通用解决方案:大作AI采集器Chrome插件
优采云 发布时间: 2022-10-08 05:06通用解决方案:大作AI采集器Chrome插件
大作AI采集器Chrome插件是浏览器上的一个图片采集插件,可以帮助用户将网页上看到的所有好图保存到自己的大作账号中,方便后续创作使用,有需要的用户不要错过,欢迎下载使用!
插件说明
这是一种方便的方式,可以将每个网站的图片保存到你的道座账号,以后需要时打开道座浏览你喜欢的图片。采集时,大作AI智能程序可以识别图片的场景和物体供您选择,方便后期查找。
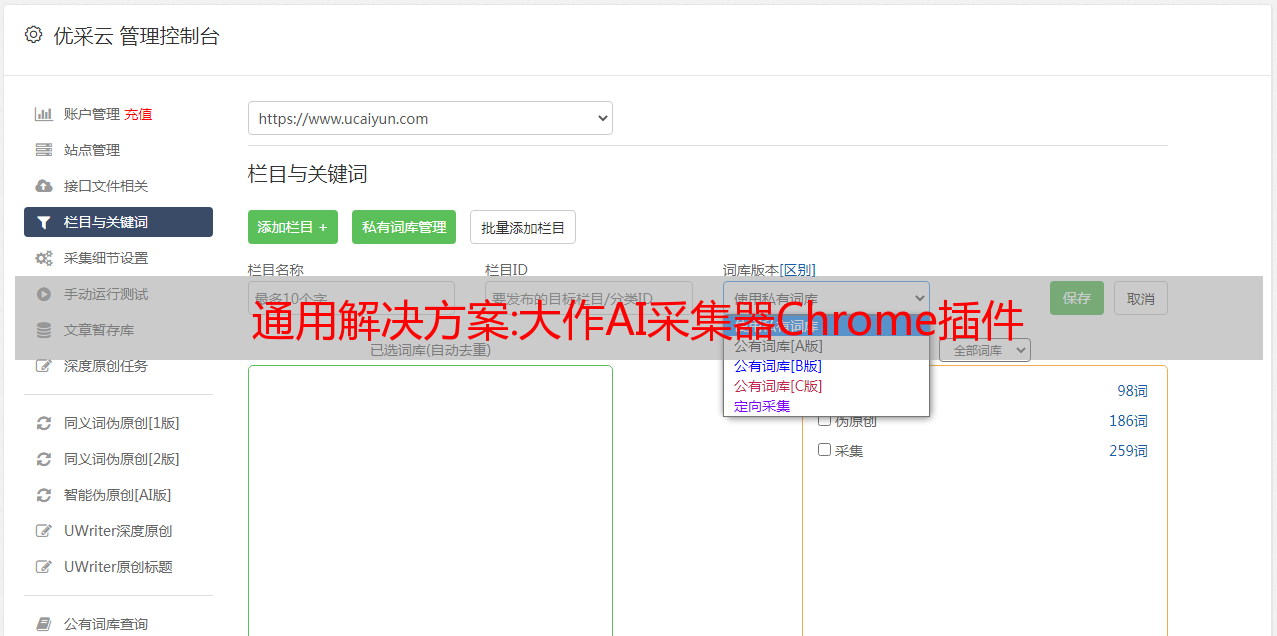
相关介绍
大作是为各行业设计师量身打造的设计灵感搜索引擎。它聚合了世界上许多知名的设计网站。目前,馆内有创意设计、设计资料、摄影图片21.2亿件,日更新量超过25万份。
安装说明
1.下载安装文件
下载插件,在浏览器安全提示时选择【保留】,在下载文件夹中找到下载的文件,后缀为.crx。
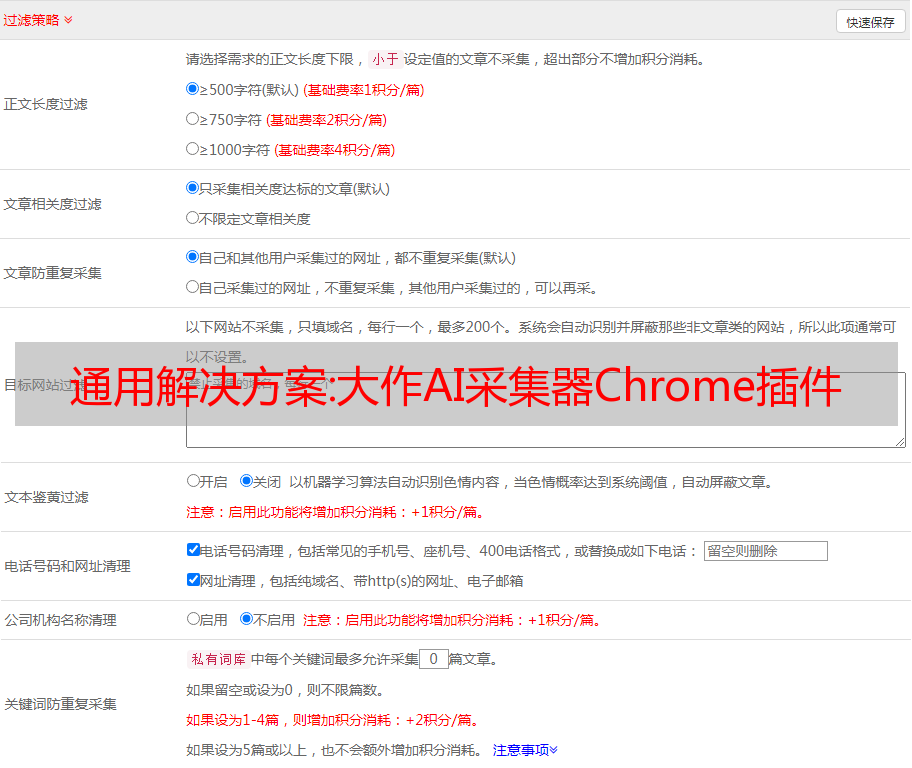
注意:如果出现安全提示,请选择保留。这是您浏览器的默认设置,我们的插件不会损害您的计算机。
2.打开扩展安装页面
复制chrome://extensions粘贴到地址栏,回车进入扩展安装页面,打开右上角【开发者模式】。
3.安装插件
将下载的.crx文件拖到扩展安装页面,等待几秒,在安装弹窗点击添加。
目录:
1.优采云教程
优采云,众所周知,使用优采云的内容就是优采云采集的原理,高铁抓取的数据rail采集器 取决于你的规则来获取某个网页的所有内容,你需要先获取该网页的URL。这里的URL程序根据规则引用列表页,分析其中的URL,然后编写规则获取URL的网页内容。
2.高铁资讯采集
对于不懂代码的小白同学来说,上手非常复杂。今天给大家免费分享一个采集器所有图片的详细参考,以及进阶采集的使用规则
3.优采云win10
指定采集:可以抓取任意网页数据,只需点击几下鼠标即可轻松获得所见即所得的操作方法。
4.优采云官网
关键词文章采集:输入关键词到采集文章,可以同时创建多个采集任务(一个任务可支持上传1000个关键词,软件还配备了关键词挖矿功能)
5.优采云破解版
监控采集:可定时自动对目标网站执行采集,频率可选择10分钟、20分钟,监控采集可根据用户需求定制。
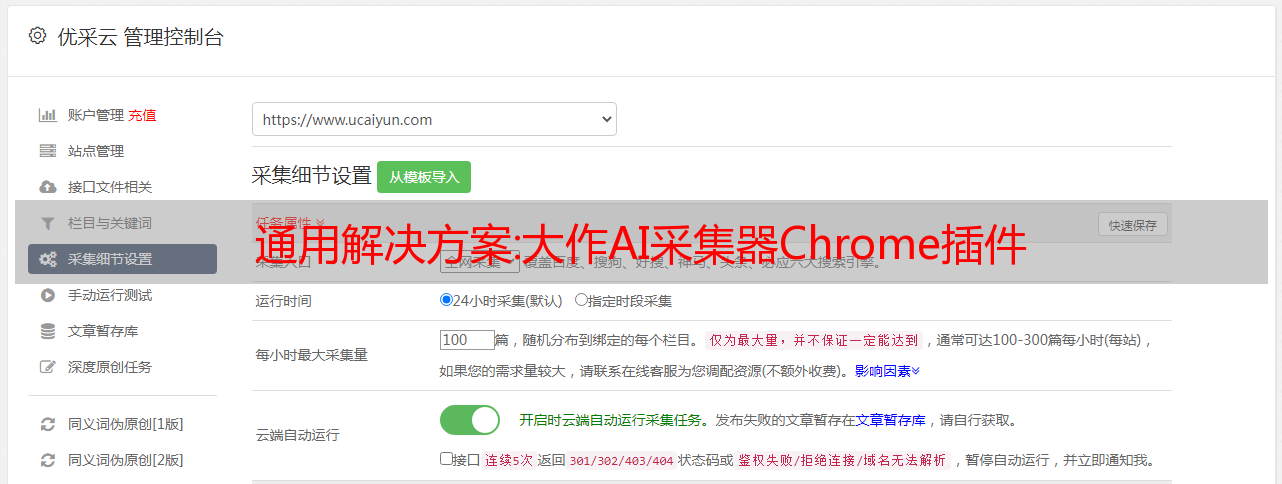
标题处理:根据标题或关键词自定义生成多样化标题(双标题和三标题自由组合,自定义填空符号,支持自建标题库生成,自媒体标题党生成,标题替换等等)
图片处理:图片加标题水印/图片加关键词水印/自定义图片水印/替换图片。不仅可以保护图片的版权,还可以防止图片被盗。图片加水印后,就形成了一张全新的原创图片。
自动内容伪原创:伪原创的意思是重新处理一个原创的文章,让搜索引擎认为它是一个原创文章,从而增加网站的重量,不用担心网站没有内容更新!
内容翻译:汇集世界上一些最好的翻译平台,将内容质量提升到一个新的水平。翻译后不仅保留了原版面的格式,而且翻译的字数也不受限制。多样化的翻译让文章形成高质量的伪原创。
关键词优化:自动内链有助于提高搜索引擎对网站的爬取和索引效率,更有利于网站的收录。结合自动敏感词过滤,避免被搜索引擎降级,让网站拥有更好的收录和排名。
主要网站自动发布:无需花费大量时间学习软件操作,一分钟即可上手,提供全自动系统化管理网站,无需人工干预,自动化设定任务的执行,一个人上百个维护,上千个网站都不是问题。我们打开一个网页,看到有一篇文章文章很不错,于是我们复制了文章的标题和内容,把这个文章复制到了我们的网站。我们的过程可以称为一个采集,把有用的信息从别人网站传递给自己网站网上的大部分内容都是通过copy-modify-paste的过程产生的,所以信息采集很重要也很常见,我们平台发送到网站文章上的,大部分也是这样的过程;为什么很多人觉得新闻更新很麻烦,因为这项工作是重复的、无聊的、浪费时间的;。
这款免费的采集器是目前国内用户最多、功能最全、网站程序支持最全面、内容处理最丰富的软件产品;现在是大数据时代,可以快速、批量、海量地把数据放到网上,根据我们的需要导出;简单来说,对我们有什么用?我们要更新新闻,我们要分析,如果让你准备1000篇文章文章,需要多长时间?5个小时?使用 采集器,只需 5 分钟!
毕竟这篇文章是优采云的介绍,所以我也会给大家详细介绍一下优采云的使用教程。
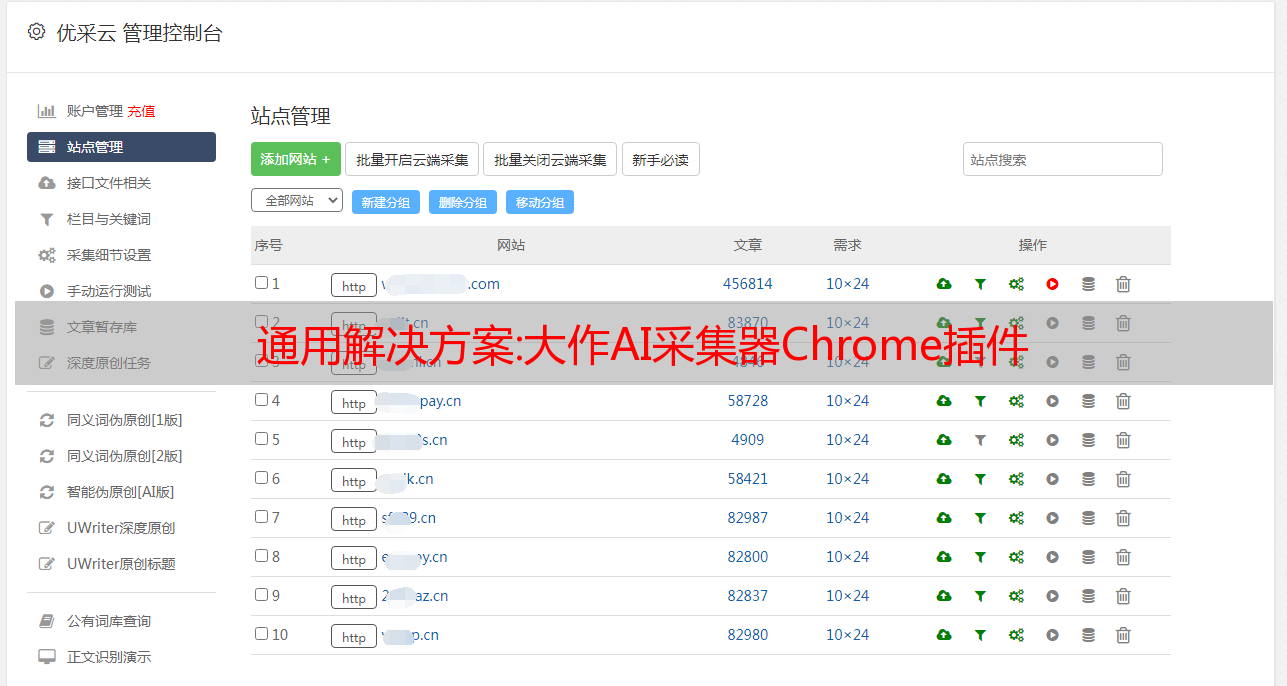
1.采集网站这一步也告诉软件需要采集多少个网页,并给出具体的页面地址 2.内容有了网址后,就可以到网站去采集信息,但是网页上的信息很多,内容部分软件不知道你要采集什么,所以需要写规则(HTML标签)。
1.网站的商品信息就是你想要的,即目标在采集链接页面,进入采集地址的列表页面,注意过滤无用链接点击测试按钮 测试填写信息的正确性:测试无误后,我们将地址展开,现在我们只取一个列表页的文章地址,其他列表需要采集,其他列表页面在其分页中。我们观察这些分布的链接形式,找出规则,然后批量填写URL规则。
2、内容的采集经过上面的处理后,目标产品页面的链接就被拾取了。现在我们进入内容的采集来明确采集的内容,然后我们开始写采集Rules,High Speed Rail采集的内容是采集网页的源代码,所以我们需要打开产品页面的源代码,找到我们想要采集信息的位置。
例如,描述字段的 采集:
找到Description的位置,找到之后,采集规则怎么填,很简单,把采集目标的开始字符串和结束字符串填到对应的位置采集这里我们选择描述:作为开始字符串,作为结束字符串。
值得注意的是,起始字符串在该页面上必须是唯一的,并且该字符串在其他产品页面上也存在。这个页面是软件唯一能找到采集的地方,其他页面都是通用的,让软件可以捡起来。其他页面的数据
填好后,不代表可以采集正确。需要进行测试,排除一些无用的数据。可以在 HTML 标签排除和内容排除中测试排除。测试成功后,就制作了这样的标签。这里我们使用通配符来实现这个要求我们使用(*)通配符来表示任何不常见的地方。
对于采集的地址,我们用参数(变量)来表示。最后我们把这个内容改成:(*)比较价格(*)产品详情,填写模块,测试是否成功。
如果测试不成功,说明您填写的内容不符合唯一通用标准。您还需要成功调试和测试。您可以保存并进入标签制作。这里的标签制作和上面一样,找到需要的采集信息所在的位置,填入开始和结束字符串,并做好过滤,唯一不同的是需要选择刚才在页面选项里做的模块,这里不再赘述,直接展示结果。
主题测试文章,仅供测试使用。发布者:小编147,转载请注明出处:

