总结:SEO教程:5个维度解密通吃90%行业的SEO关键词分析方法!
优采云 发布时间: 2022-10-08 03:15总结:SEO教程:5个维度解密通吃90%行业的SEO关键词分析方法!
作者|巴伦编辑|巴伦
来源|巴朗(ID:balangk)
目录(全文3049词) 01 词的定性属性 02 词的目标属性 03 词的物理属性 04 词的竞争属性 05 词的空间属性 06 关键词 分析过程的最后部分
开战前,先练兵,养兵千日,用一时。布兵前谋大计,确保大计不可一蹴而就,坚决落实战略布局。在SEO工作中,关键词相当于我们的士兵,我们用这些士兵来打败我们的对手。
训练就是分析关键词的竞争程度,SEO优化方案就是制定一个大计划,士兵训练好了,大计划就确定了,就可以驰骋沙场,攻无不克,战无不胜,就算失败了,也会打成平手。
Barang 将 关键词 的属性分为 5 类。它们是:定性属性、目标属性、物理属性、竞争属性和空间属性。
这是我四年半学习的总结。如果你能用它,你可以轻松驾驭任何行业的关键词。剩下的就是如何使用关键词分析工具了。
01 词的定性属性
在SEO行业,第一件事关键词分析:[给网站定性]
网站本质是什么:营销或品牌,或两者兼而有之?在确定了网站的性质之后,就确定了主题。
术语解释营销词:用户需求大、能实现商业变现的词。品牌词:展示的主要目的是布局,增加曝光面积,慢慢做营销。
以上两个定性词体现了2点: 1、做营销转化为主语,在选择主语时尽量使用转化词作为主语。2.以品牌展示为主,尽量选择主语,以交通词为主题词。
02 词的目标属性
在确定了网站的性质后,目标群就确定了,所以接下来的词扩展方向就确定了。确定了扩展方向后,就确定了对应的扩展词,长尾关键词。
术语解释定位词:也叫主语,俗称主语。它用于直接针对您的行业和业务。目标性质很明确,直接定位你的网站主题,所谓定位就是:你做什么。
封面词:由主要词组成的词组。这些词是最灵活的,也是最不容易掌握的。竞争词:总结你所在的行业,你的同行在做的词,非常赚钱的词,竞争非常大。
长尾词:扩展主词和覆盖词的词。长尾关键词是相对的,不是绝对的。这个知识点被很多SEO行业的“老师”歪曲了,后面我会为大家详细讲解。
03 词的物理性质
词库确定后,可以对数据进行分析,确定具体对应的优化方案。
不要用优化大站的方法套用小站,也不要用小站的方法对大站做决策,也不要用优化女装网站的方法给小站快消品网站的方法。它不伦不类,浪费人力和财力。
避免它:小牛筋疲力尽地拉着车!丹尼尔拉手推车浪费!把火箭发动机放在公共汽车上很危险!
用词来解释刚性:用户的刚性需求和用户搜索量非常大的词,值的大小决定刚性,刚性是关键词的灵魂。
暴力:在带有“关键词”的查询的结果排名中,值越大,单词的字符越强。硬攻击,主要用于定位词的分析)
勇气:标题查询的结果,数值越大,对手越多(我们要和对手战斗,所以要看对手的数量,奖励下一定有勇者)
硬度:直接输入搜索结果中显示的数字,根据显示的数字制定整体优化方案。硬度分为5个等级请牢记。
分级的原因是因为 1.知道字的大小 2.知道大小后,选择相应的方案来处理
数值参考
词的物理属性决定了你现阶段是否具备优化这些词的能力,能力因人而异。然后根据网站的不同发展时期和阶段调整优化方案。
以上4点反映了2条信息 1.为了避免这类词,将其覆盖词扩展为主要词 2.选择主要词后,可以确定对应的长尾词
04 词的竞争属性
善胜者不战,善阵者不战,善战者不败,善战者胜。善战者立于无敌之势而不失敌败——《孙子兵法:兵法》
白话文:不争就是最好的战斗。即使你赢了,你也必须付出巨大的代价。杀敌100,自己损失1000。真正懂得打架的人,往往无论怎么打,都不会失败。永远让自己面对无敌是最好的战斗。
在SEO解读方面,初衷只有一句话:避免竞争非常激烈的大词。如果孙武活在现代,应该是大师级的SEO人才。
术语解释提醒一点:收录高,但低索引的词也很有价值,所以不是绝对的。指数:反映该词在搜索引擎中的流行度,供用户搜索该词。数值越大,人气或需求越高,反之亦然。出价:在百度中对该词的出价数量
索引量:用“关键词”查询的结果页显示的信息数伪索引量:用关键词查询的结果页显示的信息数
以上4个参数反映2个信息1.主词的选择2.长尾词的选择3.优化方案的选择
05 词的空间属性
搜索引擎的世界和人的世界一样,有高低之分,地位之高低之分。所以......
所以你要明白生来就有一把金钥匙的道理,要努力让自己变得更好,才能赢得更多的生存空间和选择的权利。
术语解释阿拉丁:在百度搜索结果页面上,在显示的排名结果中,会出现基于百度的产品,均属于阿拉丁。
什么是阿拉丁?阿拉丁:我有一个家叫百度,我在家里可以为所欲为,排名?排名对我来说不存在。我说第一,我是第一。你不服气,退缩了。我只是喜欢看你看起来年轻,但对我的死无能为力。这是阿拉丁。
百度自己的儿子:百科,知道,贴吧,百家号...百度的儿子:视频,图片,地图,小度...
亲子系列产品属于百度自主产品,排名和权重高,胡说八道!你儿子喜欢吗?
干儿子流产品属于百度聚合产品,主要是功能化,甚至干儿子,排名都比你好,因为它的父亲是李彦宏,他们的家在百度。
百度之子
第一域名:排名前十的顶级域名网站的数量。
二级域名:二级域名网站在百度排名前10的页面数。
栏目页数:百度前10名中网站的栏目页数。内页:详情页网站在百度排名前10的页面数。
以上5个属性反映了2个信息 1、词的竞争激烈,你有信心赢吗?2. 还剩多少名额?你能在你唯一的生活空间中赢得一席之地吗?
06关键词分析流程
SEO工作是一项极其枯燥,但也非常过程和系统的工作。这是一个繁琐、自闭、折磨、总结的过程。并不像某些人说的那么简单,但非常有趣。
其实每个优秀的SEOER都有另一个身份:SEO数据分析师和光头师。谷歌和百度不一样,用的软件也不一样,所以脱发和死脑细胞也不一样,好感满满!
过程如下: 1.定语 2.挖词 3.构建词库 4.分析 5.词分布 6.构建词表 7.内容构建 8.反馈 9.再分析 10.总结
我这里放一些例子,大家可以手动做,记住,学知识不实践就是不学。
1. 关键词库示例
2.词的部分属性分析
以上10分中的每一个都可以写成至少7000-10000字的内容供你阅读,10分是7W-10W字,你确定要读吗?你肯定是看不到的。
好吧,萌新,以后你会听到有人告诉你,SEO从入门到精通30天。我们不算HTML前端代码的知识。如何在 30 天内进入精通?废话!搜索引擎优化绝对是基于数据,而不是经验和嘴巴。
巴郎太懒了,就不写过程了,太难写了,能写一本书。这项工作比程序员的小兄弟还累。请体谅。
最后的话
戒骄戒躁,专注最重要!
SEO之所以值得花钱,是因为你学会了,90%左右的行业,你可以随意挥手改造,敢问除了SEO行业还有哪些专业可以像SEO:行业太多了,单靠SEO就可以随意挥手。
关键词的分析流程已经写给大家了。先学框架,再学具体技术。SEO是一门艺术,绝对不是一门肤浅的技术那么简单。
学习绝对是一个痛苦和持续专注的问题。你不能投机取巧,你会从中受益。做一个有趣的人!再见巴伦!
事实:学术观点| 拿“双十一”开涮的文本挖掘:电商评论情感分析
随着网络购物的普及和各大电商之间的激烈竞争,为了提高客户服务质量,除了打价格战之外,了解客户的需求,倾听他们的声音越来越重要. 文本评论的数据挖掘。今天,通过学习《R语言数据挖掘实战》案例:电商评论与数据分析,从目标到操作内容与大家分享。
本文结构如下
1.要实现的目标
通过对客户的评论进行分析,通过一系列的方法来获取客户对某个产品的各个方面的态度和情感倾向,以及客户关注该产品的哪些属性,有哪些优势和优势。产品的缺点,以及产品的卖点是什么,等等...
2.文本挖掘的主要思想。
由于语言数据的特殊性,我们主要提取句子中的关键词,从而提取出评论的关键词,然后根据关键词的权重,这里我们使用空间向量的模型,将每个特征关键词转换为数字向量,然后计算其距离,然后聚类得到三类情绪,分别是正面、负面和中性。用途 代表顾客对产品的情感倾向。
3.文本挖掘的主要过程:
请输入标题 4. 案例流程介绍及原理介绍及软件操作
4.1 数据爬取
首先下载优采云软件,链接为,下载安装后注册账号登录,界面如上:
点击快速启动-新建任务,输入任务名称,点击下一步,打开京东热水器页面
将复制页面的地址复制到优采云,如下图:
观察网页的类型。由于收录美的热水器的页面不止一页,而且下方还有翻页按钮,我们需要创建一个循环点击下一页,然后在优采云中的京东页面点击下一页,然后在优采云中点击京东页面的下一页,在弹出的对话框列表中点击循环,点击下一页,如图:
然后点击一个产品,在弹出的页面点击添加元素列表处理第一个祖先元素-再次点击添加到列表-继续编辑列表,然后我们点击另一个产品的名称,点击在弹出的页面上添加到列表,这样软件会自动识别页面上的其他产品,然后点击创建列表完成,然后点击循环,从而在页面中创建一个产品列表循环抓取,
然后软件会自动跳转到第一个产品的具体页面,我们点击评论,在弹出的页面中点击这个元素,看到评论页面很多,那么我们需要创建一个循环列表,同上,点击下一页--loop through clicks。然后点击我们需要抓取的评论文本,在弹出的页面中点击创建元素列表处理一组元素--点击添加到列表--继续编辑列表,然后点击第二条评论点击进入弹出页面添加到列表 - 循环,然后单击评论文本以选择该元素的文本。嗯,这时候软件会循环抓取这个页面的文字,如图:
全部点击完成后,我们查看设计器,发现有4个循环,第一个是翻页,第二个是循环每个产品,第三个是翻评论页,第四个是循环抓取评论文本,所以我们需要将第4个循环嵌入到第3个循环中,然后将整体嵌入到第2个循环中,然后将整体嵌入到第1个循环中,即先点击下一页,再点击产品,然后点击下一个特价,然后抢评论,这个动作循环。那么我们只需要在设计器中将第4个循环拖到第3个循环,然后像这样拖下去。您可以: 将结果拖动如下:,然后点击下一步-下一步-点击采集就OK了。
4.2 文本去重
本例以京东平台下美的热水器客户评论为分析对象。按照流程,我们先用优采云爬取京东网站上美的热水器的顾客评论,部分数据如下!
通过简单的观察,我们可以发现评论的一些特点,
因此,我们需要对这些数据进行数据预处理,首先进行数据清洗,编辑距离去重其实是一种计算字符串相似度的方法。给定两个字符串,将字符串 A 转换为字符串 B 所需的删除、插入、替换等操作的次数称为从 A 到 B 的编辑路径。最短的编辑路径称为字符串 A 和 B 的编辑距离。对于比如“没正式用过,不知道怎么样,但是安装的材料成本确实有点高,380”和“还没用过,不知道质量,但是材料安装成本真的很贵,380" 编辑距离是9。
首先,我们需要重做重复的评论,也就是删除重复的评论。
另一个句子中的重复词,会影响评论中关键词在整体中出现的频率过高,影响分析结果。我们想压缩它。
还有一些无意义的评论,比如自动好评,我们要识别删除。
4.3 压缩语句的规则:
1.如果读入的和上面的列表一样,底部为空,放下 2.如果读入的和上面的列表一样,底部是,重复判断,清除下表 3. 如果读入与上表相同,则底部为,判断不重,清除顶部和底部 4. 如果读入与上表不同,则字符 >= 2、重复判断,清除上下列表 5.如果读取与上面的列表不同,底部为空,判断不重,继续穿上 6.如果读取与上面的列表不同,底部有,判断不重,放下 7.看完后判断上下,重则压缩。
4.4 然后我们进行中文分词。分词的一般原理是:
中文分词是指将一系列汉字分割成独立的词。分词结果的准确性对文本挖掘效果非常重要。目前,分词算法主要有四种:字符串匹配算法、基于理解的算法、基于统计的方法和基于机器学习的算法。
1、字符串匹配算法将待分割的文本字符串与字典中的单词进行精确匹配。如果字典中的字符串出现在当前要分割的文本中,则匹配成功。常用的匹配算法主要有前向最大匹配、反向最大匹配、双向最大匹配和最小分割。
2. 基于理解的算法通过模拟现实中人们对句子的理解效果进行分词。这种方法需要句法结构分析,需要大量的语言知识和信息,比较复杂。
3、基于统计的方法是利用统计的思想进行分词。单词由单个单词组成。在文本中,相邻的词一起出现的次数越多,它们形成词的概率就越大;因此,可以用词之间的共现概率来反映词的概率,并且可以统计相邻词的共同出现。出现次数,并计算它们的共现概率。当共现概率高于设定的阈值时,可以认为它们可能构成一个词
4. 最后是基于机器学习的方法:使用机器学习进行模型构建。构建大量分词文本作为训练数据,使用机器学习算法进行模型训练,利用模型对未知文本进行分词。
4.5 得到分词结果后
我们知道句子中经常会有一些“la”“ah”“but”,这些句子的情态助词、关联词、介词等,这些词对句子的特点没有贡献,我们可以去掉,还有一些专有名词,对于这个分析案例,“热水器”和“中国”经常出现在评论中,这是我们知道的,因为我们最初分析了关于热水器的评论,所以这些都是无用的信息。我们也可以删除。那么这里需要去掉这些词。一般通过已建立的自定义词库删除。
4.6 我们处理后的分词结果
然后我们可以进行统计,绘制词频云图,大致了解这些关键词的情况,为我们接下来的分析提供素材。操作如下:
4.7 分词后的结果
我们开始建模和分析。模型的选择方法有很多种,但总的来说只有两种,即向量空间模型和概率模型。这是一个代表模型。
模型 1:TF-IDF 方法:
方法A:对每个词的出现频率进行加权后,作为其维度的坐标,从而确定一个特征的空间位置。
方法B:以所有出现的词所收录的属性为维度,然后以词与各个属性的关系为坐标,然后定位一个文档在向量空间中的位置。
但实际上,如果某个词条在一类文档中频繁出现,则说明该词条能够很好地代表该类文本的特征,应该赋予此类词条更高的权重,并选择该词条作为该类文本的特征词将其与其他类型的文档区分开来。这就是 IDF 的不足之处。
模型 2:.LDA 模型
判断两篇文档相似度的传统方法是检查两篇文档中出现的词的数量,如TF-IDF等。这种方法没有考虑文本背后的语义关联,而可能出现在这两个文件中很常见。几乎没有,但这两个文件是相似的。
例如,有如下两句话:
“乔布斯离开了我们。” “苹果会降价吗?”
可以看出,上面两句话没有共同词,但是这两句话是相似的。如果用传统的方法判断两个句子肯定不相似,所以在判断文档相关性的时候,需要考虑文档的Semantics,而语义挖掘的武器就是主题模型,LDA就是其中比较多的一种有效的模型。
LDA模型是一种无监督的生成主题模型,它假设文档集中的文档按照一定的概率共享隐含主题集,隐含主题集由相关词组成。这里有三个集合,分别是文档集、主题集和词集。文档集到主题集服从概率分布,词集到主题集也服从概率分布。既然我们知道了文档集和词集,就可以根据贝叶斯定理找到主题集。具体算法很复杂,这里就不解释了。有兴趣的同学可以参考以下资料
4.8 项目总结
1.数据复杂度较高,文本挖掘面临的非结构化语言,文本非常复杂。
2.流程不同,文本挖掘更注重预处理阶段
3、一般流程如下:
五、应用领域:
一、舆情分析
2. 搜索引擎优化
3、其他行业的辅助应用
6.分析工具:
ROST CM 6是武汉大学沉阳教授开发和编码的国内唯一一个协助人文社科研究的大型免费社交计算平台。软件可以实现微博分析、聊天分析、全网分析、网站分析、浏览分析、分词、词频统计、英文词频统计、流量分析、聚类分析、等。用户数超过7,000。*敏*感*词*有剑桥大学、北海道大学、北京大学、清华大学、香港城市大学、澳门大学等100多所大学。下载地址:
RStudio 是 R 语言的集成开发环境 (IDE),其亮点在于出色的界面设计和编程辅助工具。它可以在多个平台上运行,包括 Windows、Mac、Ubuntu 和 Web 版本。另外,本软件是免费开源的,可以在官网下载:.
7.1 Rostcm6 实现:
打开软件 ROSTCM6
这是处理前的文本内容,我们会爬取数据,只去掉评论字段,然后保存为TXT格式,打开如下,按照流程,我们先去掉重复和字符,英文,数字和其他项目。
2.点击文本处理-一般处理-处理条件选择“重复行只保留一行”和“删除所有行中收录的所有英文字符”,去掉英文和数字等字符
这里是处理后的文档内容,可以看到数字和英文都被去掉了。
3、接下来进行分词处理。点击功能分析-分词(这里可以选择自定义词库,比如搜狗词库,或者其他)
分数文字处理的结果。简单观察一下,分词后,有很多无意义的停用词,如“in”、“under”、“one”等。
4. 接下来,我们过滤专有名词和停用词。并统计词频。点函数分析——词频分析(中文)
点击功能分析下的情感分析,进行情感分析。
并且可以实现云图的可视化。
7.2 R中的实现
这里需要安装几个必要的包,因为几个包的安装比较复杂,这里是链接 ... 82731
可以参考这个博客安装包。安装完成后就可以开始R文本挖掘了。以下代码说明文字较少,每个函数的作用对于初学者来说都比较陌生。读者可以先阅读这些文章文章,了解各个函数的作用后,使用R进行文本挖掘。链接如下:
博客/档案/29060
直接
读完之后就会清楚很多。
加载工作区库 (rJava)
图书馆(tmcn)
库(Rwordseg)
图书馆(商标)
setwd("F:/数据和程序/第十五章/计算机实验")
data1=readLines("./data/meidi_jd_pos.txt", encoding = "UTF-8")
头(数据1)
数据
————————————————————— #Rwordseg 分词
data1_cut=segmentCN(data1, nosymbol=T, returnType="tm")
删除\n、英文字母、数字 data1_cut=gsub("\n", "", data1_cut)
data1_cut=gsub("[az]*", "", data1_cut)
data1_cut=gsub("\d+", "", data1_cut)
write.table(data1_cut, 'data1_cut.txt', row.names=FALSE)
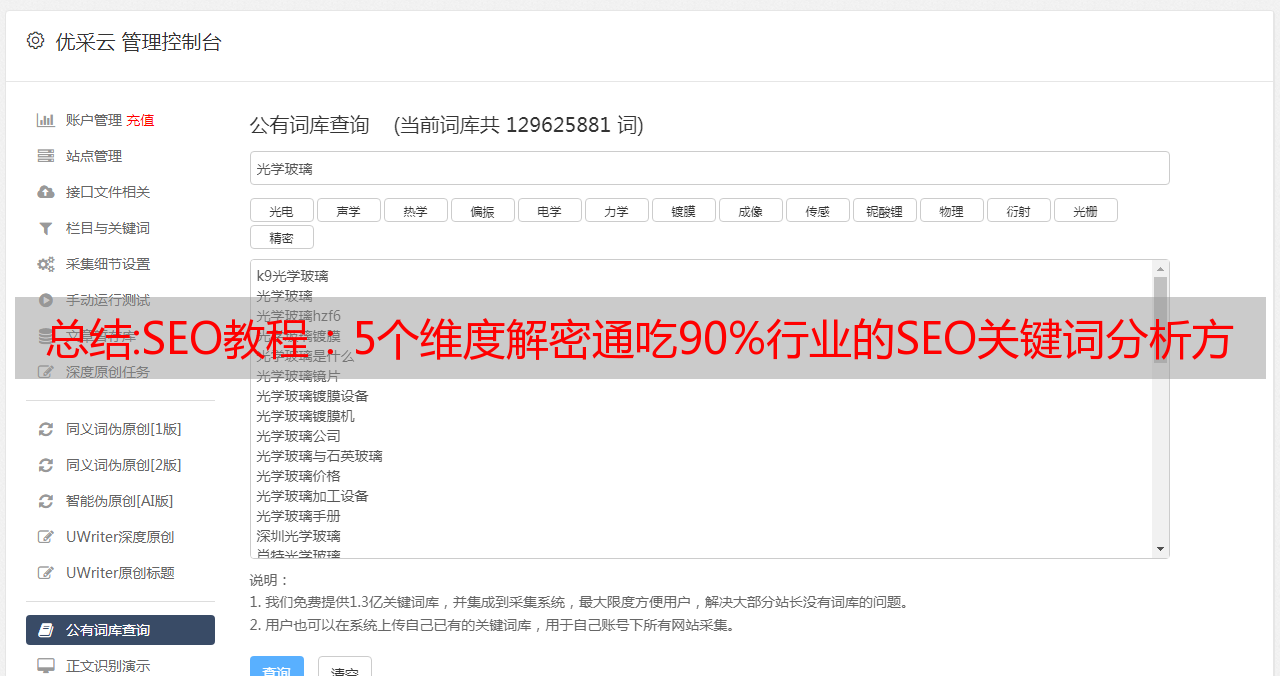
Data1=readLines('data1_cut.txt')
Data1=gsub('\"','',data1_cut)
长度(数据1)
头(数据1)
————————————————————————– #加载工作区
图书馆(自然语言处理)
图书馆(商标)
图书馆(大满贯)
图书馆(主题模型)
R语言环境下的文本可视化与话题分析setwd("F:/data and programs/chapter15/计算机实验")
data1=readLines("./data/meidi_jd_pos_cut.txt", encoding = "UTF-8")
头(数据1)
停用词
停用词 = 停用词 [611:长度(停用词)]
删除空格、字母 Data1=gsub("\n", "", Data1)
Data1=gsub("[a~z]*","",Data1)
Data1=gsub("\d+", "", Data1)
建立语料库 corpus1 = Corpus(VectorSource(Data1))
corpus1 = tm_map(corpus1, FUN=removeWords, stopwordsCN(stopwords))
创建文档条目矩阵 sample.dtm1
列名(as.matrix(sample.dtm1))
tm::findFreqTerms(sample.dtm1, 2)
unlist(tm::findAssocs(sample.dtm1, 'install', 0.2))
——————————————————————————
#主题模型分析
Gibbs = LDA(sample.dtm1, k = 3, method = "Gibbs", control = list(seed = 2015, burnin = 1000, thin = 100, iter = 1000))
最有可能的主题文档 Topic1
表(主题1)
每个主题的前 10 个术语术语1
条款1
—————————————————————-- #使用vec方法进行分词
图书馆(tmcn)
图书馆(商标)
库(Rwordseg)
图书馆(wordcloud)
setwd("F:/数据和程序/第十五章/计算机实验")
data1=readLines("./data/meidi_jd_pos.txt", encoding = "UTF-8")
d.vec1
wc1=getWordFreq(unlist(d.vec1), onlyCN = TRUE)
wordcloud(wc1$Word, wc1$Freq, col=rainbow(length(wc1$Freq)), min.freq = 1000)
#
8.结果展示与说明
这是分析结果的一部分。可以看出,大部分客户的评价都带有正面情绪,说明客户对美的热水器比较满意。对于哪些方面满意,哪些方面不满意,哪些方面可以保持,哪些方面需要改进,这就需要我们的成果再一次展示。
点击可视化工具,获取词频云图。根据云图,我们可以看到客户最关心的点,也就是评论里说得比较多的点。从图中我们可以看到“安装”、“大师”、“配件”、“加热”、“快捷”、“便宜”、“速度”、“品牌”、“京东”、“送货”“服务”“价格”“加热”等。关键词 出现的比较频繁,我们大致可以猜到26
此外,值得注意的是,在云图中,还有一些“好”、“大”、“满意”等字眼。我们还不知道这些词背后的语义,这需要我们找到相应的注释。,提取这些词对应的话题点。然后添加优化分析的结果
正文 | @白加黑治感冒
来源 | PPV 课程
原来的:
1
出版和投稿
2
读书报编辑部正在招收新生
现在我们的专栏“读书笔记”编辑部诚招青年教师和*敏*感*词*加入我们的阅读和写作活动。入选阅读对象包括SSCI、CSSCI优秀论文和*敏*感*词*学术专着。每个成员都参与编辑小组讨论、文章写作、校对和编辑(许多活动也是自愿捐款)。我们稳定的团队由 8 人组成,我们继续在语言学、翻译研究和文学方面招聘新人。由于阅读和写作任务的压力,围观的人很快就被淘汰了,欢迎有学术奉献精神的新人加入。加入方式:加公众号负责人微信:wonderdesire(请加真实姓名,并请以真实姓名进群:姓名-单位-研究方向)。如需其他业务联系,请发送电子邮件至:

