汇总:风吹雪支付系统易支付去后台验证版本代理系统个人易支付完整可运行网站源码
优采云 发布时间: 2022-10-08 13:15汇总:风吹雪支付系统易支付去后台验证版本代理系统个人易支付完整可运行网站源码
免费下载或者VIP会员资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接用于商业用途。如因商业用途发生版权纠纷,一切责任由用户承担。更多信息请参考VIP介绍。
提示下载完成但无法解压或打开?
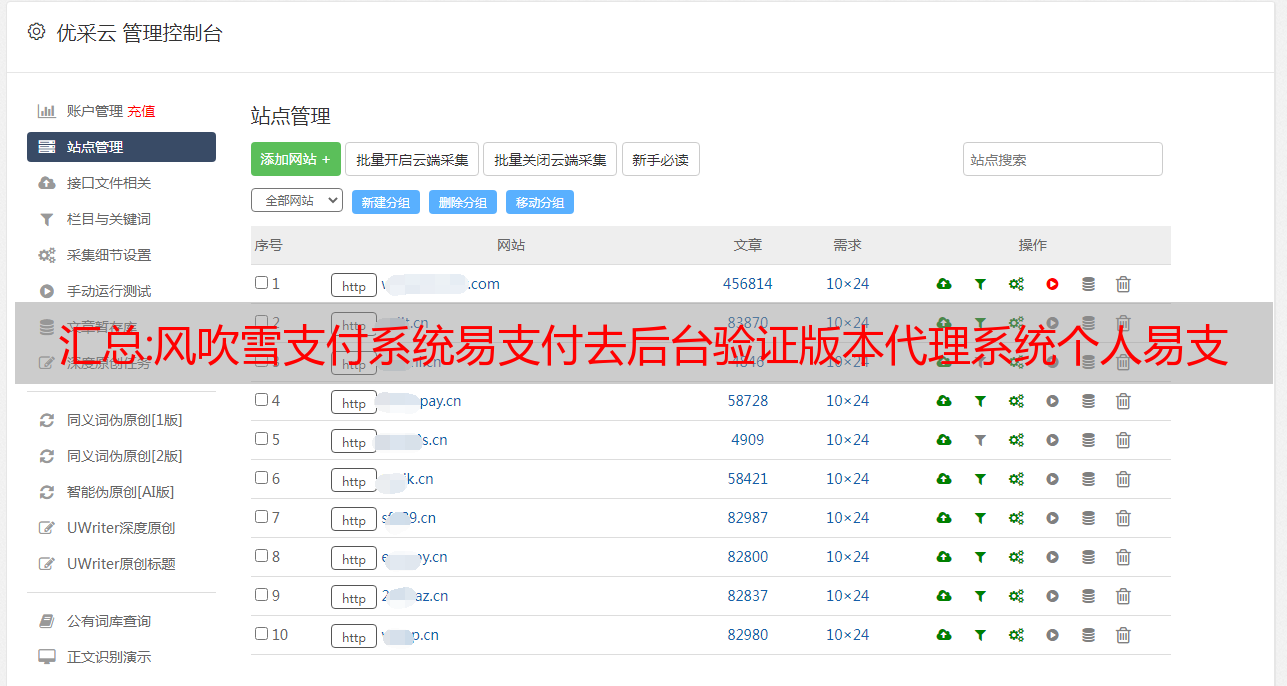
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除了这种情况,可以在对应资源底部留言,或者联系我们。
在资产介绍文章 中找不到示例图片?
对于会员制、全站源代码、程序插件、网站模板、网页模板等各类素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)找到来源。某些字体文件也是如此,但某些资产在资产包中会有字体下载链接列表。
付款后无法显示下载地址或无法查看内容?
如果您支付成功但网站没有弹出成功提示,请联系站长QQ&VX:1754646538提供支付信息供您处理。
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一经批准,将不接受任何形式的退款或换货请求。购买前请确认您需要的资源。
汇总:ygbook自动采集发布-ygbook采集发布规则-ygbook采集发布教程配置
ygbook采集 规则,ygbook采集 规则难吗?做过小说站的人应该都知道,写采集规则需要一定的编程功底和html编码功底。写入的 采集 规则也将无效。今天给大家分享一款免费的自动采集更新工具:全自动采集自动更新,只要在初始阶段设置好seo模板和输入目标Stations和target模板等即可。 ,后续无需担心任何事情,彻底解放了您的个人时间,同时让您拥有无限潜力的小说站。
由于 YGbook采集 的规则缺失。在这里我们使用采集软件与大家分享YGBook采集的26条规则。可以根据自己的情况过滤掉5-6条权重高、更新快、质量好的规则。采集来源,ygbook采集可以保证自动采集,更新200-500 + 每天看小说。
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在最常见的服务器上。
环境要求:PHP5.4以上,具有伪静态功能。推荐配置php7.2mysql5.6+
托管要求:可以使用IIS/APACHE/NGINX,可以使用虚拟主机/VPS/服务器/云服务器。
YGBOK的优势:
1、不保存数据,小说以软链接的形式存在。无版权纠纷。
2、因为是软链接,所以对硬盘空间的需求极小,成本低。
3.后台预设广告位,添加广告代码极其简单,想靠香烟赚钱的老人可以看看。
4.可以挂机自动采集,简单省心。
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在最常见的服务器上。
环境要求:PHP5.4以上,具有伪静态功能。推荐配置php7.2mysql5.6+
托管要求:可以使用IIS/APACHE/NGINX,可以使用虚拟主机/VPS/服务器/云服务器。推荐Linux系统,可以使用apache inx
硬件要求:对CPU/内存/硬盘/带宽的大小没有要求,但是配置越高,采集效率就越好!
其他要求:比如采集目标服务器在中国,而你的主机在国外,会导致采集效率低下。采集应尽量选择同一区域的网站。美国服务器应该选择机房在美国的小说站,国内服务器应该选择国内网站,尽可能提高网站的速度。
ygbook采集[cate] 对应的情况,取源站点的top category,选择中文。比如玄幻小说、修真小说、恐怖小说依次对应本站。如果类别差异太大,您可以在后台创建一个类别,然后对应。最大页码为 1。
规则列表的页码很容易理解。例如 1|1|200 表示从第一页开始到第 200 页,每增加一页。
ygbook采集没有缩略图标志一般是nocover,如果没有,可以通过查看源站来更改。
列表页面:链接 CSS 选择器和列表页面:标题 CSS 选择器
这个怎么选呢,我们打开首页查看最近更新列表,选择一大片区域:#newscontent,然后转到另一个区域。l 和下面库中最新的.r不同,终于到了我们真正想去的地方。s2 a end ,组合是#newscontent .l .s2 a,很多人喜欢这样写,ygbook采集类似提示#newscontent li a 有的站是可以的,但是一定要区分清楚。
文章页面上的各种选项,如果有360结构化站,以下是通用的
标题 CSS 选择器:meta[property=og:novel:book_name]|content
作者 CSS 选择器 meta[property=og:novel:author]|content
缩略图 CSS 选择器 meta[property=og:image]|content
内容 CSS 选择器通常是 #intro
因为源站介绍的源码一般,如果不自己修改介绍,ygbook采集结束符就不用多说了。
章节目录页:区域CSS选择器一般为:#list
自己查源码就知道了
章节目录页:采集规则也看源码,可以写。
如果有这样的:你可以写,把不需要的换成[string]。
上一章内容页:内容CSS选择器一般为#content。为什么上面提到ygbook采集可以自己看源码。
一般替换 {filter replace='hostloc'}BiquGe{/filter} 如果不替换直接删除,直接删除hostloc即可。
多栏:举个例子,不用解释这么多,累了。. .
规则列表页面为:[cate]/.html[cate]
ygbook采集对应的情况是根据URL:sort1 sort2 sort3对应奇幻城的页码
列表页面:链接 CSS 选择器 列表页面:标题 CSS 选择器是 #newscontent .l .s2 a
ygbook采集这个站点没有360结构,所以文章page:title CSS选择器是h1,一般就是这个
文章页面:作者CSS选择器为.infotitle i,在文章页面:源代码预过滤规则填写{filter replace=''}Author:{/filter},有无需为多个列编写分类。
ygbook采集文章 页面:内容 CSS 选择器是 .intro 这是我没有解决的问题。Introygbook采集虽然可以获取,但是价值太多了。后面的东西不是要的 提示也说可用 | 分段过滤但没看懂。
文章page: Thumbnail CSS selector is #fmimg img|src fmimg is value img|src is image

