技术文章:网站SEO超级外链工具网站源码
优采云 发布时间: 2022-10-08 00:10技术文章:网站SEO超级外链工具网站源码
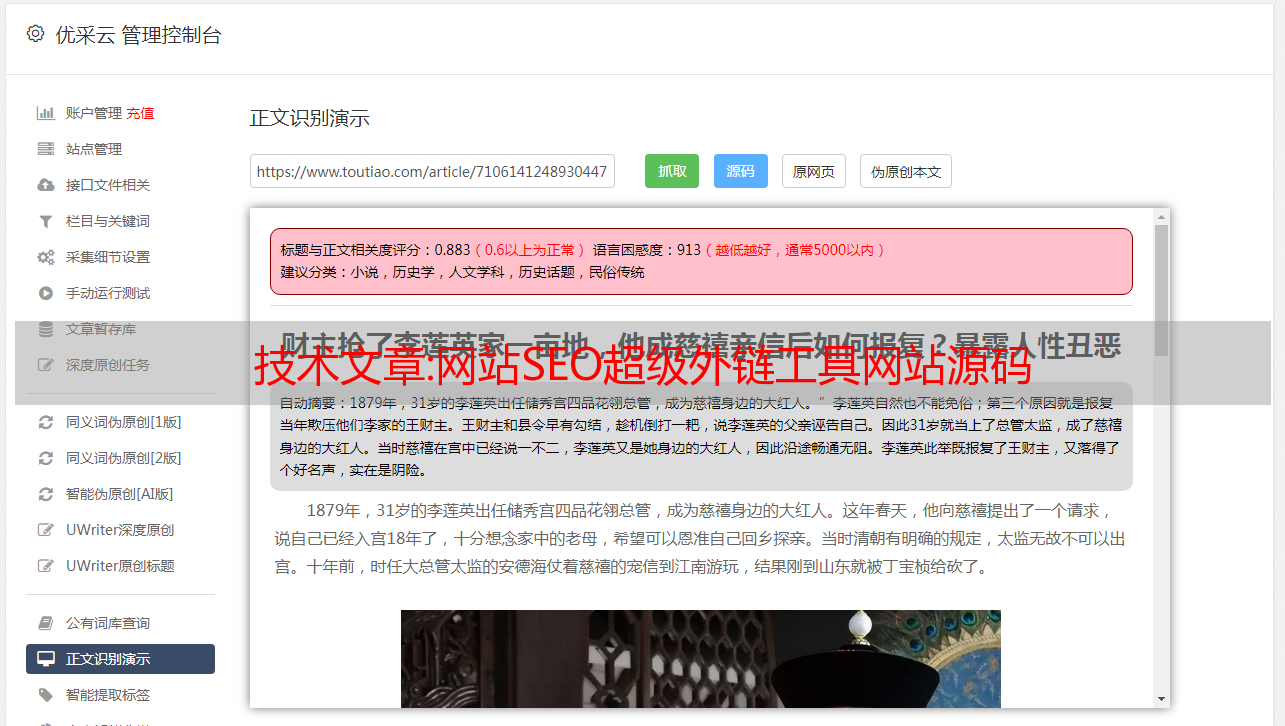
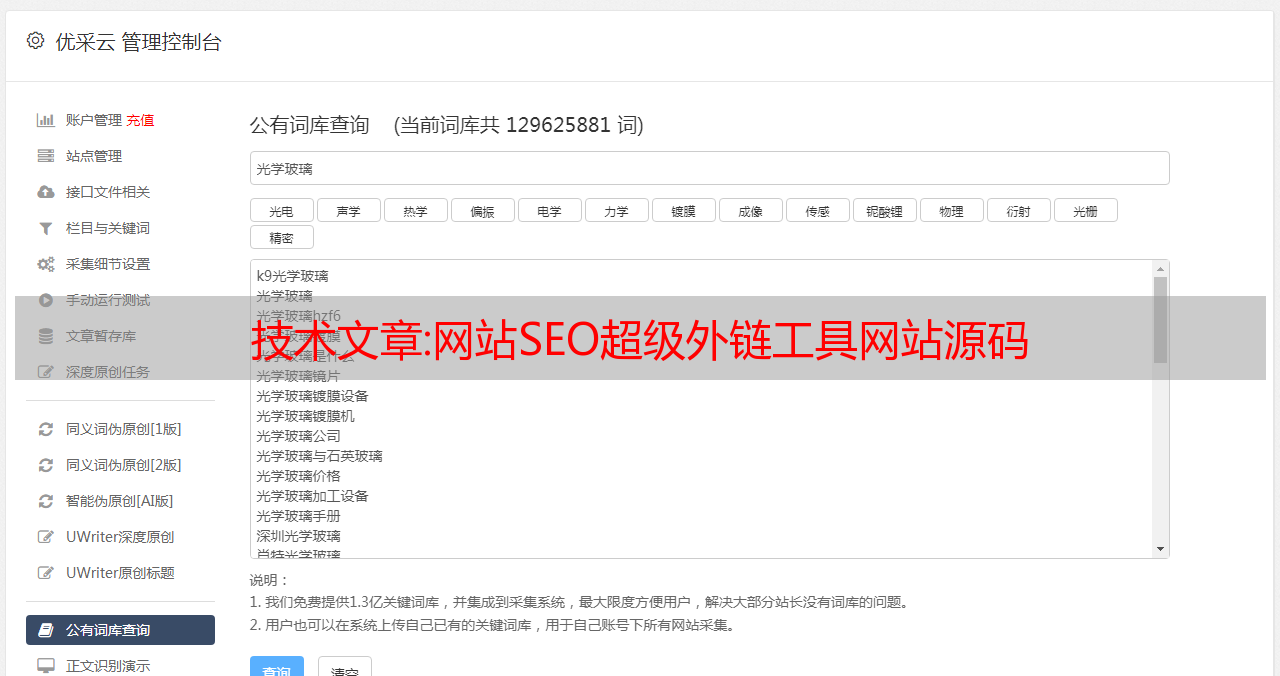
超级外链工具是一款线上全自动外链发行的推广工具。使用该工具,可以免费为网站在线批量添加外链,大大提高外链发布效率。是草根站长必备工具。工具的原理可能很多第一次使用外链工具的站长朋友都会担心同样的问题,就是会不会被百度K站,降级等风险?其实大家只要了解这类工具批量增加外链的原理,往往都会担心这个问题。这类工具的原理其实很简单。网上几乎所有的网站查询工具(如爱站net,去查网和本站站长工具)会留下查询网站的外链。如果查询网络上的每一个工具站,可以为查询构建大量的外链和外链工具 网站 正是这个原理,省去了你手动去各个工具站查询,自动化你的网站 用采集到的工具站列表在线查询。这种方式搭建的外链正式有效,无需担心被K入驻、被降级的风险。正是这个原理,让您免去手动访问每个工具站进行查询,通过采集的工具站列表自动在线查询网站。这种方式搭建的外链正式有效,无需担心被K入驻、被降级的风险。正是这个原理,让您免去手动访问每个工具站进行查询,通过采集的工具站列表自动在线查询网站。这种方式搭建的外链正式有效,无需担心被K入驻、被降级的风险。
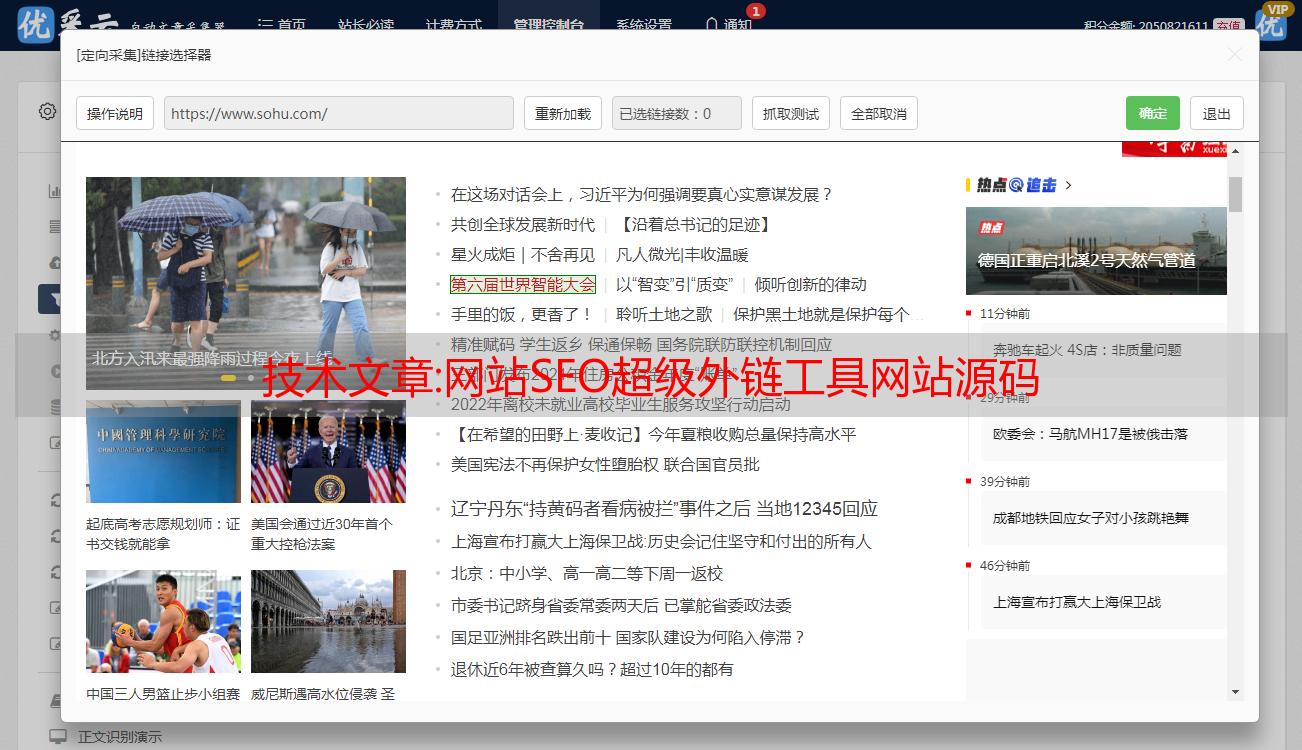
编号:80162
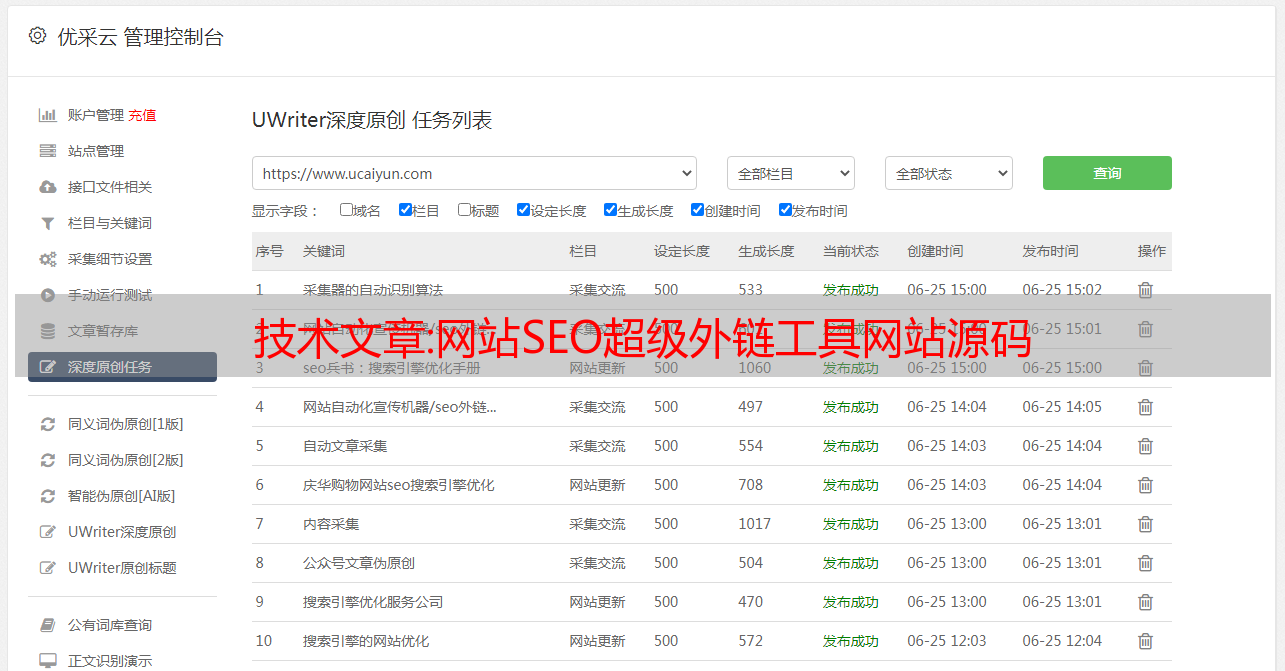
最新版本:新闻网页数据采集源码(新闻源码自动采集)
本篇文章将为大家讲述新闻网页数据采集的源码,以及自动采集新闻源码对应的知识点。我希望它对你有帮助。不要忘记为这个网站添加书签。
本文内容列表:
java如何实现网页爬虫,爬取新闻评论,可以获取新闻内容,但是网页源码中无法显示评论。
如果评论是通过 AJAX 显示的,那么抓取就有些困难了。
您的爬虫需要能够解释 JS,并破译 JS 的内容。
但是如果你只爬几个网站s,你可以为那些网站s开发专门的蜘蛛。手动分析它的JS,找到它的获取评论的AJAX接口,然后捕获它。就那么简单。
您也可以使用爬虫对浏览器进行操作,在其操作完成后通过浏览器的界面获取显示的内容。
获取网页源代码的问题,数据在jq中,如何获取呢?
有一种方法,可以用谷歌浏览器,按F12打开调试面板。使用调试工具(类似于放大镜)在文本中选中你想要的内容,在调试面板点击这段代码,ctrl+c复制。
最近工作需要采集点别人的数据,现在回到网页源代码。如何在源代码中采集取出想要的数据
最傻瓜式方法是编写一个函数来提取网页中字符串开头和字符串结尾之间的字符串。你搜索我的博客,我分别用VB和delphi写过。
C#自己写网页数据采集器:求思路。如果你有源代码,请发布。谢谢!
思路基本上是模仿浏览器,发送请求,然后接收返回的字符串(也就是网页的源代码)。剩下的很简单。根据你要采集的数据,按照一定的规则(比如正则化)分析、提取信息。
如何使用perl提取网页上的新闻内容?可以给源代码吗?看了很多资料还是不太明白
这很简单:
#!C:/perl/bin/perl
使用 LWP::UserAgent;
$browser=LWP::UserAgent-新;
$TARGET_URL="";
$response=$browser-post($TARGET_URL);
$htmlcontent=$响应内容;
打印 $html 内容。"\n";
$htmlcontent 收录网页的内容,其中只需要处理网页的内容即可获取
里面的信息。
请求程序或代码来爬取网页内容(两层或更多,delphi)
人们在抓取网页内容时,通常认为是从互联网上窃取数据,然后将采集到的数据链接到自己的互联网上。其实您也可以将采集采集的数据作为公司的参考,或者将采集到的数据与自己公司的业务进行比较。
目前网页采集多为3P代码(3P为ASP、PHP、JSP)。使用的最有代表性的是东一科技公司BBS的新闻采集系统,网上流传的新浪新闻采集系统等都是ASP程序使用的,但速度不怎么样理论上很好。. 用其他软件采集尝试多线程不是更快吗?答案是肯定的。你可以使用DELPHI、VC、VB或JB,但PB似乎更难做。下面使用 DELPHI 来解释 采集 网页数据。
1. 简单新闻采集
新闻采集 是最简单的,只要确定标题、副标题、作者、来源、日期、新闻正文和页码即可。网页内容必须在采集之前获取,所以在DELPHI中添加idHTTP控件(indy Clients面板中),然后使用idHTTP1.GET方法获取网页内容。声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数为字符串类型,用于指定 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样称呼它:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页的代码保存在tmpstr变量中。
接下来说说数据的截取。在这里,我定义了这样一个函数:
函数 TForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
变量
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource)+length(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,代表HTML源文件。
StrBegin:字符串类型,表示截取开始的标志。
StrEnd:字符串,标记截取的结束。
该函数将一段文本从 StrSource 返回到字符串 StrSource 中的 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,它们是由系统定义的。可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 S 中第一次出现的 Substr。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串 strsource 中从 in_sta(整数数据)到 in_end-in_star(整数数据)的字符串。
有了上面的函数,我们就可以通过设置各种标签来截取想要的文章内容。在程序中,我们需要设置很多标记比较麻烦。为了定位某个内容,我们必须设置它的开始和结束标记。例如,要获取网页上的文章标题,必须提前查看网页的代码,查看文章标题前后的一些特征码,并使用这些截取 文章 标题的特征代码。
让我们在实践中演示一下,假设 文章 的地址为 采集 是
代码是:
html
头

