总结:编辑了一篇个人博客的文章,简要记录一下具体的过程
优采云 发布时间: 2022-10-07 02:06总结:编辑了一篇个人博客的文章,简要记录一下具体的过程
微信文章自动采集软件-kiwojian推荐给大家!大家有问题可以随时来咨询我或者留言!本文转载自kiwojian
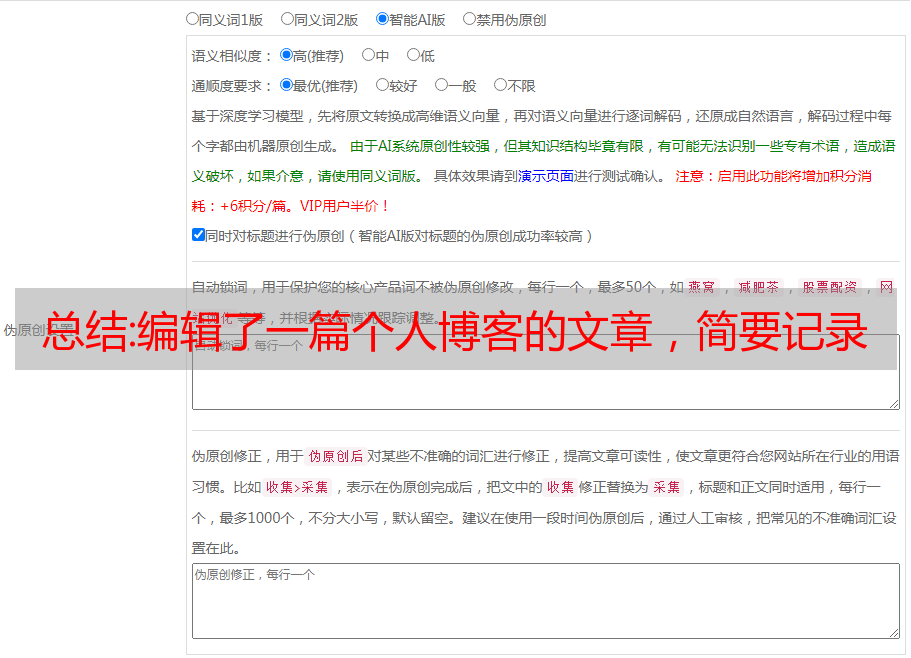
。
编辑了一篇个人博客的文章,简要记录一下具体的过程:具体操作:需要到实时信息平台(例如gmail)检索exx(邮局emailnetwork,简称emailnet)网站上的内容然后点击阅读:准备工作:目标网站主页是一个采集站点,域名是。选择邮局官网的网址打开,然后点击红框内容:选择下方选项:在下方选择一个主题(看自己对网站划分为几个部分)然后点击"download"会自动下载一个文件,下载下来的文件保存在exx文件目录内。
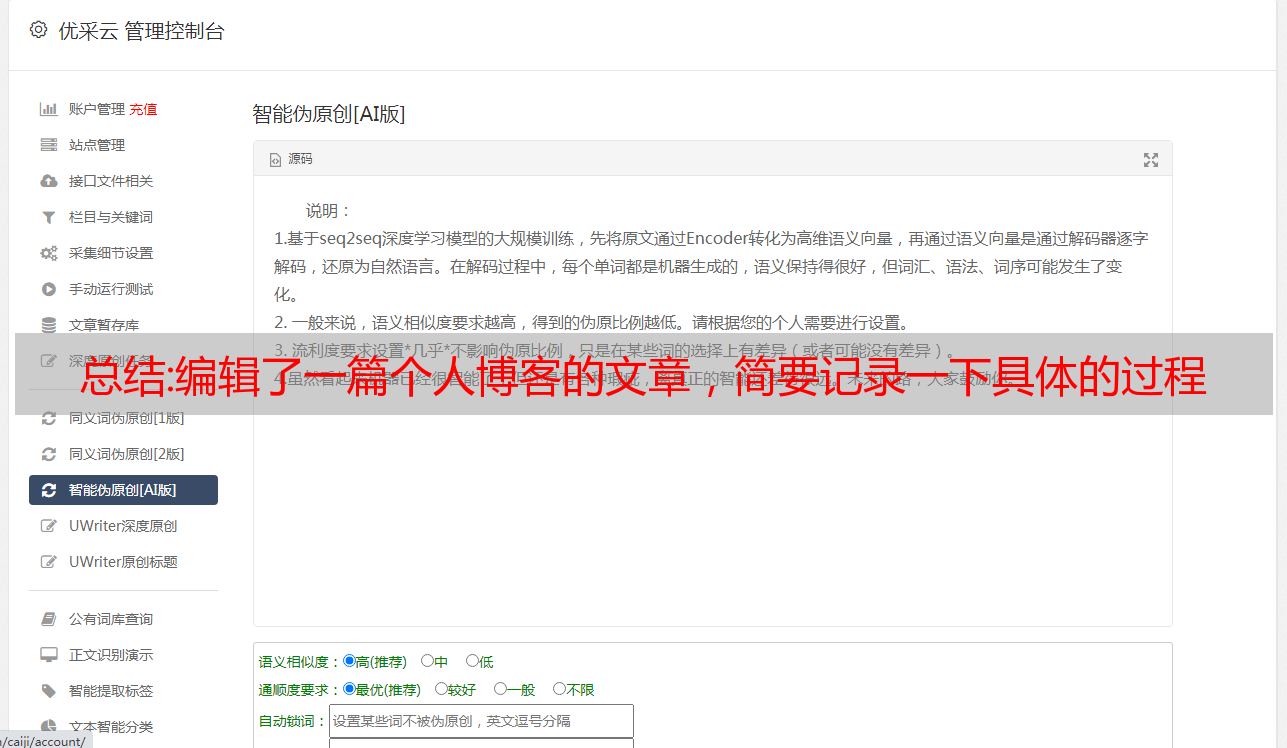
右键复制链接,粘贴到浏览器内阅读:浏览器打开之后,粘贴以上的链接,会进入以下界面。接下来就是编辑采集代码。复制以下代码,并且粘贴到下面:编写脚本之后保存为page.js,然后在浏览器中访问(当然最好是能翻墙),就可以看到爬虫爬到exx网站上的所有exx信息。如果我们发现某个exx的名称为xxx的friendsofsail的帖子发布了时间为2011-06-26,再手动复制过去,不同的服务器,自然而然查询时间就不一样了,得到的是乱码,自然就提示该cookie已失效了。
(微博上有人提供了脚本可以这样爬wikipedia,google中也有不少,可以一试)这时我们可以再次从以上的js源代码爬出来。右键复制图中代码并粘贴到浏览器或者打开谷歌浏览器的翻译模式,接着翻译图中的语言内容,接着就可以在浏览器里面正常访问了。如果提示emailnet_server服务器端自动发送udp数据包到gmail。
接着关闭浏览器,执行以下代码并重启服务器:可以看到代码中的"readthisall"这一行,解决了wiki上"jarudpforgmailfeedback"这个错误,这里不明白,可以看看下面的其他工作。root@workflow!emailnet-p-m"xxx_xxxx.txt"!!foreachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachforeachf。

