最简单的方法:原来爬虫可以不用编程,只需要这几个工具
优采云 发布时间: 2022-10-08 11:18最简单的方法:原来爬虫可以不用编程,只需要这几个工具
在早期的互联网环境中,编写爬虫程序是一项技术活动,爬虫工程师也是一流的。但是随着科技和教育的发展,很多编程语言甚至都提供了爬虫框架,让爬虫进入到普通人的家中。
目前主流的爬虫方式是使用Python编程。Python 的强大是毋庸置疑的,但是初学者学习 Python 还是需要一两个月的时间。有没有更简单的方法来抓取数据?答案是肯定的。下面Python编程学习圈会介绍几个可视化爬虫工具。
家用工具
微软Excel
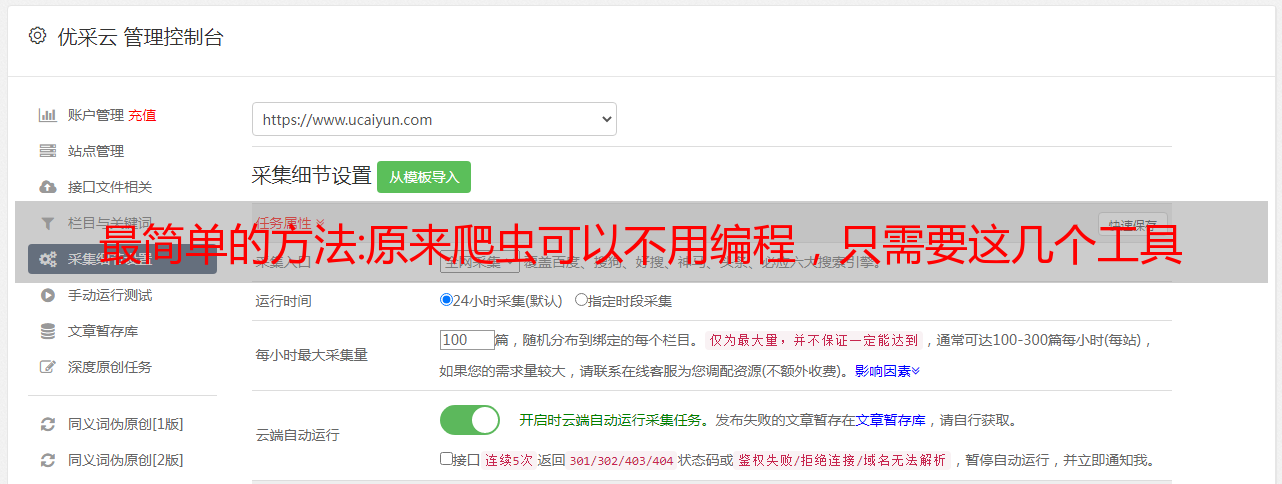
首先教大家一个使用Excel爬取数据的方法。此处使用 Microsoft Excel 2013 版本。让我们一步一步开始教学吧~
(1)新建一个Excel并打开,如下图
这里是全国实时空气质量示例网站,点击前往,然后导入
真棒吗?
数据”-“全部更新”-“连接属性”,输入更新频率。
优采云
/
一款无需可视化编程的网页采集软件,可以快速从不同的网站中提取归一化数据,帮助用户自动化采集、编辑和归一化数据,降低工作成本。
功能强大,爬虫老手当然也可以开发它的高级功能。
优采云
优采云是一款互联网数据采集、处理、分析、挖掘软件,采集功能齐全,不限网页和内容,任何文件格式均可下载,已知能采集99% 网页。
你需要有基本的HTML基础,并且能够看懂网页的源代码和结构,但是软件提供了相应的教程,新手可以学习上手。
吉苏克
一款简单易用的网页信息采集软件,可以采集网页文字、图表、超链接等网页元素。
表面上看功能不多,后续支付需求较多。
优采云云爬虫
一种新颖的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化网页数据。
用户编写自己的爬虫,这需要代码库。
优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛<有三个类别:采集器、cms采集器 和博客采集器。
全网数据的采集通用性不高。
外国工具
谷歌表格
/床单/关于/
使用Google Sheet爬取数据前,必须保证三点:使用Chrome浏览器、有Google账号、电脑翻墙。满足这三个条件就开始吧~
(1) 打开谷歌表格网站:
e form”,然后登录自己的账号,可以看到如下界面,然后点击“+”新建一个form
全国实时空气质量网站pm25.in/rank,目标网站上的表结构如下图:
页面,使用函数 = IMPORTHTML(URL, query, index),“URL”为爬取数据的目标网站,在“查询”中输入“列表”或“表格”,这取决于具体的结构数据类型,“Index”用阿拉伯数字填充,从1开始,对应网站中定义的哪个表或列表;
对于我们要爬取的网站,我们在Google sheet的A1单元格中输入函数=IMPORTHTML("pm25.in/rank","table",1),按下后就会爬取数据进入~
(5) 将爬取的表保存到本地
你得到
这是一个程序员基于python 3开发的项目,已经在github上开源,支持64个网站,包括优酷、土豆、爱奇艺、B站、酷狗音乐、虾米……总之你可以想想它网站!
还有一个黑科技的地方,就算不在列表里网站,当你输入链接的时候,程序就会猜测你要下载什么,然后帮你下载。
当然you-get需要安装在python3环境下。用pip安装后,在终端输入“你得到+你要下载的资源的链接”,就可以等待采集资源了。
这里有中文说明书给你-get,按照说明书上写的步骤操作即可。
*敏*感*词*.io
Import.io 是一个基于 Web 的 Web 数据采集 平台,允许用户在不编写代码的情况下生成提取器。与国内大部分采集软件相比,Import.io更加智能,可以匹配生成相似元素列表,用户在输入网址时也可以一键采集数据。
Import.io 智能开发,采集简单,但是在处理一些复杂的网页结构方面比较薄弱。
视觉网络开膛手
Visual Web Ripper 是一个支持各种功能的自动化网页抓取工具。
适用于一些高级和采集困难的网页结构,用户需要有较强的编程能力。
内容抓取器
Content Grabber 是最强大的网络抓取工具之一。它更适合具有高级编程技能的人,并提供了许多强大的脚本编辑和调试接口。允许用户编写正则表达式而不是使用内置工具。
Content Grabber 网页适用性强,功能强大。它们不完全为用户提供基本功能,适合具有高级编程技能的人。
莫曾达
Mozenda是一款基于云的数据采集软件,为用户提供了包括数据云存储在内的诸多实用功能。
适合有基本爬行经验的人
技巧:一种抽取论坛网页中帖子内容的方法及系统的*敏*感*词*法
一种从论坛网页中提取帖子内容的方法和系统 [专利摘要] 本申请公开了一种从论坛网页中提取帖子内容的方法和系统。该方法包括:获取论坛网页;将网页转换为DOM树,DOM树包括至少一个节点和至少一个从属于根节点的子节点。为根节点和至少一个子节点一一对应生成频繁模式;根据频繁模式中满足预设条件的频繁模式,确定论坛网页中信息内容对应的节点;基于预设的公共子树算法,从论坛网页中的信息中提取论坛网页中的信息内容,从内容对应的节点中提取。
技术领域:
] [0001] 本申请涉及计算机互联网领域,具体涉及一种论坛网页中的帖子内容提取方法及系统。【
背景技术:
] [0002] 随着互联网的日益普及和快速发展,论坛已经成为网络上重要的数据资源。随着论坛为人们提供了关于各种主题的大量非常有价值的知识和信息,越来越多的研究工作将利用从论坛数据中提取信息并构建各种应用程序。[0003] 为了有效地利用论坛数据,大多数应用程序首先从论坛网页中提取结构化数据,然后进一步利用这些数据来实现各种功能。目前论坛信息的提取方法大多是基于规则的,一般来说都是针对某个网站指定的规则并以此构造一个包装器,而包装器是一种软件组件,主要通过下面有两种构造方式:[0005] 一是知识工程的方式,即通过领域专家制定抽取规则;[0006] 二、使用机器学习方法自动构建包装器,根据标注模板,机器学习算法自动学习构建提取模型。申请人:在实现本申请实施例的过程中,发现上述方式至少存在以下问题: [0008] 一、由领域专家制定提取规则需要耗费大量人力,而且成本非常高;[0009] 其次,在使用机器学习方法时,需要对样本进行人工标注。上述利用包装器的信息提取技术都存在一定程度上依赖人工辅助,自动化程度较低,同时由于论坛网页形式多样且不断更新,因此wrapper的维护成本较高,适用性较差,适合*敏*感*词*应用。【
发明内容 [0011] 本申请提供一种论坛网页中的帖子内容提取方法,以解决现有技术中信息提取自动化程度低、适用性差的问题。[0012] 一方面,通过本申请实施例,提供了以下技术方案: [0013] 一种论坛网页中的帖子内容提取方法,包括: [0014] 获取论坛网页;[0015] 添加论坛将网页转换为DOM树,其中DOM树包括至少一个节点和至少一个从属于根节点的子节点;[0016] 为根节点与至少一个子节点的频繁模式生成一一对应关系;[0017] 根据频繁模式中满足预设条件的频繁模式,确定论坛网页中信息内容对应的节点;[0018] 基于预设的公共子树算法,从论坛网页中的信息内容对应的节点中提取论坛网页中的信息内容。[0019] 可选的,满足预设条件的频繁模式具体为:最大频繁模式;预设的公共子树算法具体为:最大公共子树算法。[0020]可选的,将论坛网页转化为DOM树具体包括: [0021]删除论坛网页中无用的网页标签;[0022] 删除论坛中无用的网页标签,将网页转化为DOM树。可选地,基于预设的公共子树算法进行描述,从论坛网页中的信息内容对应的节点中提取论坛网页中的信息内容,具体包括: [0024] ]过滤掉论坛网页中帖子之间的相同部分;[0025] 基于最大公共子树算法,从论坛网页内容中的信息内容对应的节点中提取论坛网页中的信息。
[0026] 可选的,在根据频繁模式中满足预设条件的频繁模式确定论坛网页中的信息内容对应的节点之前,还包括: [0027] 判断该频繁模式中各个的频率和支持度是否模式中的频繁模式大于或等于预设频率并支持;[0028] 当频繁模式的频率和支持度小于预设频率和支持度时,对上述所有频繁模式进行修剪。[0029] 可选的,预设频率和支持具体为:最低频率和最低支持。[0030] 另一方面,本申请另一实施例提供以下技术方案: [0031] 一种论坛网页中的帖子内容提取系统,该系统包括:[0032] 获取模块,用于获取论坛网页;[0033] 转换模块,用于将论坛网页转换为DOM树,其中,DOM树至少包括一个节点和至少一个从属于根节点的子节点;[0034] 生成模块,用于为根节点和至少一个子节点一一对应地生成频繁模式;[0035] 确定模块,用于根据频繁模式确定满足预设条件的频繁模式论坛网页中的信息内容对应的节点;[0036] 提取模块,用于根据预设的公共子树算法信息内容,从论坛网页中的信息内容对应的节点中提取论坛网页。[0033] 转换模块,用于将论坛网页转换为DOM树,其中,DOM树至少包括一个节点和至少一个从属于根节点的子节点;[0034] 生成模块,用于为根节点和至少一个子节点一一对应地生成频繁模式;[0035] 确定模块,用于根据频繁模式确定满足预设条件的频繁模式论坛网页中的信息内容对应的节点;[0036] 提取模块,用于根据预设的公共子树算法信息内容,从论坛网页中的信息内容对应的节点中提取论坛网页。[0033] 转换模块,用于将论坛网页转换为DOM树,其中,DOM树至少包括一个节点和至少一个从属于根节点的子节点;[0034] 生成模块,用于为根节点和至少一个子节点一一对应地生成频繁模式;[0035] 确定模块,用于根据频繁模式确定满足预设条件的频繁模式论坛网页中的信息内容对应的节点;[0036] 提取模块,用于根据预设的公共子树算法信息内容,从论坛网页中的信息内容对应的节点中提取论坛网页。其中,DOM树至少包括一个节点和至少一个从属于根节点的子节点;[0034] 生成模块,用于为根节点和至少一个子节点一一对应地生成频繁模式;[0035] 确定模块,用于根据频繁模式确定满足预设条件的频繁模式论坛网页中的信息内容对应的节点;[0036] 提取模块,用于根据预设的公共子树算法信息内容,从论坛网页中的信息内容对应的节点中提取论坛网页。其中,DOM树至少包括一个节点和至少一个从属于根节点的子节点;[0034] 生成模块,用于为根节点和至少一个子节点一一对应地生成频繁模式;[0035] 确定模块,用于根据频繁模式确定满足预设条件的频繁模式论坛网页中的信息内容对应的节点;[0036] 提取模块,用于根据预设的公共子树算法信息内容,从论坛网页中的信息内容对应的节点中提取论坛网页。用于根据频繁模式确定满足预设条件的频繁模式论坛网页中的信息内容对应的节点;[0036] 提取模块,用于根据预设的公共子树算法信息内容,从论坛网页中的信息内容对应的节点中提取论坛网页。用于根据频繁模式确定满足预设条件的频繁模式论坛网页中的信息内容对应的节点;[0036] 提取模块,用于根据预设的公共子树算法信息内容,从论坛网页中的信息内容对应的节点中提取论坛网页。
[0037] 可选的,满足预设条件的频繁模式具体为:最大频繁模式;预设的公共子树算法具体为:最大公共子树算法。[0038] 可选的,所述转换模块具体包括: [0039] 删除单元,用于删除论坛网页中无用的网页标签;[0040] 用于删除无用网页标签的转换单元。论坛网页被转换为 DOM 树。[0041] 可选的,所述提取模块具体包括: [0042] 过滤单元,用于过滤掉论坛网页中帖子之间的相同部分;[0043] 提取单元,基于最大公共A子树算法,从论坛网页中的信息内容对应的节点中提取论坛网页中的信息内容。[0044] 可选地,所述系统还包括: [0045] 判断模块,用于判断所述频繁模式中的每个频繁模式的频率和支持度是否大于或等于预设的频率和支持度;[0044] 0046] 剪枝模块用于当频繁模式的频率和支持度小于预设的频率和支持度时,对频繁模式进行修剪。[0047] 上述一种或多种技术方案具有以下技术效果或优点: [0048] 一、采用本应用提供的论坛网页中的帖子内容提取方法,解决了以下问题:发布现有技术中的内容。内容提取存在自动化程度低、系统适用性差等缺陷,应用范围广泛。[0045] 判断模块,用于判断频繁模式中的每个频繁模式的频率和支持度是否大于或等于预设的频率和支持度;[0044] 0046] 剪枝模块用于当频繁模式的频率和支持度小于预设的频率和支持度时,对频繁模式进行修剪。[0047] 上述一种或多种技术方案具有以下技术效果或优点: [0048] 一、采用本应用提供的论坛网页中的帖子内容提取方法,解决了以下问题:发布现有技术中的内容。内容提取存在自动化程度低、系统适用性差等缺陷,应用范围广泛。[0045] 判断模块,用于判断频繁模式中的每个频繁模式的频率和支持度是否大于或等于预设的频率和支持度;[0044] 0046] 剪枝模块用于当频繁模式的频率和支持度小于预设的频率和支持度时,对频繁模式进行修剪。[0047] 上述一种或多种技术方案具有以下技术效果或优点: [0048] 一、采用本应用提供的论坛网页中的帖子内容提取方法,解决了以下问题:发布现有技术中的内容。内容提取存在自动化程度低、系统适用性差等缺陷,应用范围广泛。
二、通过提取帖子的最大频繁模式,在频繁模式树中定位帖子内容节点所在的位置,然后通过最大公共子树动态规划匹配算法,可以快速、准确、完整地提取帖子内容. 所有相关元数据,例如主要、回复内容、发布时间、作者和楼层信息。[专利附图] [附图说明] [0050] 图。附图说明图1是本发明实施例的论坛网页中的帖子内容提取方法的流程图。[0051] 图。图2为本发明实施例中频繁模式树的*敏*感*词*;[0052] 图。图3为本申请实施例中网页发帖内容的*敏*感*词*;[0053] 图。图4为本发明实施例中提取网页论坛帖子内容的系统*敏*感*词*。【具体实施例】 【0054】本应用根据采集得到的论坛发帖页面对应的网页内容,提取发帖页面的最大频繁模式,然后通过最大频繁模式。最大公共子树算法过滤掉帖子之间的相同部分,然后提取帖子的内容和元数据。同时,根据本申请提供的方法,还可以提取同一论坛中其他帖子的内容和元数据。[0055] 本申请实施例技术方案的主要实现原理,下面结合附图对【具体实施方式】及相应可以达到的有益效果进行详细说明。[0056] 请参考图。图1是本发明实施例的论坛网页中的帖子内容提取方法的流程图。[0057] 步骤100,获取论坛网页;[0058] 在具体实现过程中,提取网页中的posts内容时,首先创建一个采集页面任务,并以列表页面的形式保存。根据这个采集任务的间隔,自动从列表页中的URL获取对应的网页地址,比如你想采集@采集梁靖元的帖子内容在*敏*感*词*,其采集任务的地址是:%Cl%BA%BE%B2%C8%E3#0[0059]步骤110,把论坛网页转换成DOM树;[0060] 在具体实现过程中,根据上述步骤110中的网页地址,获取该网页地址对应的论坛网页内容,首先删除该论坛网页中的无用网页标签;具体来说,无用的网页标签包括:
根据本领域技术人员的实际应用情况,其他相同或相似的网页标签均属于本申请的保护范围,在此不再赘述。[0061] 将删除无用网页标签的论坛网页转化为DOM树,DOM树包括至少一个节点和根节点下的至少一个子节点;[0062] 步骤120,a 根节点和对应位置的至少一个子节点生成频繁模式;[0063] 首先,用频繁模式树给出WEB数据和频繁模式的定义,对于某个集合A,令|A| 基数(大小),令 L={L0,L1,L2...LJ 表示一个有限的字母表,对应于半结构化数据中的属性或用于标记文本。[0064] 建立在L上的频繁模式树,称为频繁树,是一个六元组OT={V, E, B, L, M, r}。其中V是节点的有限集合,E=VXV表示(parent,child),E满足的父子关系。B表示满足的(可能是间接的)兄弟关系。频繁树中的任何一个节点都可以通过一条路径到达另一个节点,称为频繁模式。[0065] 下面结合图2对频繁模式的*敏*感*词*进行详细说明;[0066] 如图2所示,(HTML(HEAD(TITLE))(BODY(TABLE)(DIV))),这个模式代表了一个网页频繁树中的一个频繁模式,这个树的根节点是<HTML> 标签,所有内容节点(如:文本、图片等)都是这棵树的叶子节点。child),E.B 满足的父子关系表示满足的(可能是间接的)兄弟关系。频繁树中的任何一个节点都可以通过一条路径到达另一个节点,称为频繁模式。[0065] 下面结合图2对频繁模式的*敏*感*词*进行详细说明;[0066] 如图2所示,(HTML(HEAD(TITLE))(BODY(TABLE)(DIV))),这个模式代表了一个网页频繁树中的一个频繁模式,这个树的根节点是<HTML> 标签,所有内容节点(如:文本、图片等)都是这棵树的叶子节点。child),E.B 满足的父子关系表示满足的(可能是间接的)兄弟关系。频繁树中的任何一个节点都可以通过一条路径到达另一个节点,称为频繁模式。[0065] 下面结合图2对频繁模式的*敏*感*词*进行详细说明;[0066] 如图2所示,(HTML(HEAD(TITLE))(BODY(TABLE)(DIV))),这个模式代表了一个网页频繁树中的一个频繁模式,这个树的根节点是<HTML> 标签,所有内容节点(如:文本、图片等)都是这棵树的叶子节点。[0065] 下面结合图2对频繁模式的*敏*感*词*进行详细说明;[0066] 如图2所示,(HTML(HEAD(TITLE))(BODY(TABLE)(DIV))),这个模式代表了一个网页频繁树中的一个频繁模式,这个树的根节点是<HTML> 标签,所有内容节点(如:文本、图片等)都是这棵树的叶子节点。[0065] 下面结合图2对频繁模式的*敏*感*词*进行详细说明;[0066] 如图2所示,(HTML(HEAD(TITLE))(BODY(TABLE)(DIV))),这个模式代表了一个网页频繁树中的一个频繁模式,这个树的根节点是<HTML> 标签,所有内容节点(如:文本、图片等)都是这棵树的叶子节点。
每个内部节点代表一对标签(一个起始标签和一个结束标签),或者只有一个标签(标签没有对应的结束标签)。根标签和内部节点统称为标签节点。[0067] 通过对步骤110生成的DOM树中的每个节点进行前序遍历,相应地对DOM树中的每个节点进行前序遍历,将每个节点转换为频繁模式。[0068] 需要说明的是,频繁模式包括一系列路径节点,并且根据标签路径的不同定义,每个路径节点的构成元素是不同的。[0069] 步骤130,根据频繁模式中满足预设条件的频繁模式,确定论坛网页中的信息内容对应的节点;[0070] 满足预设条件的频繁模式具体为::最大频繁模式;预设的公共子树算法具体为:最大公共子树算法。[0071] 另外,在本步骤之前,即在根据频繁模式中满足预设条件的频繁模式确定论坛网页中的信息内容对应的节点之前,还包括: [0072] 判断频繁模式中每个频繁模式的频率和支持度是否大于或等于预设的频率和支持度;[0073] 当频繁模式的频率和支持度小于预设频率和支持度时,对频繁模式进行修剪。具体来说,预设频率和支持具体为:最低频率和最低支持。
[0074] 在执行剪枝过程之后,进一步避免了输出无用模式。过滤完成后开始展开,展开时根据频繁模式树的层级进行展开,即检查这些模式中是否还有其他兄弟节点,如果有,在这个频繁模式的基础上添加兄弟节点,扩展一个新的频繁模式。展开兄弟节点后,检查模式是否有子节点。如果是,则在这个频繁模式的基础上添加子节点,扩展一个新的频繁模式。每次扩展新的频繁模式时,将新发现的模式和其他相关信息(例如位置)插入队列中。重复此步骤,直到队列中的所有模式都已扩展。[0075] 步骤140,基于预设的公共子树算法,从论坛网页信息内容对应的节点中提取论坛网页信息内容。[0076] 在具体实现过程中,本步骤包括以下过程: [0077] 过滤掉论坛网页中帖子之间的相同部分;[0078] 基于最大公共子树算法,从论坛网页中的信息内容对应的节点中。从论坛网页格式可以知道,同一个论坛往往有相似的格式,所以根据频繁模块提取的最大频繁模式必然是论坛主从帖子所在分支生成的模式,如如*敏*感*词*主帖形成的格局(div(a)(div(a)(table(tbody(tr)))(div(div))))。
该模式是论坛信息区所在的分支。论坛网页内容区域的识别,就是在网页中找到具有大量相似结构的区域,对应网页的频繁树,即找到最频繁的频繁模式. 这种模式不一定是收录内容数据的区域,但必须在频繁树中。由收录内容数据区域的节点的后代节点之一形成的频繁模式。收录数据的区域就在它附近。因此,如果找到该频繁模式,则可以执行内容数据区域定位和数据提取。[0080] 请参阅图3,为本申请实施例中网页的内容*敏*感*词*;[0081] 如图3所示,主从职位结构相同,除职位内容信息不同外,其他结构基本相同。. 因此,当找到出现次数最多的频繁模式时,可以使用最大公共子树动态规划算法在子树中找到完全相同的结构(文本和标签相同)。去掉相同部分后,剩下的部分就是主从发布的内容和内容对应的元数据。提取论坛网页中的信息内容。[0082] 请参考下图4,为本申请实施例的论坛网页中的帖子内容提取方法的流程图;[0083] 如图4所示,该系统包括: [0084]获取论坛网页获取模块;[0085] 一种转换模块,用于将论坛网页转换为DOM树,其中,DOM树包括至少一个节点和至少一个从属于根节点的子节点;[0086] 所述转换模块具体包括: [0087] 删除单元,用于删除论坛网页中无用的网页标签;[0088] 转换单元,用于将删除无用网页标签的论坛网页转换成DOM树。
[0089] 生成模块,用于为根节点和至少一个子节点一一对应地生成频繁模式;,确定论坛网页中信息内容对应的节点;满足预设条件的频繁模式具体为:最大频繁模式;预设的公共子树算法具体为:最大公共子树算法。[0091] 提取模块,用于根据预设的公共子树算法,从论坛网页中的信息内容对应的节点中提取论坛网页中的信息内容。[0092] 提取模块具体包括: [0093] 过滤单元,用于过滤掉论坛网页中帖子之间的相同部分;[0094] 一种提取单元,用于基于最大公共子树算法,from 论坛网页中的信息内容是从论坛网页中的信息内容对应的节点中提取的。[0095] 该系统还包括: [0096] 判断模块,用于判断频繁模式中的每个频繁模式的频率和支持度是否大于或等于预设的频率和支持度;[0097] 剪枝模块用于当频繁模式的频率和支持度小于预设的频率和支持度时,对频繁模式进行修剪。预设频率和支持具体为:最低频率和最低支持。[0098] 通过本申请的一个或多个实施例,可以达到以下技术效果: [0099] 一、采用本申请提供的论坛网页中帖子内容的提取方法,
二、通过提取帖子的最大频繁模式,在频繁模式树中定位帖子内容节点所在的位置,然后通过最大公共子树动态规划匹配算法,可以快速、准确、完整地提取帖子内容. 所有相关元数据,例如主要、回复内容、发布时间、作者和楼层信息。[0101] 尽管已经描述了本申请的优选实施例,但是一旦基本的发明概念已知,本领域技术人员可以想到对这些实施例的附加改变和修改。因此,所附权利要求旨在被解释为包括优选实施例以及落入本申请范围内的所有改变和修改。[0102] 显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本发明的精神和范围。因此,如果本申请的这些修改和变化落入本申请的权利要求及其等同物的范围内,则本申请也旨在包括这些修改和变化。1.一种论坛网页中的帖子内容提取方法,包括: 获取论坛网页;将论坛网页转换为DOM树,其中DOM树包括至少一个节点和至少一个属于根节点的子节点;以一一对应的方式为根节点和至少一个子节点生成频繁模式;论坛网页中信息内容对应的节点;
2.如权利要求1所述的方法,其特征在于,所述满足预设条件的频繁模式具体为:最大频繁模式;所述预设公共子树算法具体为:最大公共子树算法。3.如权利要求1所述的方法,其特征在于,将所述论坛网页转化为DOM树,具体包括: 删除所述论坛网页中无用的网页标签;论坛页面被转换为 DOM 树。4.根据权利要求2所述的方法,其特征在于,根据预设的公共子树算法,从论坛网页中的信息内容对应的节点中提取论坛网页中的信息。信息内容具体包括:过滤掉论坛网页中帖子之间的相同部分;根据最大公共子树算法信息内容,从论坛网页中的信息内容对应的节点中提取论坛网页中的信息。5. 3.根据权利要求2所述的方法,其特征在于,在根据所述频繁模式中满足预设条件的频繁模式确定所述论坛网页中的信息内容对应的节点之前,还包括: 6。:判断频繁模式中每个频繁模式的频率和支持度是否大于或等于预设的频率和支持度;当某个频繁模式的频度和支持度小于预设的频度和支持度时,对该频繁模式进行剪枝。6.如权利要求5所述的方法,
7、一种论坛网页中的帖子内容提取系统,该系统包括: 获取模块,用于获取论坛网页;转换模块,用于将论坛网页转换为DOM树,其中,DOM树包括至少一个节点和至少一个从属于根节点的子节点。生成模块,用于为根节点和至少一个子节点一一对应地生成频繁模式;根据频繁模式中满足预设条件的频繁模式,确定论坛网页中的信息内容对应的节点;提取模块用于从论坛网页中的信息内容中提取信息。论坛网页中的信息内容是从论坛网页中的信息内容对应的节点中提取的。8. 8.根据权利要求7所述的系统,其特征在于,所述满足预设条件的频繁模式具体为: 最大频繁模式;预设的公共子树算法具体为:最大公共子树算法。9.如权利要求7所述的系统,其特征在于,所述转换模块,具体包括: 删除单元,用于删除所述论坛网页中无用的网页标签;转换单元,用于删除无用的网页标签 将论坛页面转换为 DOM 树。10.根据权利要求7所述的系统,其特征在于,所述提取模块具体包括: 过滤单元,用于过滤掉论坛网页中帖子之间的相同部分。最大公共子树算法从论坛网页信息内容对应的节点中提取论坛网页信息内容。其中,满足预设条件的频繁模式具体为:最大频繁模式;预设的公共子树算法具体为:最大公共子树算法。9.如权利要求7所述的系统,其特征在于,所述转换模块,具体包括: 删除单元,用于删除所述论坛网页中无用的网页标签;转换单元,用于删除无用的网页标签 将论坛页面转换为 DOM 树。10.根据权利要求7所述的系统,其特征在于,所述提取模块具体包括: 过滤单元,用于过滤掉论坛网页中帖子之间的相同部分。最大公共子树算法从论坛网页信息内容对应的节点中提取论坛网页信息内容。其中,满足预设条件的频繁模式具体为:最大频繁模式;预设的公共子树算法具体为:最大公共子树算法。9.如权利要求7所述的系统,其特征在于,所述转换模块,具体包括: 删除单元,用于删除所述论坛网页中无用的网页标签;转换单元,用于删除无用的网页标签 将论坛页面转换为 DOM 树。10.根据权利要求7所述的系统,其特征在于,所述提取模块具体包括: 过滤单元,用于过滤掉论坛网页中帖子之间的相同部分。最大公共子树算法从论坛网页信息内容对应的节点中提取论坛网页信息内容。
11.如权利要求7所述的系统,其特征在于,所述系统还包括:判断模块,用于判断所述频繁模式中各频繁模式的频率和支持度是否大于或等于预设频率和支持度;修剪模块用于当频繁模式的频率和支持度小于预设频率和支持度时,对频繁模式进行修剪。12.根据权利要求11所述的系统,其特征在于,所述预设频率和支持度具体为:最低频率和最低支持度。·【文献编号】G06F17/30GK103853770SQ2 【出版日期】2014年6月11日申请日期:2012年12月3日优先日期:2012年12月3日【发明人】张涛、杨建武、于晓明申请人:北京大学方正集团*敏*感*词*, 北京大学,

