干货教程:优采云采集公众号文章教程规则附图片
优采云 发布时间: 2022-10-08 17:17干货教程:优采云采集公众号文章教程规则附图片
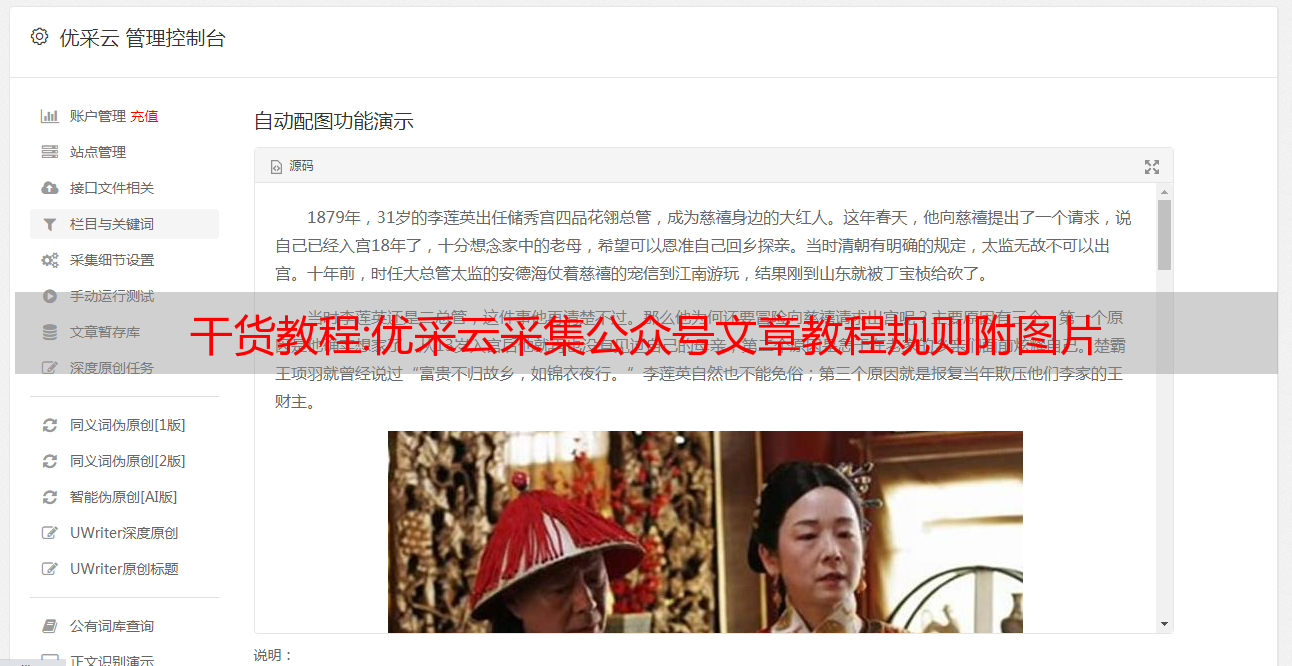
优采云采集公众号文章呢?首先我们来了解一下优采云采集的原理。优采云采集的内容主要看你写的规则。要获取一个网页的所有内容,首先需要获取该网页的URL,然后在write code标签中获取文章的标题和内容(需要HTML代码知识)。公众号的文章在电脑上无法获取列表页。结果很多人无法使用优采云采集到公众号文章,那我们如何实现采集公众号文章,如图下图(直接输入文章@关键词,选择公众号文章转采集)
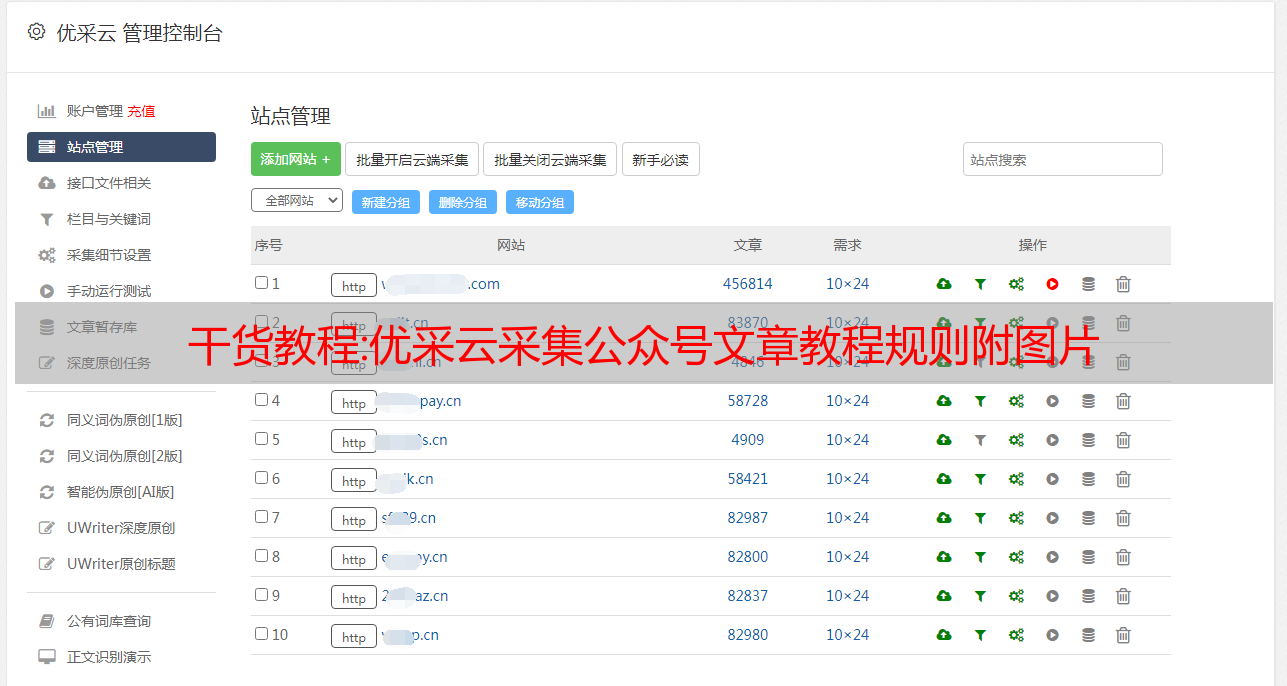
同时还支持指定网站采集:不限网页,不限内容,支持多种扩展,选什么,怎么选,全看你自己!通过三个简单的步骤轻松实现 采集 网络数据。任意文件格式导出,无论是文字、链接、图片、视频、音频、Html源代码等均可导出,还支持自动发布到各大cms网站!
网站内容构建是SEO优化者最关心的话题。不过话又说回来,在网站的构建过程中,一定要多注意采集上传优质信息到网站的方法。现在,我们来看看相关知识的介绍如何。
首先,在进行网站seo优化时,我们可以为文本采集写一个吸引人的标题。因为在新的网站运行时,客户是否会进入网站进行浏览,与标题的新颖性有一定的关系。所以我们在采集文章的时候一定要注意文章的标题和标题的吸引力,这样用户才能更好的浏览网站的内容> 。
其次,当采集文章在网站中时,必须对文章的内容进行总结。这个 文章采集 提示。它属于最流行的搜索引擎。我希望我们可以在文章的开头和结尾添加我们自己的总结词,然后把文章变成我们自己的内容。我们都知道,当采集高质量文章时,文章的头部和尾部对于文本的质量和吸引力起着极其关键的作用。
第三,网站seo优化时,采集的内容一定要保持新鲜。尤其是互联网上更新信息的速度会非常大。如果优化器在采集文章时文章的内容比较陈旧,就会让网站很难得到搜索引擎的青睐。毕竟,一些过时的 文章 内容很可能会在互联网上重复出现。这会对网站的收录造成很大的伤害,更不用说网站的权重和推广了。
四、优化网站时,网站内采集中文章的内容一定要保持较高的新鲜度,尽量保持在一天之内。最重要的是在固定时间内完成更新。
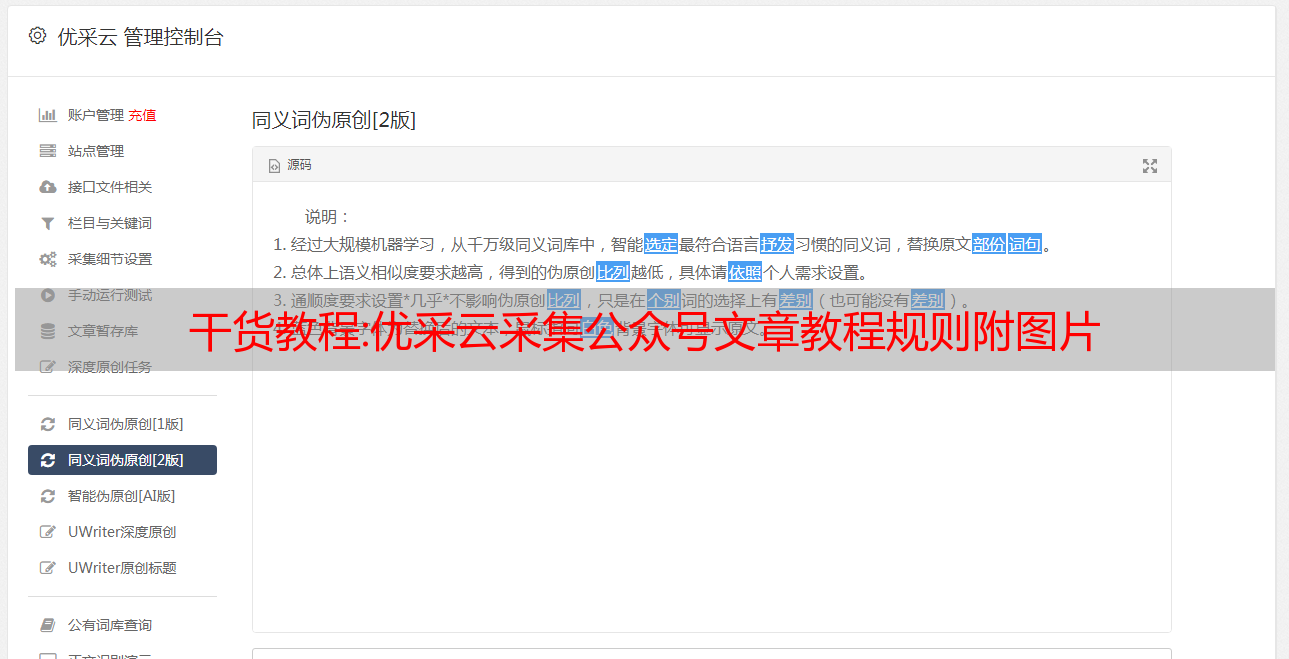
定期更新网站上的 文章 几乎是每个 网站 都会做的事情。当然,不是每一个网站都关注原创,也不是每一个网站都愿意抽空做原创的文章,很多人都是以 采集 的方式更新他们的 网站文章。不说一大批采集其他文章的网站怎么了,这里根据自己网站的实际情况,说说长期处于下控制他人采集文章的网站会有什么后果,以及如何避免被他人采集。
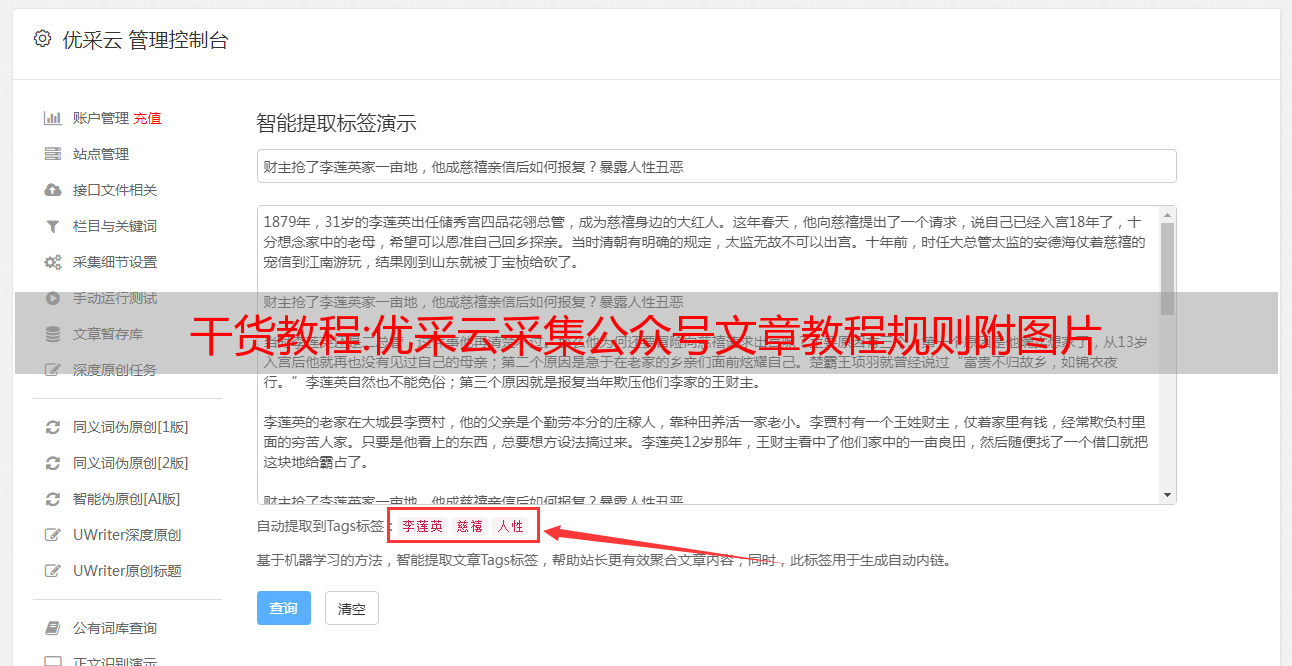
百度BaiduSpider喜欢原创的东西,但是百度蜘蛛对原创的判断还不准确,不能完全独立判断某篇文章的出处文章重点在哪里,当我们更新一篇文章文章,很快就被别人采集,蜘蛛可能同时接触到很多相同的文章,那么会很令人困惑,不清楚哪个是 原创 哪个是复制的。
所以,当我们的网站长期处于采集的状态时,我们网站上更新的文章大部分在网上都有相同的内容,而如果网站的权重不够高,蜘蛛很可能会将你的网站列为采集站,更有可能相信你的网站 >的文章是采集来自互联网,而不是互联网的其余部分是采集你的文章
我们回归搜索引擎工作原理的本质,即满足和解决用户在搜索结果时的需求。也就是说,不管你的文章是怎么来的(采集文章也可以解决用户需求)
免费获取:微信公众号文章下载器v1.61免费版
微信公众号文章下载器是ingdear制作的微信公众号文章下载工具,具有节省消息内存、节省付费文章等功能。通过这个软件,你可以得到一个公众号里所有的文章,然后把它保存为一个HTML文件。一个 文章一个 HTML 文档。
指示
1.首先关闭所有开放的公众号文章。
2、点击【①获取参数】,然后打开需要下载的公众号文章,在公众号中选择打开任意一个文章。
3、文章完全加载后,获取的参数会显示在【运行日志】中。参数获取完成后,会自动开始获取文章。
4、请不要再打开本软件。
公众号获取文章的过程
先获取必要的参数-->获取公众号的所有文章并合并到SQLITE数据库中-->然后从数据库中取出文章,下载并一一标记.
获取内容
直接保存文章的内容,不做任何处理。图片使用网络地址,没有留言保存,可以自行修改添加。
问题与解决方案
1、在获取参数时,浏览器可能会出现:【未连接:存在潜在安全问题】,无法浏览网页。
解决方法:原因可能是Fiddler的证书问题。您只需等待参数采集完成或手动停止参数采集即可恢复。
2、现有公众号文章未关闭时,点击【获取参数】,获取当前浏览文章的参数。当您想获取其他公众号的数据时,可能会出现参数错误。
解决方法:先关闭所有正在浏览的公众号文章,然后点击【①获取参数】,再打开需要下载的公众号文章中的任意一个。
3、出现提示错误类的信息问题。
解决方法:一般可以根据方法重试一次/多次。如果没有,您可以关闭该软件并重新打开它。
4.获取参数后,软件意外关闭或主动关闭,再次访问网页时提示:【服务器代表{pass}{filter}}拒绝连接。
解决方法:这是因为在获取参数时,软件会修改系统的分代{pass}{filtering}管理。如果不停止,这种世代相传的{passing}{filtering}管理将永远存在。重启软件,点击【①获取参数】,然后点击【①停止获取】。
5、获取文章时,软件意外关闭或主动关闭后,重新打开后是否会重复获取或下载之前的文章。
A:不会重复。获取到 文章 的列表时将关闭。下次重新打开后,依然会开始获取第一篇文章,发现重复自动跳过。
下载文章时关闭,下次重新打开时,会从下一个未下载的文章开始下载。
6.由于Fiddler证书安装问题,可能会出现其他未知错误。请使用搜索引擎查找相关解决方案,或提供可重现的解决方案进行回复。
7、有时打开文章后,没有完全获取到参数,采集还没有执行。
解决方法:关闭文章再打开一篇文章文章,尽量不要使用刷新,有些参数只有第一次才有。
8、软件被WIN10的安全中心删除了怎么办?
解决方法:通过安全中心添加到排除列表。
功能未实现
付费文章隐藏的不能下载,视频不能下载,音频不能下载。图片没下载,直接用图片链接地址。
下载时间
假设1000篇文章文章,如果没有错误等,下载完成所需时间:1000/10*20+1000*20=6.2小时。
获取文章列表的参数每30分钟过期一次,1000篇文章中间需要再次获取参数。
如果觉得时间太长,可以自行修改采集时间间隔。不建议太快。太频繁可能会触发微信的反采集机制,限制某个公众号的访问。
因为采集太快了,公众号的访问受限一段时间,一般第二天就会恢复。(每隔20秒测试采集几个公众号,一共几千个文章无访问限制)
注:虽然采集已测试多个公众号,但由于微信文章形式多样,可能存在采集错误或采集后的内容与原文。
更新内容
1.添加保存PDF文件 2.选择三张网络图片之一,保存本地图片和嵌入图片
3.基本配置保存在数据表中
4. 其他的我不记得了
PS:保存图片需要时间,所以保存一个文章的时间比以前长,占用的资源也更高,图片越多,时间越长
PDF和网页还是有区别的,有不小的个体差异。

