如果需要自动发布,则调用 文章 合并模板进行发布。文章 合并模板是指动态的 文章 数据通过调用模板引擎生成静态 HTML 页面。以上所述仅为本发明的较佳实施例而已,并不用于限定本发明的技术范围。因此,任何微小的修改,根据本发明的技术实质,对上述实施例所作的等同变化和修改,仍在本发明的保护范围之内。在本发明技术方案的范围内。
权利请求
1.一种文章采集的方法,其特征在于,包括以下步骤,首先选择采集源,采用正则表达式制定采集规则,使用关键信息处理方法确定采集的内容范围,将采集的内容绑定到目标站点的列;启动采集文章时,首先搜索采集的来源,使用多线程技术,进行网站group-multi-site采集;根据设置的采集规则,将内容采集存放在对应的列下;如有必要要自动发布,请调用 文章 合并模板以发布。
2.根据权利要求1所述的一种文章采集的方法,其特征在于,所述采用正则表达式制定采集规则,表示输入需要采集静态页面地址,确定第N个“/”的地址为需要为采集的静态文件内容的地址,并自动转换为正则表达式规则。
3.根据权利要求1所述的一种文章采集的方法,其特征在于,所述关键信息处理方式,是指确定需要采集的文章 content 标题或关键信息的字符串位置。
全文摘要
文章采集的一种方法,首先选择采集的来源,用正则表达式制定采集规则,用关键信息处理方法确定的内容采集 作用域,将采集的内容绑定到目标站点的列;启动采集文章时,首先搜索采集的来源,利用多线程技术进行网站群的多站点采集 ; 根据设置的采集规则,将采集接收到的内容存放在对应的列中;如果需要自动发布,调用文章组合模板发布;本发明根据用户自定义任务配置,批量准确提取目标网络媒体栏目中的新闻或文章,并将它们转换为结构化记录以供内部使用或外部使用。在线发布可以快速实现外部信息的获取,对各类网站新闻采集具有更快的速度和更高的准确率。
文件编号 G06F17/30GK102096705SQ20101061842
发布日期 2011 年 6 月 15 日 申请日期 2010 年 12 月 31 日 优先权日期 2010 年 12 月 31 日
发明人曾文宇、林亚山申请人:南威软件*敏*感*词*

