解决办法:如何安装好采集器进行爬虫自动采集就行了?
优采云 发布时间: 2022-10-08 19:07解决办法:如何安装好采集器进行爬虫自动采集就行了?
文章定时自动采集,封装好采集器进行爬虫自动采集就行了,用selenium安装java环境就好了,用浏览器登录一般是用js加载登录过程js,或者就是根据采集页自动加载带登录的信息,
scrapy+java环境,selenium,scrapyscrapystart(还是scrapyend)fromscrapy。confimportrequestfromscrapy。confimportrequest_executorfromscrapy。confimportjsonfromjsonimportjsonfromtimeimportdatetimefromtimeimportsleepselenium+seleniumimportjava。
util。http。urlmanager,scrapyfromscrapy。exceptionsimportexceptionscrapyhelpjavaseleniumhelp(windows)seleniumhelp(mac)。
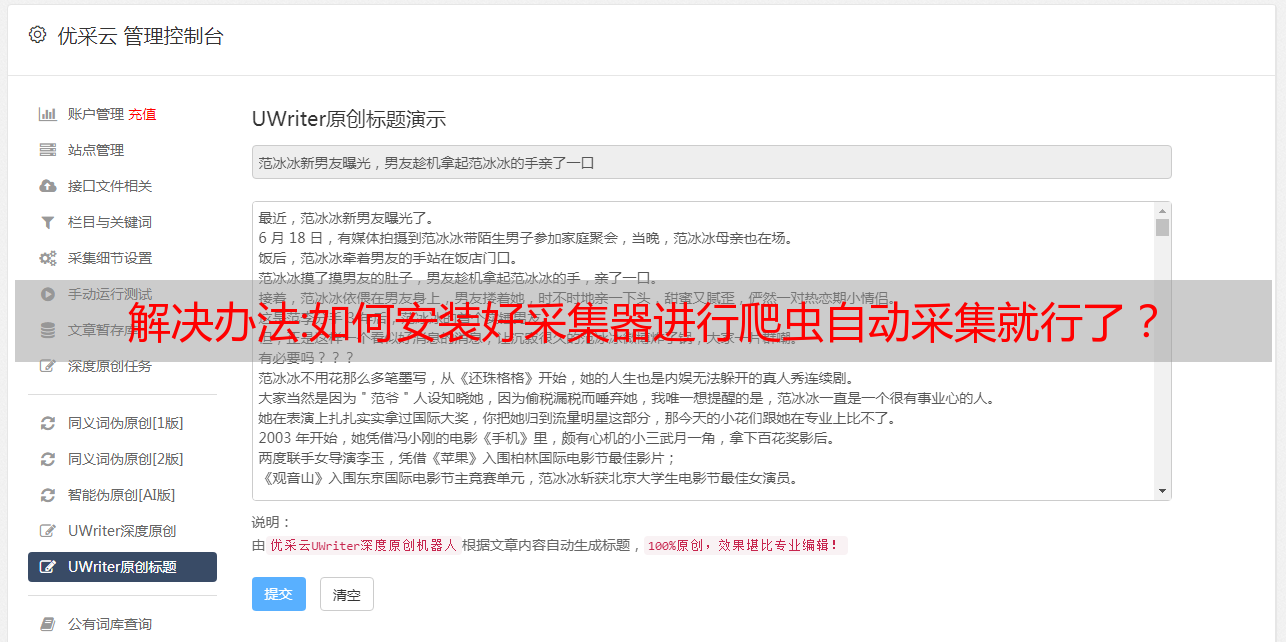
使用scrapy爬虫框架的时候,我们需要安装java环境。这里,让我们一起看看如何安装java环境。准备工作:下载java,如果你已经安装有java了,直接跳过这一步,安装scrapy等这一步。若你是学生,可以使用学校提供的免费版本java,可以免费使用。
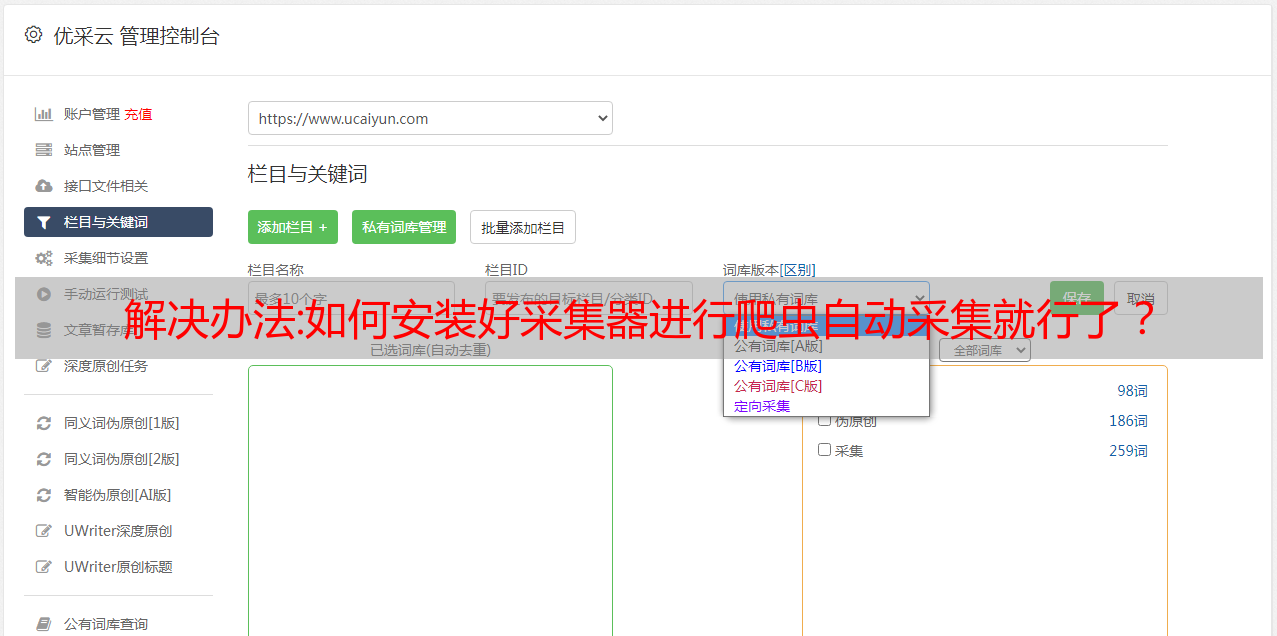
1、下载scrapy–1.13.1或者1.13.2的javajdk。为了获取最新版本,我们需要在一个目录下面。可以下载免费版本,当然也可以使用破解版本。
2、下载scrapy-1.9.2scrapy这一版本提供了我们所需要的最基本的java处理,并且有两个主要的版本,1.9.2和1.9.3。你必须下载1.9.2。因为你需要使用scrapy来连接数据库和文件。在scrapy的早期版本上,如果它不支持高级的java处理,它会发送错误。而1.9.2会帮助你连接数据库和文件。
简单的说,scrapy-1.13.3的主要优点是高性能,而不是破解版本的功能不足。如果你已经安装了java,但是需要保持java兼容性,你可以这样做。让我们看看一个不同版本的scrapy。你可以编辑.java文件看看它是否支持您的java版本。
3、scrapy安装gcc或者clanggcc或者clang安装在您要安装的java源文件上:\windows\cmd\java\cmd.exe.\gcc-java-4.0.10.msicurl.exe//yeschmod+x//yes
4、scrapy-1.13.2安装java运行java-jarscrapy.jar或者使用这些java安装器(如安装jdk-4.0.1
0)安装即可。scrapy目前正在windows和osx上都提供beta,对于macos上,要尝试启动,你可以使用命令java-jarscrapy.jar,cmd如下:java-jarscrapy.jar安装好之后,

