汇总:智能云采集任何内容 众大云采集 8.3(开源版去版权)
优采云 发布时间: 2022-10-07 06:17汇总:智能云采集任何内容 众大云采集 8.3(开源版去版权)
插件实现的功能如下:
1.最新最热门的微信公众号文章采集每天自动更新。
2.
采集最新和最热门的信息每天都会自动更新。
3. 输入关键词并采集与此关键词相关的最新内容
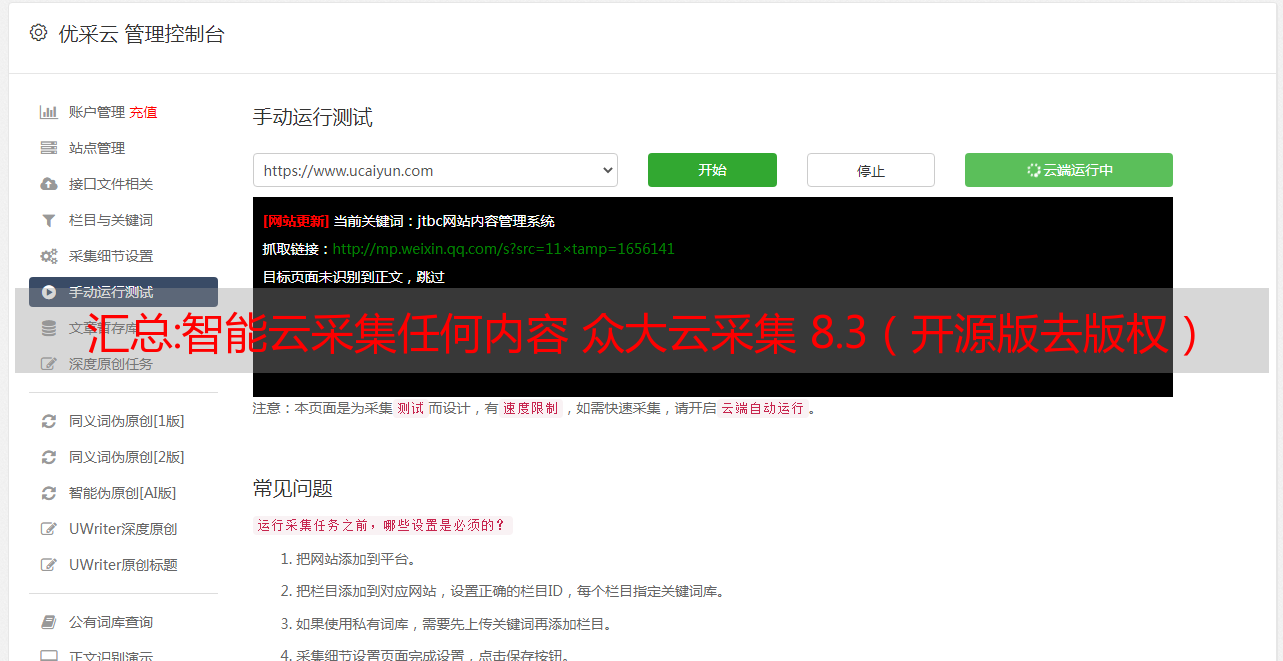
4. 输入网址并采集此网址的内容
5. 支持云通用伪原创和本地伪原创
6. 本地伪原创可以在插件设置中自定义同义词库
7.图片一键即可本地化存储,图片永不丢失
8.您可以在后台设置常用采集关键词
9. 您可以指定用户组和部分以使用采集功能
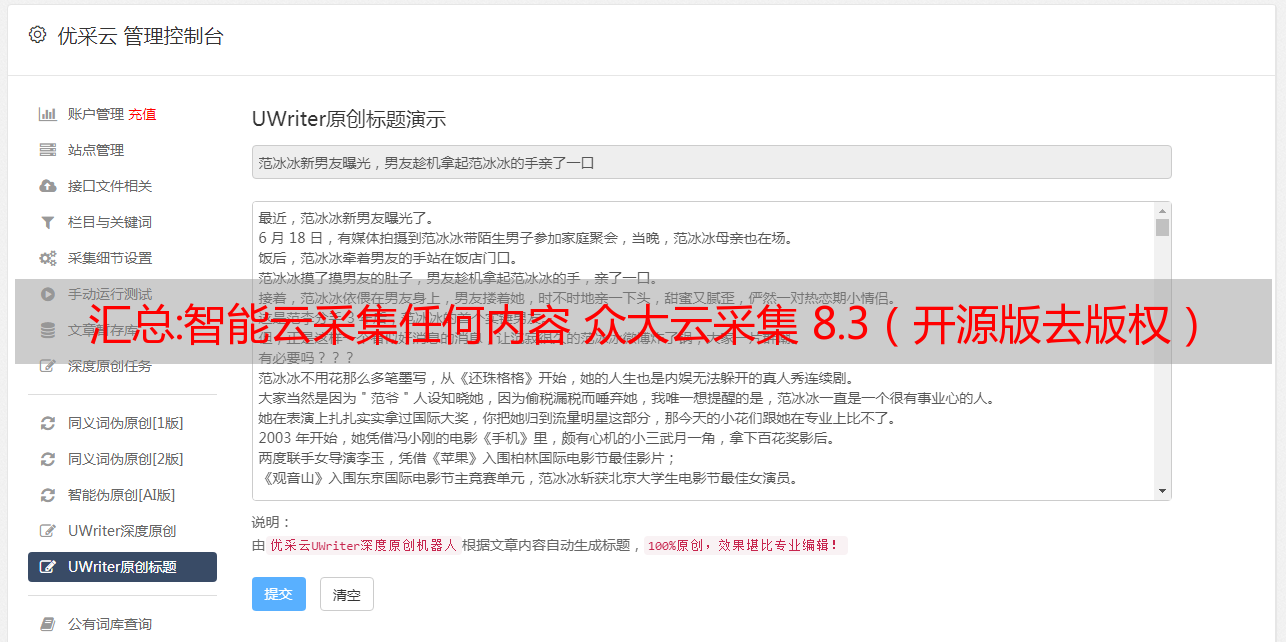
功能未列出,有关更*敏*感*词*,请安装此插件体验。
链接:
下载地址(点击号码下载)→:28665
附加内容 (2017-9-28 19:28):
技巧:不编程也能爬虫?*敏*感*词*教你如何从互联网采集海量数据
◆◆◆
很多朋友会问:几十万的租房、二手房、工资,甚至天气数据从哪里来?其实这些数据十分钟之内就可以采集了!
一般我都会回答,我用专门的工具快速抓取,不用编程。之后,你肯定会被问到,这个工具在哪里可以下载?
最近比较忙,说的很多写作任务都没有完成。授人以渔,不如授人以渔。我决定将所有这些软件开源到 GitHub。
免费使用,开源!从那以后,估计很多做爬虫的工程师都会丢掉工作。. . 因为我的目标是让普通人可以使用它!
这篇文章介绍了爬虫的一般原理,文末会有程序地址。
◆◆◆
什么是爬行动物
什么是爬行动物
互联网是一张大网,采集数据的小程序可以形象地称为爬虫或蜘蛛。
爬虫的原理很简单。当我们访问网页时,我们会点击翻页按钮和超链接,浏览器会为我们请求所有的资源和图片。所以,你可以设计一个可以模拟人在浏览器上的操作的程序,让网站把爬虫误认为是普通访问者,它就会乖乖的发回需要的数据。
爬虫有两种,一种是百度(黑)这样的搜索引擎爬虫,什么都抓。另一个是开发的,只需要精准抓取需要的内容:比如我只需要二手房信息,旁边的广告和新闻都不需要。
像爬虫这样的名字不是个好名字,所以我把这个软件命名为Hawk,意思是“鹰”,可以准确快速的捕捉猎物。基本上不需要编程,通过图形化的拖拽操作就可以快速设计爬虫,有点像Photoshop。它可以在20分钟内编写一个爬虫征求公众意见(简化版只需3分钟),然后让它运行,
以下是使用Hawk抢二手房的视频,建议在wifi环境下观看:
◆◆◆
自动将网页导出到 Excel
那么,一个页面这么大,爬虫怎么知道我想要什么?
当然,人们很容易看出上图中的红框是二手房信息,但机器并不知道。
网页是一棵结构化的树,重要信息所在的节点往往繁茂。举个不恰当的例子,一大群人形成了树状的家谱。谁是最强大的?当然:
每个人都会觉得这个家庭很了不起!
我们对整个树结构打分,自然能找到最强大的节点,也就是我们想要的表。找到了最好的父亲后,虽然儿子们都差不多:高大帅气,两条胳膊两条腿,这些都是共通点,信息量再多也不为过。我们关心的是特性。大儿子带锥子的脸和其他人都不一样,那张脸是重要的信息;三儿子是最富有的——钱是我们关心的。因此,比较儿子的不同属性,我们可以知道哪些信息是重要的。
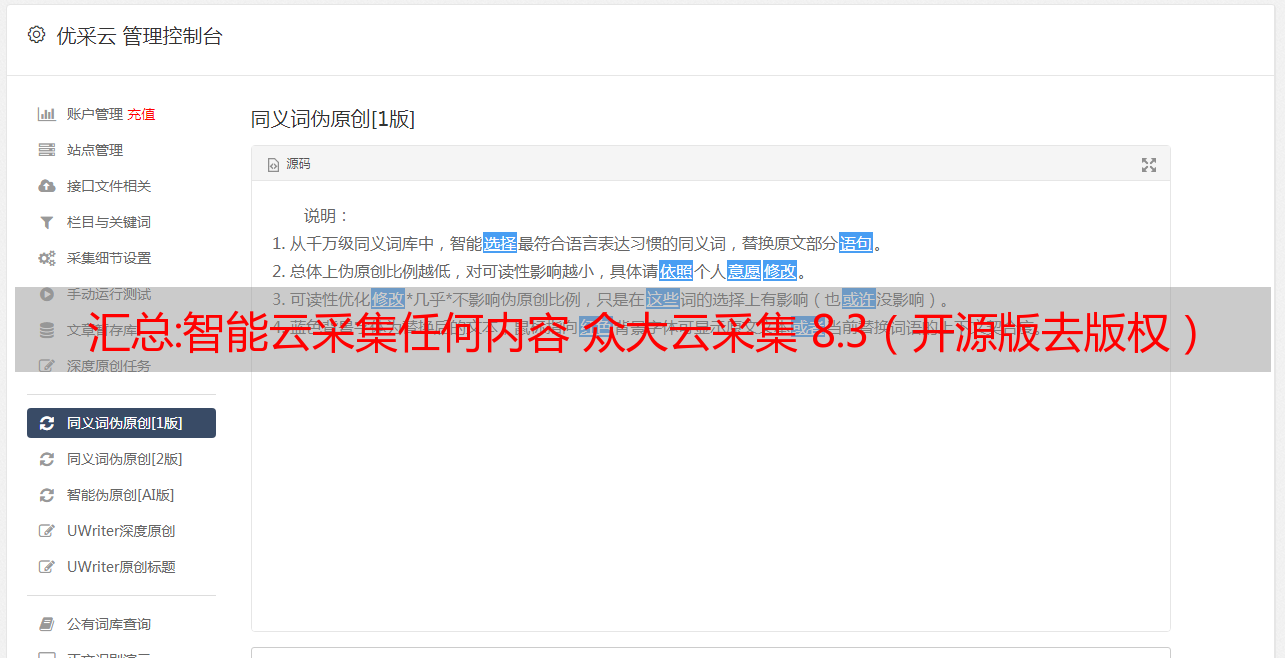
回到网页采集的例子,通过一组有趣的算法,给出一个网页的地址,软件会自动转换成Excel!!)
◆◆◆
破解翻页限制
获取一页的数据是不够的,我们要获取所有页面的数据!这个很简单,我们让程序依次请求第1页、第2页……数据被采集回来
就这么简单吗?网站你的宝贵资料怎么能这么轻易就被抢走?所以只能翻到第50或100页。链条是这样的:
这对我们来说并不难,每页有30条数据,100页最多可以呈现3000条数据。北京16个区县有2万个社区,但每个区的社区数量不到3000个。我们可以分别获取每个区的社区列表。每个小区最多有300多套二手房在售,让你获得链家所有的二手房。
然后我们启动抓取器,Hawk会给每个子线程分配任务(可以理解为机器人):把这个社区的所有二手房都给我抢!然后你会看到一个壮观的场景:一堆小机器人,一起从 网站 移动数据,有没有超级牛雷霆?100 个任务同时进行!!上完厕所就被抓了!!!
◆◆◆
清洁:识别和转换内容
获取的数据如下所示:
但是你会看到里面会有一些奇怪的字符应该被删除。xx平方米应提取数字。而售价,有的213万元,有的373万元,这些都很难对付。
不过没关系!Hawk可以自动识别所有数据:
哈哈,那你就可以轻松拿这些数据分析,纯净无污染!
◆◆◆
破解需要登录网站
当然,这里的意思不是破解用户名和密码,不够强。网站的部分数据需要登录才能访问。它也不打扰我们。
当您打开 Hawk 的内置嗅探功能时,Hawk 就像一个录音机,记录您对目标 网站 的访问操作。然后它会重放它,启用自动登录。
您是否担心 Hawk 会保存您的用户名和密码?如何不保存自动登录?但是 Hawk 是开源的,所有代码都经过审查且安全。您的私人信息只会存在于您自己的硬盘上。
(我们通过这种方式自动登录大众点评)
◆◆◆
我也可以捕获数据吗?
理论上是的。但道高一尺,魔高一尺,不同的网站差别很大,对付爬虫的技巧也很多。而且小虫子对细节非常敏感。只要你犯了一个错误,接下来的步骤就可能无法进行。
怎么做?沙漠君保存和分享之前的操作,加载这些文件可以快速获取数据。
如果你还有其他网站采集需求,可以去找你的程序员同行,请他们帮忙采集数据,或者请他们试试Hawk,看看谁更有效率。
如果你是文科生,建议你看看东野奎武和村上春树。上手这么复杂的软件会让你发疯。我应该求助于谁来帮助捕获数据?嘿嘿嘿...
◆◆◆
我在哪里可以获得软件和教程?
Hawk:用C#/WPF软件编写的高级爬虫&ETL工具介绍
HAWK是一款数据采集和清理工具,按照GPL协议开源,可以灵活有效的采集来自网页、数据库、文件,并快速生成、过滤、转换等操作. 它的功能最适合的领域是爬虫和数据清洗。
Hawk的意思是“鹰”,可以高效准确地杀死猎物。
HAWK 是用 C# 编写的,它的前端界面是使用 WPF 开发的,并且它支持插件扩展。通过图形化操作,可以快速创建解决方案。
GitHub地址:
它的 Python 等价物是 etlpy:
笔者专门开发的项目文件已发布在GitHub上:
使用时,点击文件加载工程。
如果您不想编译,可执行文件位于:
密码:4iy0
构建路径位于:
Hawk.Core\Hawk.Core.sln
感谢作者授权转载,稿件有些改动,作者点击文末推荐查看大数据文摘的其他投稿文章。
<strong style="max-width: 100%; line-height: 28px; white-space: normal; color: rgb(61, 170, 214); font-size: 20px; box-sizing: border-box !important; word-wrap: break-word !important;">◆ ◆ ◆</strong>

