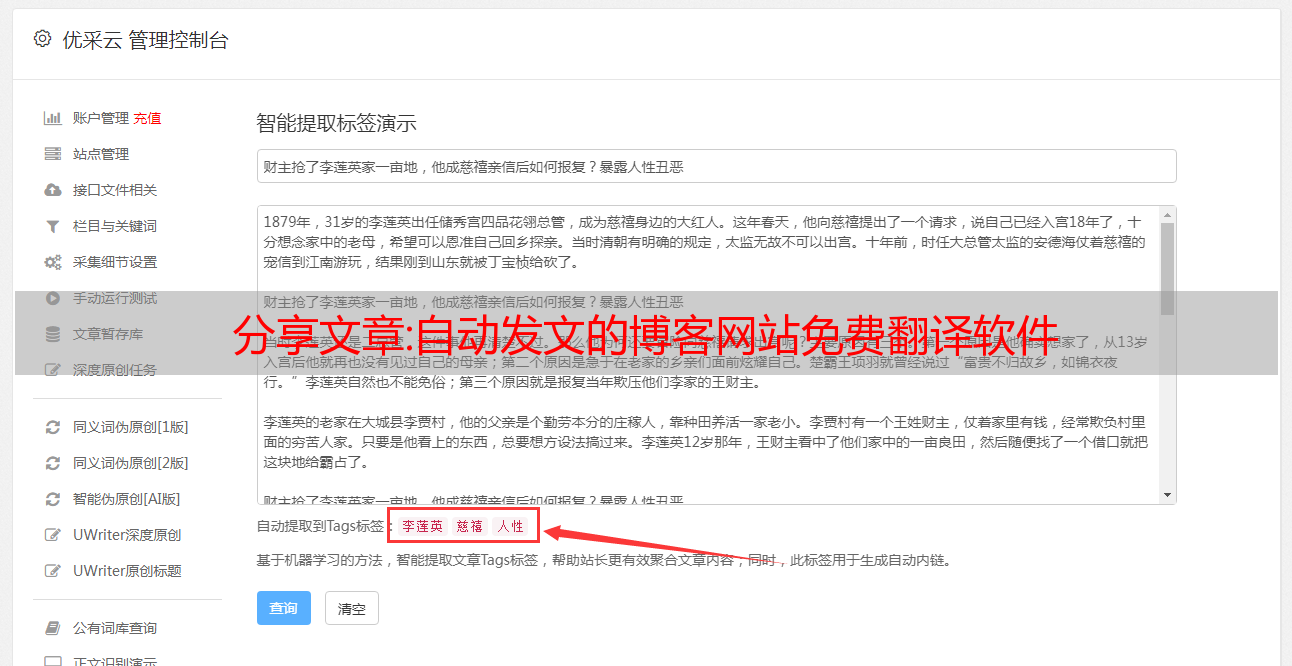
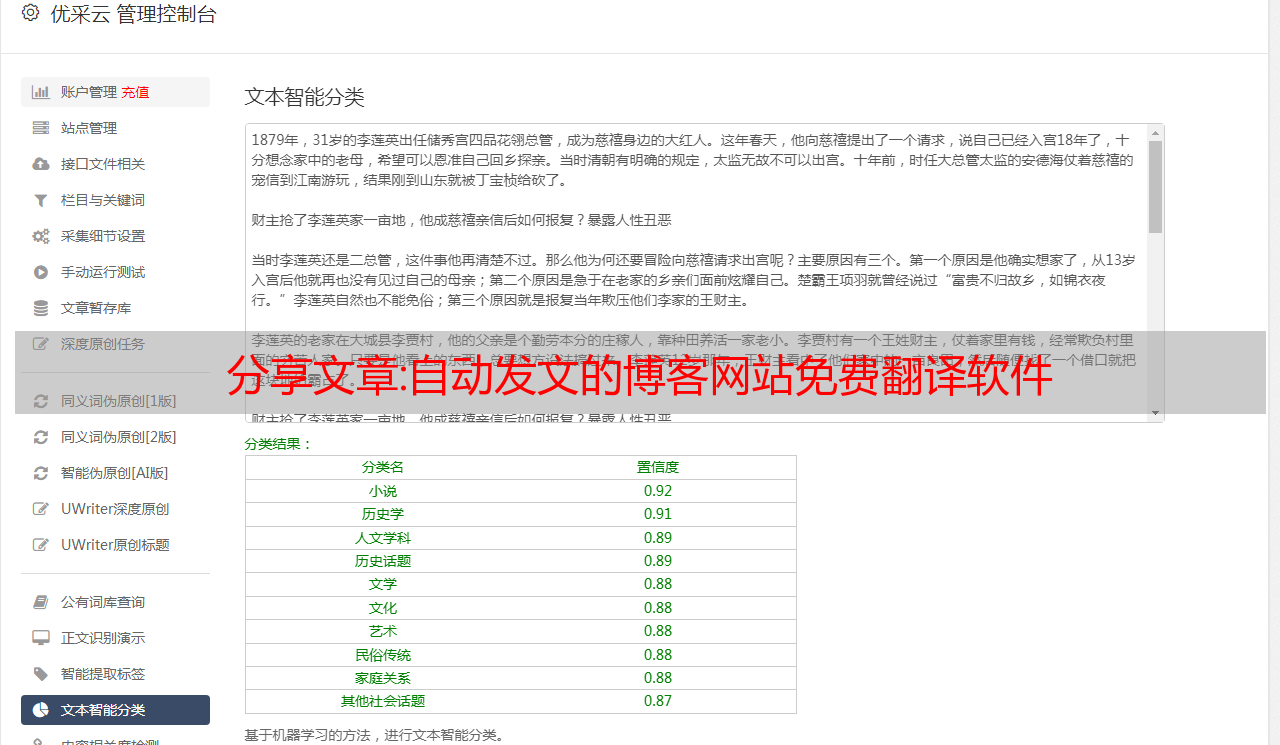
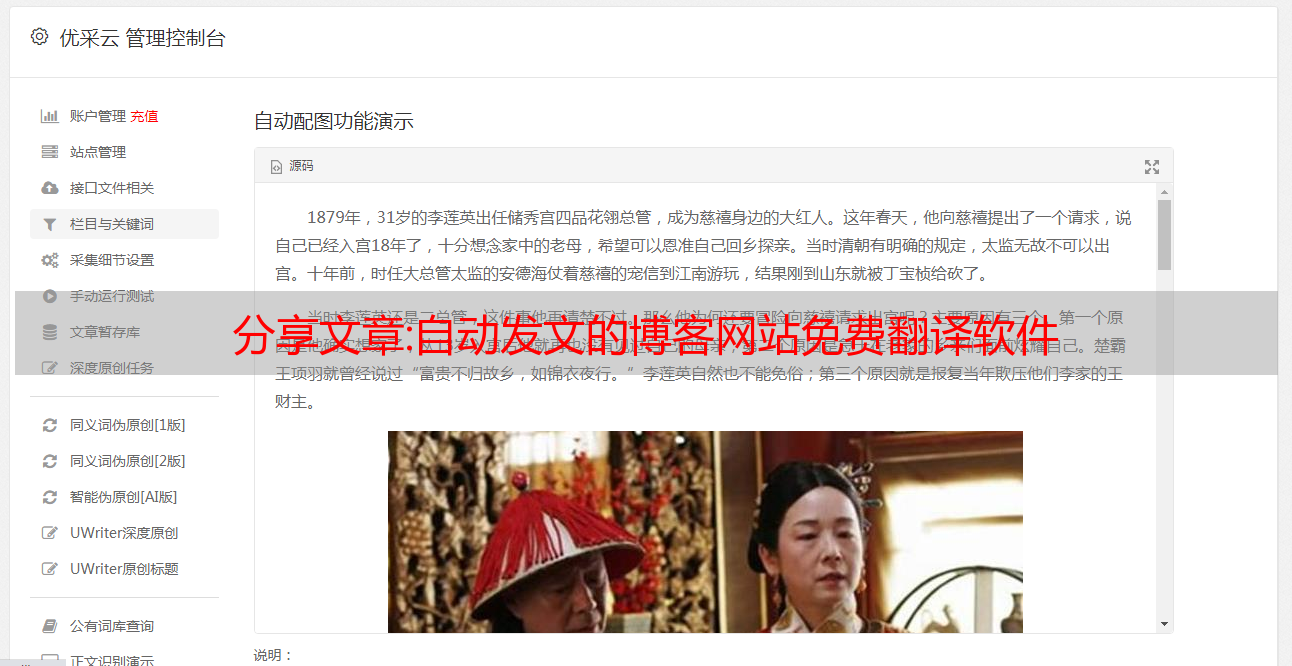
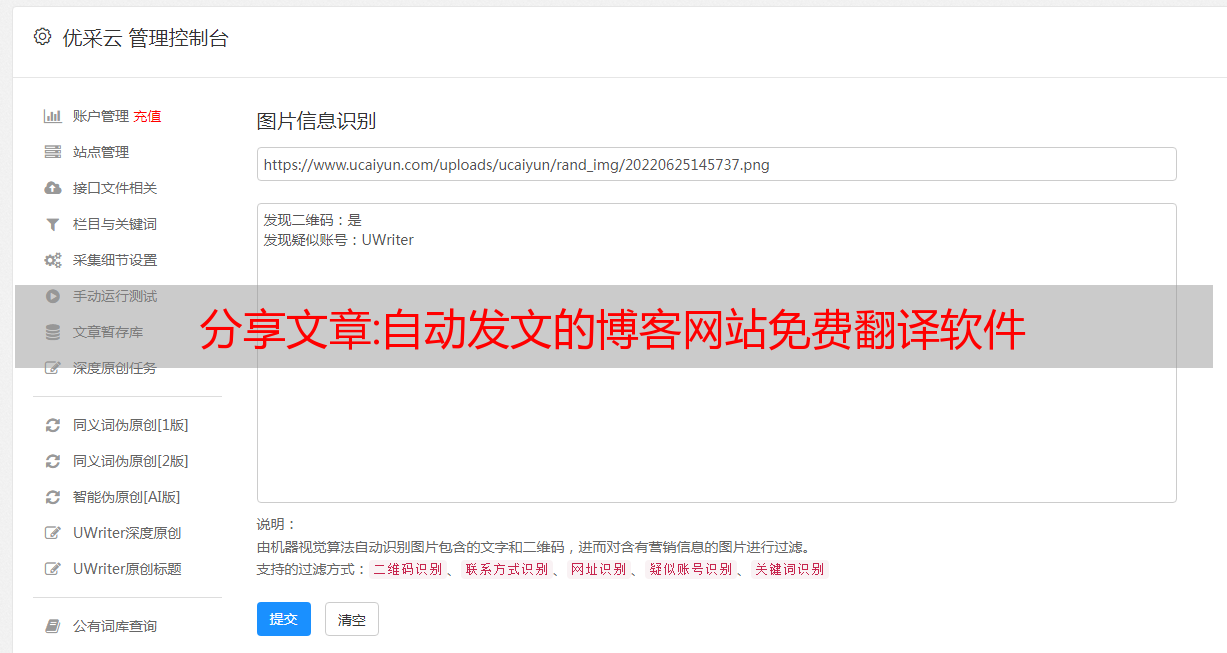
分享文章:自动发文的博客网站免费翻译软件
优采云 发布时间: 2022-10-09 16:21分享文章:自动发文的博客网站免费翻译软件
博客网站翻译工具支持我们的WordPress、typecho、zblog等cms构建的各种博客网站的文章的翻译和发布。本地文档的多语言翻译和批量编辑,内容的段落优化,插入图片,设置关键词锚文本等,让我们发布的文章有利于网站的SEO。
博客网站翻译工具在我们的网站内容管理中还具有全网采集、自动伪原创、多语言翻译、发布后推送搜索引擎等功能. 功能的自由组合,让我们可以根据自己博客网站的特点,打造专属的SEO。
博客网站翻译工具可以在我们的英文页面上进行采集,操作简单,不需要我们掌握正则表达式等,只需点击我们需要采集的元素,即可然后目标 网站 前进到 采集。通过采集不同语言的素材网站并批量翻译,我们可以轻松获取更多原创素材。
正如我们与 SEO 所讨论的那样,博客 网站 在 2022 年需要更多的变化和更清洁的技术。每个人都在努力提高排名,所以人们在用户体验和 SEO 方面工作在很多方面,搜索引擎越来越好,并且有掌握了这些技能。
随着搜索引擎在检测低质量内容方面做得越来越好,对高质量博客的需求对我们的 网站 进行高度排名变得越来越必要。真正重要的是经过充分研究的内容,让读者有理由留在我们的页面上。我们可以有一个 2,500 字的 文章,但如果它不提供信息、不好且不可读,那么它对 SEO 不利。
现实情况是,平均而言,较长的内容会获得更多的反向链接、更多的社交分享和更多的自然流量。然而,这并不一定意味着写得更多就可以保证我们的博客能做到这一点。主要重点应该放在引人入胜、经过充分研究和有价值的内容上。话虽如此,我们可以对更短的内容进行排名,但它遵循前面提到的指导方针。
我们将看到标签是数据或 HTML 代码中的关键字和短语。其中一些数据与排名关系不大,但在点击率方面仍然很有价值。例如,让我们看一下描述。我们的 网站 描述大约有 160 个字符长,并为我们的 网站 提供描述。搜索引擎不会出于排名目的查看此信息,但它确实出现在搜索结果中。
所以描述对于点击率变得很重要。标题以及 Alt 文本(用作图像或视频的描述符)以及将我们新生成的 URL 推送到搜索引擎等方法都有助于我们的 网站 出现在 SERP 中。正如我们之前提到的,内容为王。内容是我们 网站 排名的关键,因为如果我们没有有价值的内容,我们将因流量、跳出率和其他指标不佳而失去搜索引擎对我们网站的信任。
博客网站翻译工具的分享到此结束。通过博客网站翻译工具,可以批量优化我们的博客内容。该工具只是取代了我们完成重复性工作的方式。使用SEO技巧和组合工具来提高SEO效率的灵活性是我们应该考虑的。
解密:微信公众号文章采集的入口--历史消息页详解
采集微信文章和采集网站一样,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页的链接地址。
上一篇文章中提到过,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
因此,在这个地址过期之前,我们可以通过在浏览器中查看原文来获取文章历史消息列表。如果我们想自动分析内容,还可以编写一个程序,添加key和pass_ticket的链接地址,然后通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章文章中写的批处理采集方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就可以了。
在anyproxy的web界面中,如果证书配置正确,可以显示https的内容。Web 界面的地址是 localhost 可以替换为您自己的 IP 地址或域名的地方。从列表中找到以 getmasssendmsg 开头的记录。点击后,右侧会显示这条记录的详细信息:
红框部分是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
简单分析一下这个json(这里只介绍一些重要的信息,其他的省略):
这里还要提一点,如果你想获取更旧的历史消息的内容,你需要在手机或模拟器上下拉页面。下拉到最底部,微信会自动读取下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上一篇文章文章介绍的方法,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode将json解析成一个来自服务器的数组。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集的单个公众号的内容,您可以在每天群发后通过anyproxy获取带有key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章的列表,在下一篇文章我会介绍如何根据的链接地址获取文章文章 中的历史新闻 > 内容特定的方法。关于如何保存文章、封面图片、全文检索也有一些经验。
如果您觉得我写的不是很清楚,或者有什么不明白的地方,请在下方留言。或者骚扰微信账号崔金,如果你觉得不错,就点个赞吧。
持续更新,微信公众号文章批量网站文章采集工具搭建
微信公众号入口文章采集--历史新闻页面详解
微信公众号文章页面和采集分析
提高微信公众号文章采集的效率,anyproxy的高级使用

