总结:用WordPress自动采集让网站快速收录以及关键词排名-聚合排名法
优采云 发布时间: 2022-10-09 09:14总结:用WordPress自动采集让网站快速收录以及关键词排名-聚合排名法
如何使用WordPress自动采集使网站快速收录和关键词排名,整体流程(关键词words采集+伪原创+聚合+发布+主动推送到搜索引擎)聚合由一些关键词引导,网站里面的各种相关信息,通过程序聚合关键词相关的内容在一个页面上,形成一个相对基本的主题页面。这样做的好处是可以在网站上以相对低成本、非人工的方式生成一批聚合页面。这种页面从内容相关性的角度来看,比普通页面更有优势。聚合策略不会和网站原来的页面系统冲突,只是基于网站原来的活动详情数据,并根据相关性进行二次信息聚合。因此,聚合是一组独立的、不断优化和改进的、长期运行的 SEO 内容。
1.聚合是未来的核心SEO引流策略网站:
因为网站原来的常规频道、栏目、详情页等页面数据量有限,每日更新产生的页面数量也有限,而这些页面所承载的关键词不够清晰而且数量有限。因此,如果SEO项目只依赖网站的原创页面内容,没有内容增量,很难增加网站的搜索流量。
2、我们要整体增加网站的流量:
需要解决行业用户大量的长尾需求,因为大部分流量来自行业长尾关键词。而网站原有的页面系统(频道、栏目、详情页)很难在没有规范的情况下部署各种长尾关键词。因此,这些不规则的长尾关键词只能由聚合策略生成的新页面携带。
3、它的标签目录是聚合策略的应用。
网站的标签聚合给网站带来了大量的流量。虽然目前很浅,但是涵盖了更多的长尾词流量。
综合长期目标:
不断优化和完善聚合策略的页面、页面的用户体验以及相关的用户功能,使聚合页面能够融入网站的常规页面体系,最终成为网站 常规页面,提高这些页面的性能。交易转换。实际运行中,计划让聚合系统在8个月内生成10万-15万页,解决20万-30万的落地问题关键词。
1)技术角度的聚合策略:
从技术上讲,聚合与站内搜索的原理类似,但站内搜索的条件必须细化。例如搜索:北京程序员交流。那么在过滤掉相关信息之前,我们必须同时满足北京和程序员的条件。否则,如果我们过滤掉上海程序员的交流信息,就会导致内容出现偏差。所以,从技术角度来说。聚合类似于站内搜索,但需要设置相应的条件。
2)产品视角的聚合策略:
从产品的角度来看,聚合策略会更准确的为用户找到相关信息。因为聚合策略是按关键词分类的,所以关键词代表了用户的需求。例如:北京程序员交流会。网站内部没有这样的分类,但是我们可以通过聚合策略生成这样一个非正式的渠道和栏目分类,然后用这个分类来聚合北京的程序员很长一段时间。沙龙和交流活动的信息,然后把这个分类的链接放在相关版块,就可以起到非常人性化的信息推荐的作用。因此,从产品的角度来看,聚合策略可以不断优化,
聚合页面优化策略:
1.移动策略:
建立M移动站,百度倡导的MIP站,通过这三个方面,加强聚合策略的移动优化策略,使聚合系统的页面能够有效获得移动搜索流量,这也是迎合了搜索引擎的移动搜索。
2. 规划相关页面的TKD关键词格式非常重要。主要是通过TKD来承载整个聚合策略的整体词库。
3. URL 应该使用伪静态的方法建立搜索友好的 URL 格式,以方便聚合页面的索引。
4.构建聚合策略页面之间的关联网站结构和聚合策略页面与主站点页面之间的关联网站结构。通过优化这两点的关联结构,可以大大提升聚合策略页面的SEO效果。
5、内容要以整个站点的底层数据为基础,注意解决聚合时相似关键词之间的内容重复问题。
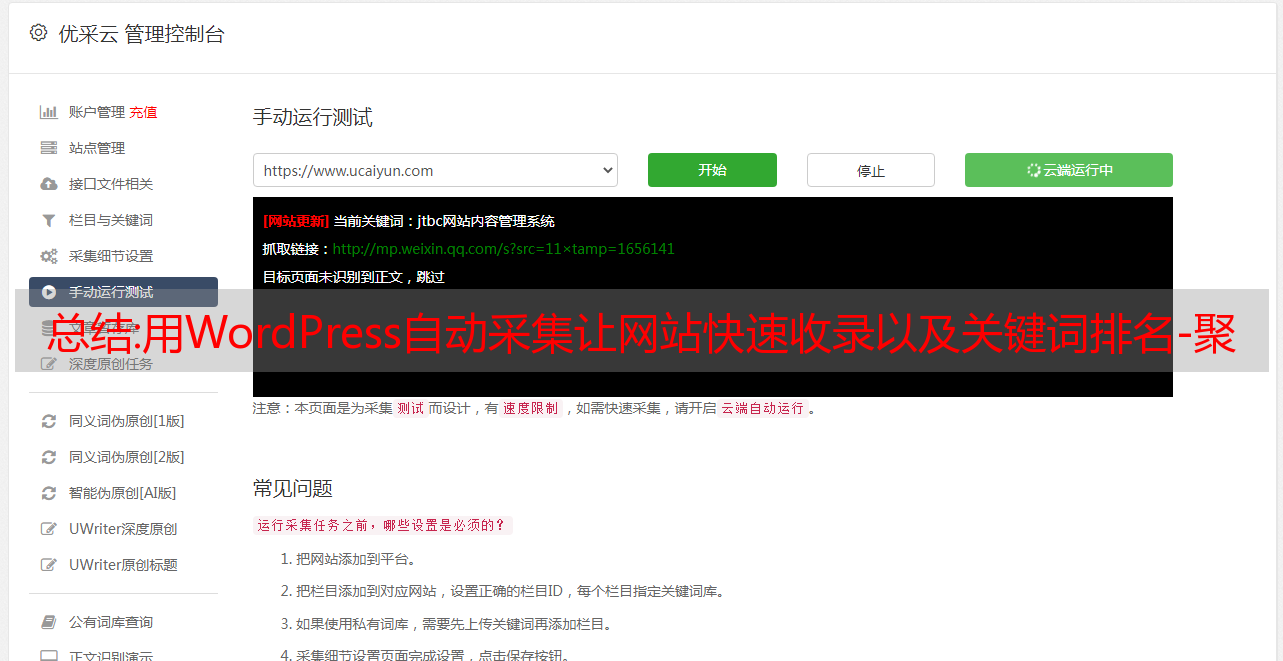
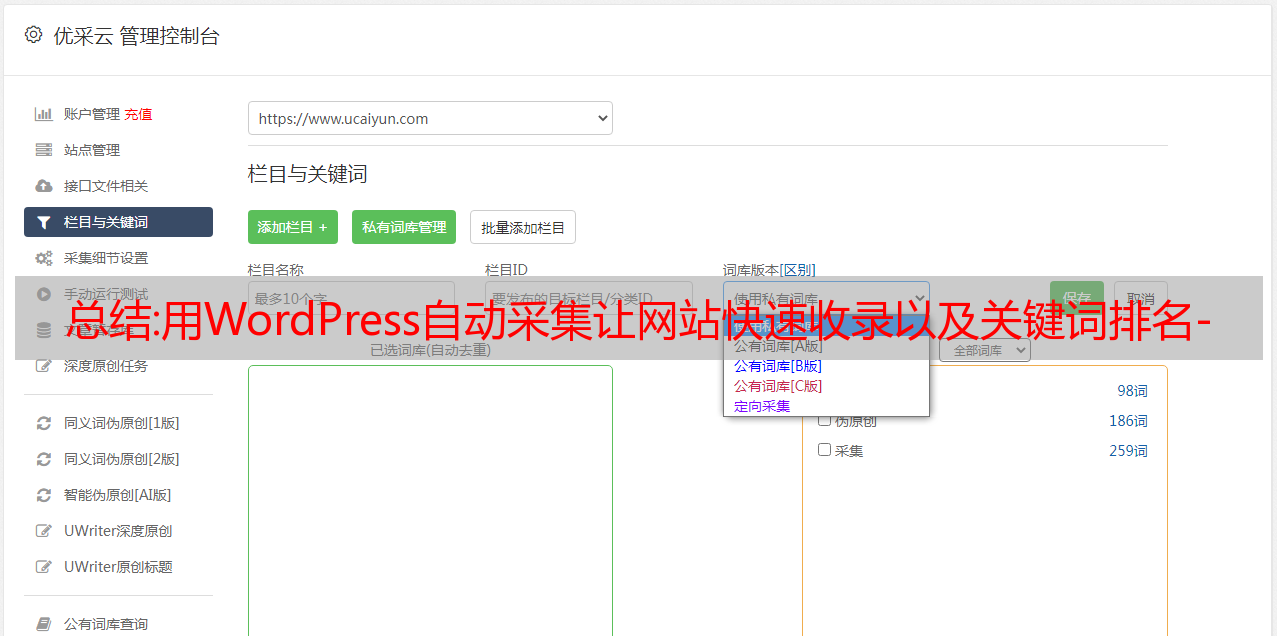
6.了解具体思路后,我们可以利用这个WordPress自动采集实现采集大量的内容,网站快速收录和排名,这个WordPress自动采集操作简单,无需学习更多专业技术,只需几个简单步骤即可轻松采集内容数据,用户只需在WordPress自动采集工具上进行简单设置,该工具将根据用户设置的关键词设置关键词准确采集文章,以保证与行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
相比其他的WordPress自动采集这个WordPress自动采集基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词实现采集(WordPress自动采集也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
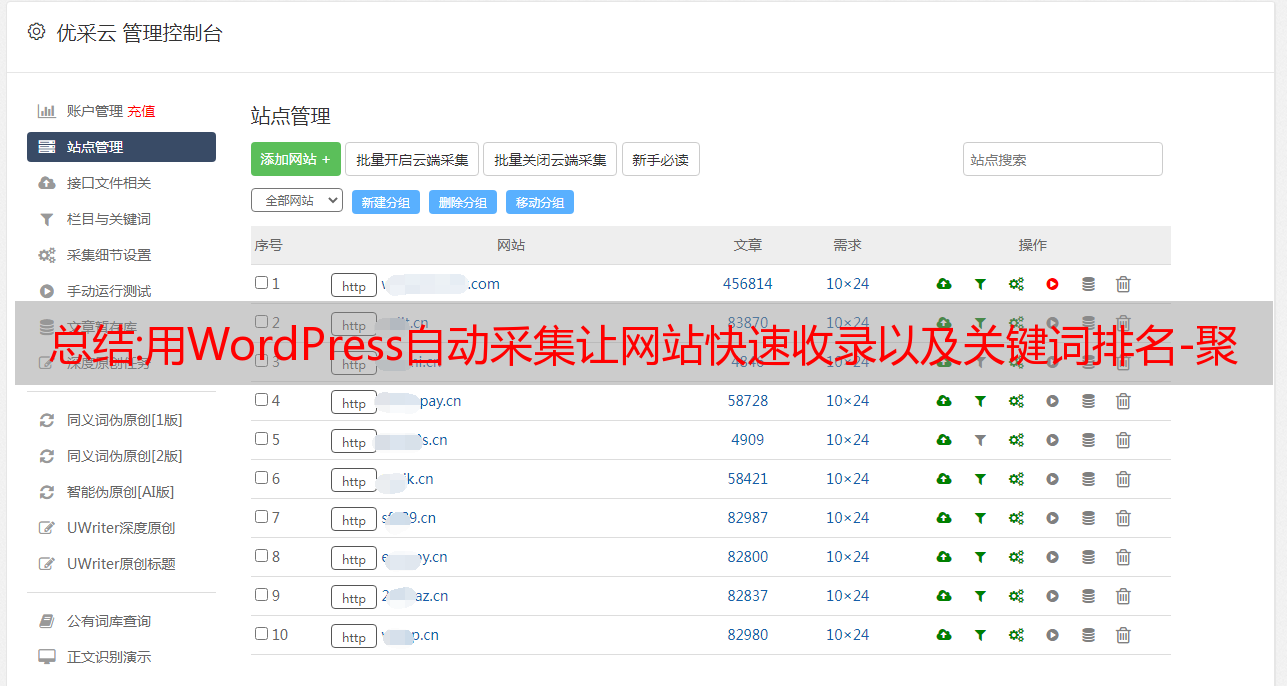
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这款WordPress自动采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1.网站主动推送(让搜索引擎更快发现我们的网站)
2.自动匹配图片(文章如果内容中没有图片,会自动配置相关图片)设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3.自动内部链接(让搜索引擎更深入地抓取您的链接)
4.在内容或标题前后插入段落或关键词(可选将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6.定期发布(定期发布文章让搜索引擎准时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台天。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
在网站的优化过程中,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多方面。比如网站的TDK选型部署、关键词的密度控制等现场优化,网站内部结构是否简单合理,目录层次是否过于复杂,等等,以及外部优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都不容忽视。, 任一方面的问题都可能导致 网站 整体不稳定。如何在网站优化中使用基本标签来达到想要的效果?
1.html标签
HTML标签是提升SEO优化效果最基本的东西。因此,在使用它们的过程中,一定要熟悉各个标签的含义和用法,还需要注意标签的嵌套使用。一般来说,双面标签是成对出现的,所以必须写上结束标识符,而单面标签也应该以反斜杠结尾。代码的完整性一定要很好体现,因为搜索引擎访问的不是前端文本,而是网站后端代码,通过网页标签网站来理解和解释,所以代码必须以标准化的方式编写。
2.nofollow标签
nofollow标签在SEO优化中的主要作用是告诉搜索引擎“不要关注这个页面上的链接”或者“不要关注这个特定的链接”,这将有助于我们防止网站的分散权重。具有重大意义的链接,例如联系页面、在线咨询等,可以使用nofollow标签妥善处理。当然,有时为了更好的引导用户,会建立很多引导链接,比如:more、details等可以通过nofollow来合理处理,从而为网站的优化带来极好的效果。
三、元标签
Meta标签在SEO中有着非常重要的作用:设置关键词,利用首页的设置关键词赢得各大搜索引擎的关注,增强网站收录,以及提高访问量和曝光度,此时最关键的设置是关键词和描述。一般情况下,搜索引擎会先发送一个机器人自动检索页面中的关键词和描述,添加到自己的数据库中,然后根据关键词的密度对网站进行排序,所以一定要认真对待网站关键词的选择,选择正确的关键词,提高页面的点击率,提升网站的排名。
四、标题标签
标题标签在SEO优化中的作用主要是分析关键词,让用户能够非常详细地把握页面的主题,所以标题标签的好坏不仅直接影响搜索引擎的响应对网站的评价也会影响用户体验的效果,因为在开发title标签的过程中一定要小心。
五、标签
标签的目的是将相关的结果放在一起。虽然是自由无拘无束,但也可以随意写,需要按照分类的角度来写。另外,这里清远易丰SEO建议Tags的字数控制在4-6个字符以内,千万不要变成句子,而且一旦确认,后期不要轻易修改,所以每次修改它,您必须等待搜索引擎重新收录 并重新赋予权重。
总之,网站这些方面的影响是非常明显的。如果这五点写得不好,很容易让用户误以为网站没有自己想要的内容,不点击就跳过了。,自然会影响网站的CTR。尤其是当网站排名位置都是自己同类网站的时候,就非常明显了。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
完整的解决方案:python项目实战之CMDB自动化资产扫描
运维模块:了解运维工作,Linux系统基本操作,数据库基本管理操作,网络知识等。
开发模块:本项目的重点是掌握Python的基础知识、常用数据类型、Django框架的技术模块,
DevOPS 项目构建块等。
2 项目开发步骤
创建一个 Django 应用程序
$ python manage.py startapp scanhosts
文件配置设置`
# settings.py
# 1). 将新建的APP加入到项目中
INSTALLED_APPS = [
......省略部分
'django.contrib.staticfiles',
'scanhosts',
]
# 2). 配置数据库: 使用mysql数据库,而不是默认的sqlite数据库。
# DATABASES = {
#
'default': {
# 'ENGINE': 'django.db.backends.sqlite3',
# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
#
}
# }
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'devopsProject',
# 数据库名称
'USER': 'devops', # 用户名
'PASSWORD': 'westos', # 用户密码
'HOST': '127.0.0.1', # 数据库服务器所在主机名
'PORT': '3306', # 数据库端口
}
}
# 3). 语言和时区的设置(根据自己项目的需求, 选择修改)
# LANGUAGE_CODE = 'en-us'
# TIME_ZONE = 'UTC'
LANGUAGE_CODE = 'zh-hans' # 语言选择中文
TIME_ZONE = 'Asia/Shanghai' # 时区选择亚洲/上海
3 项目开发(一)信息采集接口的实现 3.1 url设计
配置URL,当用户访问URL:8000/sendinfos时,将用户请求交给user_info
查看函数处理。
# first_devops/urls.py
urlpatterns = [
path('admin/', admin.site.urls),
url(r'^sendinfos/$', user_infos),
]
3.2 视图功能的实现
# scanhosts/views.py
def user_info(request):
# request.META 是一个Python字典,包含了所有本次HTTP请求的Header信息,比如用户IP
地址和用户Agent(通常是浏览器的名称和版本号)
ip = request.META.get('REMOTE_ADDR')
user_agent = request.META.get('HTTP_USER_AGENT')
# 使用filter()方法对数据进行过滤, 返回的是列表, 列表元素是符合条件的对象。
user_obj = UserIPInfo.objects.filter(ip=ip)
# 如果没有找到,则新建UserIPInfo对象,并获取对象编号(为了和BrowseInfo表关联)
if not user_obj:
res = UserIPInfo.objects.create(ip=ip)
user_ip_id = res.id
else:
user_ip_id = user_obj[0].id
# 新建BrowseInfo对象
BrowseInfo.objects.create(user_agent=user_agent, user_ip_id=user_ip_id)
# 字典封装返回的数据信息
result = {
'STATUS': 'success',
'INFO': 'User Info',
'IP': ip,
'User-Agent': user_agent
}
# 以json的方式封装返回, 下面的两种方式任选一种.
# return
HttpResponse(json.dumps(result),
content_type='application/json')
return JsonResponse(result)
3.3 浏览器访问
您可以尝试其他浏览器,看看它们是否返回不同的结果。
浏览器访问完成后,访问MySQL数据库,查看数据信息采集是否通过ORM成功写入数据库。
[root@foundation0 ~]# mysql -udevops -p
Welcome to the MariaDB monitor.
Commands end with ; or \g.
MariaDB [(none)]> use devopsProject;
MariaDB [devopsProject]> select * from user_IP_info;
MariaDB [devopsProject]> select * from browse_info;
4 项目开发(二)信息获取接口的实现 4.1 url设计
配置URL,当用户访问URL:8000/getinfos时,将用户请求交给user_history
查看函数处理。
# first_devops/urls.py
urlpatterns = [
path('admin/', admin.site.urls),
url(r'^sendinfos/$', user_info),
url(r'^getinfos/$', user_history),
]
4.2 视图功能的实现
# scanhosts/views.py
def user_history(request):
<p>
# 获取UserIPInfo表的所有对象信息;
ip_lists = UserIPInfo.objects.all()
infos = {}
# 获取每个IP访问网站浏览器的信息, 格式如下:
"""
infos = {
'127.0.0.1' : ['UA-1', 'ua-2'],
'172.25.254.1' : ['UA-1', 'ua-2'],
}
"""
for item in ip_lists:
infos[item.ip] = [b_obj.user_agent for b_obj in
BrowseInfo.objects.filter(user_ip_id=item.id)]
result = {
'STATUS': 'success',
'INFO': infos
}
return JsonResponse(result)
</p>
5 Django项目日志管理
在编写程序的过程中,难免会出现一些问题。程序没有像我们预期的那样运行。这个时候,我们通常
将调试程序以查看问题所在。程序日志是帮助我们记录程序运行过程的帮手,
善用日志的程序员,也能快速的发现自己程序的问题,快速解决。
MySQL、Redis、nginx、uWSGI等服务器级组件中都有对应的日志文件,都在运行的进程中。
将一些信息写入日志文件。
Django使用python内置的模块logging来管理自己的日志,包括四个组件:logger Loggers、log
处理程序、日志过滤器和日志格式化程序格式化程序。
5.1 配置日志信息
# first_devops/settings.py
# 日志管理的配置
LOGGING = {
'version': 1,
# disable_existing_loggers是否禁用已经存在的logger实例。默认值是True.
'disable_existing_loggers': False,
# formatters: 定义输出的日志格式。
'formatters': {
'verbose': {
# 格式化属性查看资料:
https://docs.python.org/3/library/logging.html#logrecord-attributes
'format': '{levelname} {asctime} {module} : {lineno} {message}',
# 变量的风格
'style': '{',
# 日期显示格式
'datefmt': '%Y-%m-%d %H:%M:%S',
},
},
# handlers定义处理器。
'handlers': {
'file': {
# 日志处理级别
'level': 'INFO',
# 日志处理类, 详细的请查看网站:
https://docs.python.org/3/library/logging.handlers.html
'class': 'logging.FileHandler',
# 日志处理后输出格式
'formatter': 'verbose',
# 记录日志的文件名, 存储在当前项目目录下的devops.log文件
'filename': os.path.join(BASE_DIR, 'devops.log')
},
},# loggers定义logger实例。
'loggers': {
'django': {
# 对应的handles对象列表
'handlers': ['file'],
# logger实例输出的日志级别
'level': 'INFO',
# 日志是否向上级传递。True 向上级传,False 不向上级传。
'propagate': True,
},
}
}
5.2 写日志
修改视图函数的逻辑内容,在合适的位置添加日志输出,方便程序测试和故障排除。
重新访问网页,查看devops.log文件,测试日志是否写入成功
6 Django项目邮件提醒管理
在 Web 应用中,服务器向客户端发送电子邮件,通知用户一些信息,这可以通过电子邮件来实现。帖子在 Django 中可用
软件界面使我们能够快速搭建一个邮件发送系统。通常用于发送自定义消息或通知警报等信息(当然
也可以使用短信接口或微信接口,方便维护人员快速响应)。
6.1 在服务器端开启smtp协议支持(这里以QQ邮件服务器为例)
6.2 客户端配置设置文件
# first_devops/settings.py
# 邮件配置
EMAIL_HOST = 'smtp.qq.com'
EMAIL_HOST_USER = 'QQ邮箱'
EMAIL_HOST_PASSWORD = '登录授权码(注意: 不是登录密码)'
EMAIL_PORT = 465
EMAIL_SUBJECT_PREFIX = 'Python开发社区'
EMAIL_USE_SSL = True
6.3 在Django的交互环境中测试邮件是否发送成功
$ python manage.py
shell
>>> from django.core.mail import send_mail
>>> help(send_mail)
>>> send_mail(subject="Django邮件发送测试代码", message='邮件发送测试成功',
from_email='发送人的邮箱地址', recipient_list=['接收人的邮箱地址1', '接收人的邮箱地
址2'])
1
6.4 检查邮箱是否收到测试邮件 6.5 编写封装SendMail的类
# first_devops/scanhosts/utils/tools.py
import logging
<p>
from django.core.mail import send_mail
from datetime import datetime
from first_devops import settings
class SendMail(object):
"""发送邮件的封装类"""
def __init__(self, subject, message, recipient_list, ):
# 给每个邮件的标题加上当前时间, 时间格式为年月日_小时分钟秒_传入的邮件标题
subject_time = datetime.now().strftime('%Y%m%d_%H%M%S_')
self.recipient_list = recipient_list
self.subject = subject_time + subject
self.message = message
def send(self):
try:
send_mail(
subject=self.subject,
message=self.message,
from_email=settings.EMAIL_HOST_USER,
recipient_list=self.recipient_list,
fail_silently=False
)
return True
except Exception as e:
logging.error(str(e))
return False
</p>
6.6 在Django自带的交互环境shell中测试'
$ python manage.py
shell
>>> from scanhosts.utils.tools import SendMail
>>> mail = SendMail('Django 测试标题', '邮件正文内容', ['976131979@qq.com'])
>>> mail.send()
True
五秒 DevOPS 项目 1 个带有多个配置文件的 Django 项目
1.1 base.py文件:基础配置文件,复制原seeings.py文件的内容。(参考第一个devops项目)
配置数据库
配置时区和语言
1.2 development.py文件:开发环境的配置文件
from .base import *
DEBUG = True
1.3 production.py文件:生产环境的配置文件
from .base import
*
# 开发环境一定要关闭调试模式
DEBUG = False
# 允许所有主机访问
ALLOWED_HOSTS = ['*']
1.4 修改manage.py文件。默认设置文件是当前项目中的设置文件。如果是开发环境,修改如下:
def main():
os.environ.setdefault('DJANGO_SETTINGS_MODULE',
'devops.settings.development')
# ......此处省略代码
if __name__ == '__main__':
main()
1.5 如果项目以后需要上线,将启动项目访问的配置文件修改为生产环境的配置文件,如下:
def main():
os.environ.setdefault('DJANGO_SETTINGS_MODULE',
'devops.settings.production')
# ......此处省略代码
if __name__ == '__main__':
main()
1.6 启动项目
$ python manage.py
runserver
Django version 2.2.5, using settings 'devops.settings.development'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
2 Django工程应用和模块加载
为了方便在一个大型Django项目中管理和实现不同的业务功能,我们会在项目中创建多个APP来实现功能。
能够。为了更方便管理APP,项目结构更清晰。可以专门创建apps目录来存放项目应用程序,专门创建的
extra_apps 存放项目第三方APP,项目结构如下:
但是在项目运行的时候,并不会自动找到apps和extra_apps子目录下创建的apps,需要在配置文件中手动配置。
修改 devops/settings/base.py 文件并添加以下内容:
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 将apps目录和extra_apps添加到python的搜索模块的路径集中
sys.path.insert(0, os.path.join(BASE_DIR, 'apps'))
sys.path.insert(0, os.path.join(BASE_DIR, 'extra_apps'))
# .........
添加成功后,进入Django项目的交互环境,查看sys.path变量的值,判断是否添加成功?
$ python manage.py
shell
In [1]: import sys
In [2]: sys.path
Out[2]:
['/home/kiosk/PycharmProjects/devops/devops/extra_apps',
'/home/kiosk/PycharmProjects/devops/devops/apps',
'/home/kiosk/PycharmProjects/devops',
# .......此处为了美观, 省略部分路径........
]
六、资产管理 1 为什么资产管理是重中之重?
资产管理是运维的基础工作;
资产管理是 DevOPS 系统的基础;
资产管理是建设自动化运维平台的基础。
7个相关代码已上传,点击链接查看
添加链接描述

