常用的方法:织梦常用采集规则
优采云 发布时间: 2022-10-08 08:19常用的方法:织梦常用采集规则
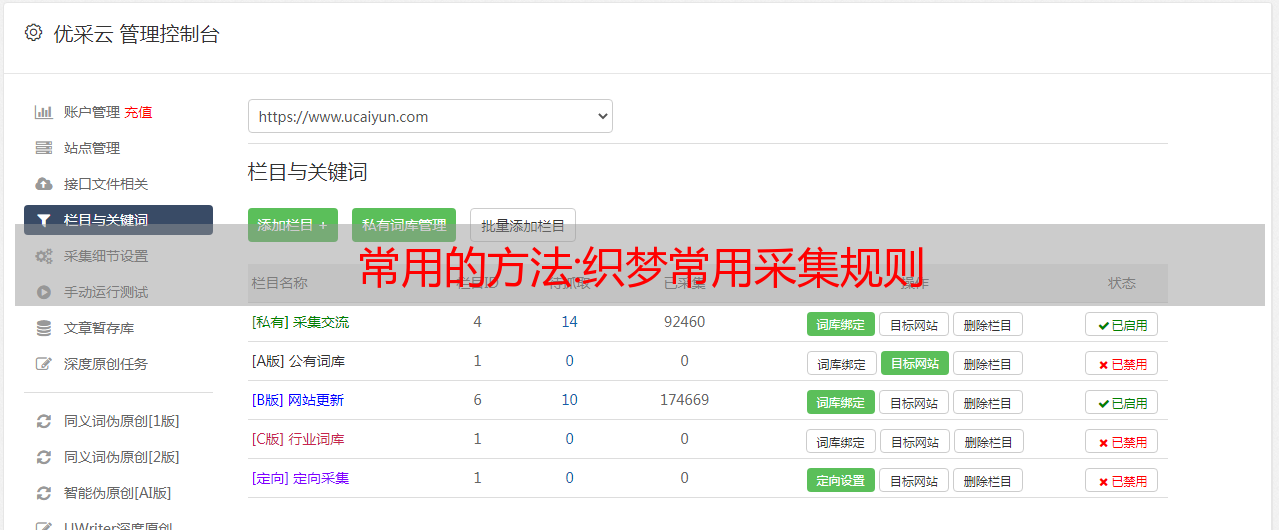
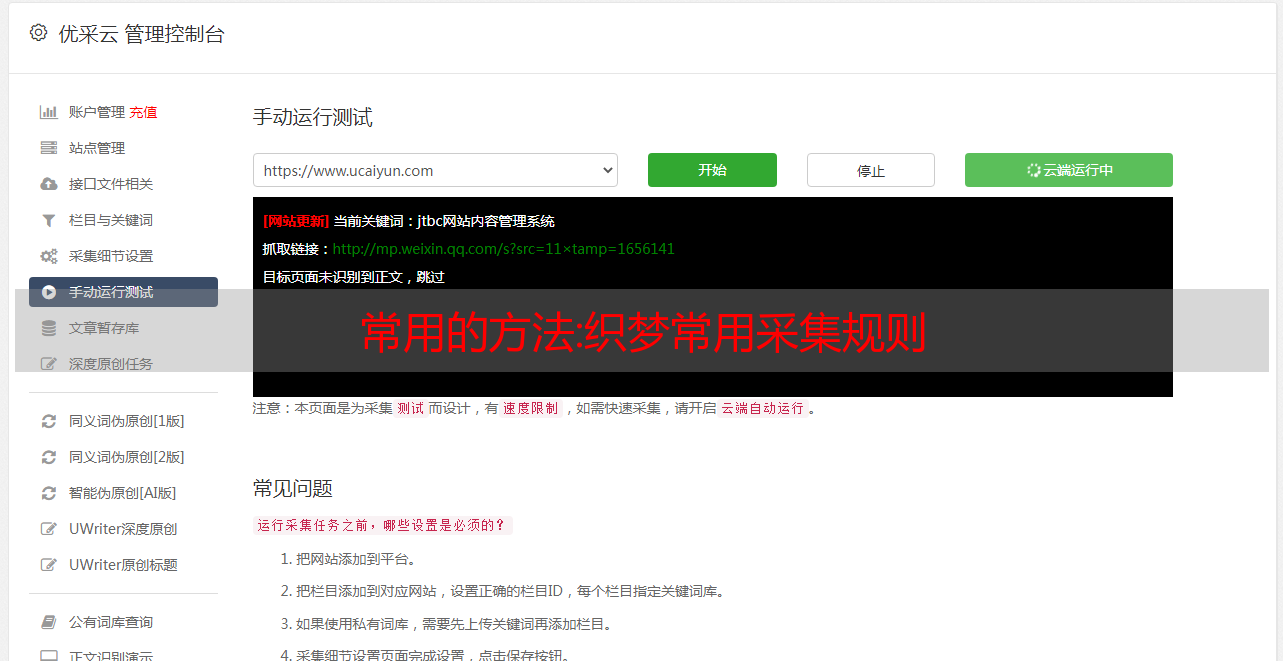
织梦常用采集规则织梦cms自带的采集系统,保存一些手动信息来设置dede采集规则采集点然后点击采集OK~确实很方便~下面介绍了几种常用的采集规则的过滤方法版权应用示例,作者在连接过滤器采集文章当一些网站系统作者或来源有直接采集 使用连接采集则连接采集回来,并且由于这两个字段受到限制,因此需要采集的内容不会cms回来,因此您需要在过滤器中添加以下常规筛选器1 如果要保留 dede 链接 dedetrima[] dedetrimde三个月前中的文本版权 2 如果您删除链接 dedetrima[][]adedetrim 应用程序示例二织梦cms模板筛选器标题空间通常采集文章当标题文本在 采集回来后的应用程序非常麻烦,所以需要在标题过滤器的中间添加以下常规过滤器 dedetrimdetrim 在应用程序中间有一个空格 示例三个过滤器 GG广告代码 事实上,这是上面的内容过滤 但是很多网友在论坛中经常问这个 所以把它单独列为一个应用程序去dedetrimscript[][Scriptdedetrim下面是一个 dedecms规则过滤complete set of dedetrimparam[]dedetrimdetrimedtrimembed[][]embeddetrimdetrimdedetrimembed[]dedetrimdetrimededetrimobject[][] objectdedetrimdedetrimobject[]] dedetrimdetrimbjectdedetrimbjededetrimdetrimOBJECT[][]OBJECTdedetrimdetrimedetrimOBJECT[]dededmdedetrimOBJECTdedetrimdedetrimiframe[]] iframedetrimdedetrimiframe[]dedetrimdedetrimiframedetrimdetrimidetrimIFRAME[][]IFRAMEdedetrimdetrimIFRAME[]dedetrimdedetrimIFRAMEdetrimdedetrimiframe[][] fontdedetritrimdedetrimfont[]dedetrimdedetrimfontedetrimdedetrimdetrima[][]adedetrimdedetrima[]dedetrimdetrimdedetrimtd[][]tddedetrimdetrimtdetrimtd[] dedetrimdetrimddedetrimdetrimtr[][]trdedetrimdedetrimtr[]dedetrimdetrimedetrimdetrimtbodydetrimy[] tbodydedetrimdetrimtbodydetrimdedetrimdedetrimtable[][]]tabledetrimdedetrimtable[]dedetrimdetrimedetrimedetrimedetrimdedetrimde三十三个十进制十三进制数据集文章过滤链接和其他广告代码的内容这并不是说当你需要过滤所有内容时,你可以直接用上面的所有代码进行过滤,但在实际应用中我们只需要过滤连接*敏*感*词*调用等。这需要根据对方内容中所收录的代码来具体操作,一般只有链接可以使用代码过滤第二,但实际上,一般网站现在内容中有广告,所以采取以下过滤规则来完成过滤去德德三位[][]adetrimdetrimIFRAME[][]IFRAMEdetrimdetrimdemobject[][]对象十三进制脚本[][]脚本三进制织梦模板过滤divs可以去德三分项]去德三分项过滤js 用下面的 dedetrim] []dedetrim 过滤器未知变量字符修复 以上几个应用基本涵盖了采集各种应用掌握这个过滤器基本上不需要问人~下面是一个更简单的方法,可以复制以下过滤规则给你几乎所有的问题,当然可以处理所有的问题, 你还可以分析 dedetrimspandetrimdetrimdemdivdetrimdemdtrimdtrimdivdetrimdemdetrimdemlidetrimidetrimidetrimdetrimdtrimdedetrimdetrimdedetrimfontedetrimdetrimdedetrimdetrimtabledetrimedetrimedetrimtabledetrimtabledetrimdedetrimtbodydetrimdetrimdetrimtedetrimtedetrimtedetrimtedetrimdetrimedetrimtdedetrimdedetrimtdedetrimtdedet 边缘德三三德三德三三框架德三德德三三米框架一帧dedetrimdedetrimstylededetrimdetrimscriptdetrimdedetrimoptiontiondedetrimdedetrimselects选择dedetrimdedetrimdetrimembe ddetrimdetrimdetrimdetrimparamparamdedeltrimdetrimdetrimdemdetrimdemdemdemobjectdetrim上面的段落优采云采集过滤代码不能用于采集带有视频的页面,因为如果您确认要采集视频,则视频的最后四行已被过滤掉,然后删除最后一个四行 这是织梦cms 优采云采集过滤器代码~
教程分享:FaceBook Scarper采集收刮软件的使用教程
首先要做的是下载并安装软件。
该软件需要.net framework 4.0的支持。如果你的电脑没有这个微软程序,你可以自己下载安装。
现在大多数 Windows 系统都默认附带它。
下一步是下载并安装我们的 FaceBook Scarper 软件。解压后。直接运行。
接下来注册、key等,大家可以参考一下。
本页简介。
今天我们重点介绍一下软件各个功能的详细使用。
首先:关键词搜索。
即根据您输入的关键词,软件会自动搜索相关群组,以及公共主页和趋势,其中收录该关键用户的相关信息。
也就是ID号,然后通过Facebook Graph Search进行匹配,找到它的真实邮箱地址和真实电话号码。
这是这个功能的全部效果,速度比较快,关键词可以多设置。匹配成功率还是不错的。
这是它的独立功能,其实很简单。
根据字面意思,你可以很清楚的知道它的功能。
那么很多人不明白的是,这些Groups ID就是我们的组ID号,它们是什么?
而我们公众主脸的ID是什么?
即如何查看群的ID号,查看公众主页的ID号。
对于任意组,选择报表组,左下角可以看到其ID号,也可以在新窗口中打开报表功能。
那么这串数字就是这个组的唯一ID号。
就这么简单,
那么公共主页也是一样的。当您选择举报时,也会显示公众主页的ID号。
只需将其复制到软件中并使用即可。
最后说一句:全球转强就够了。

