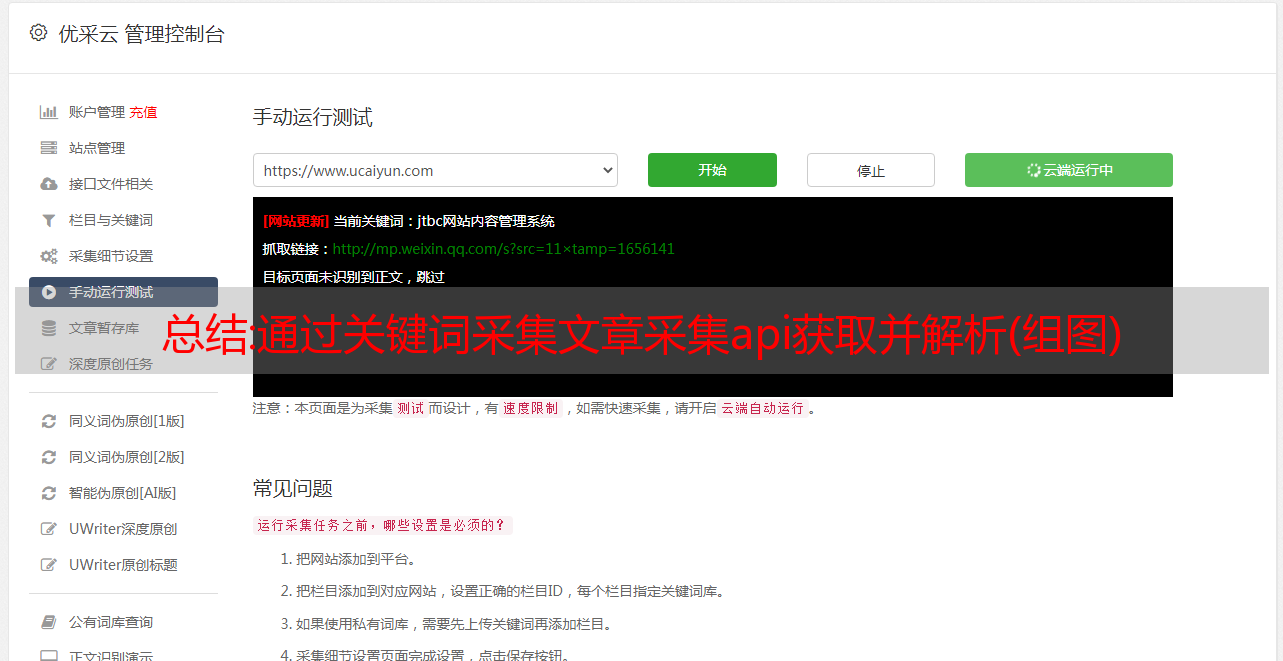
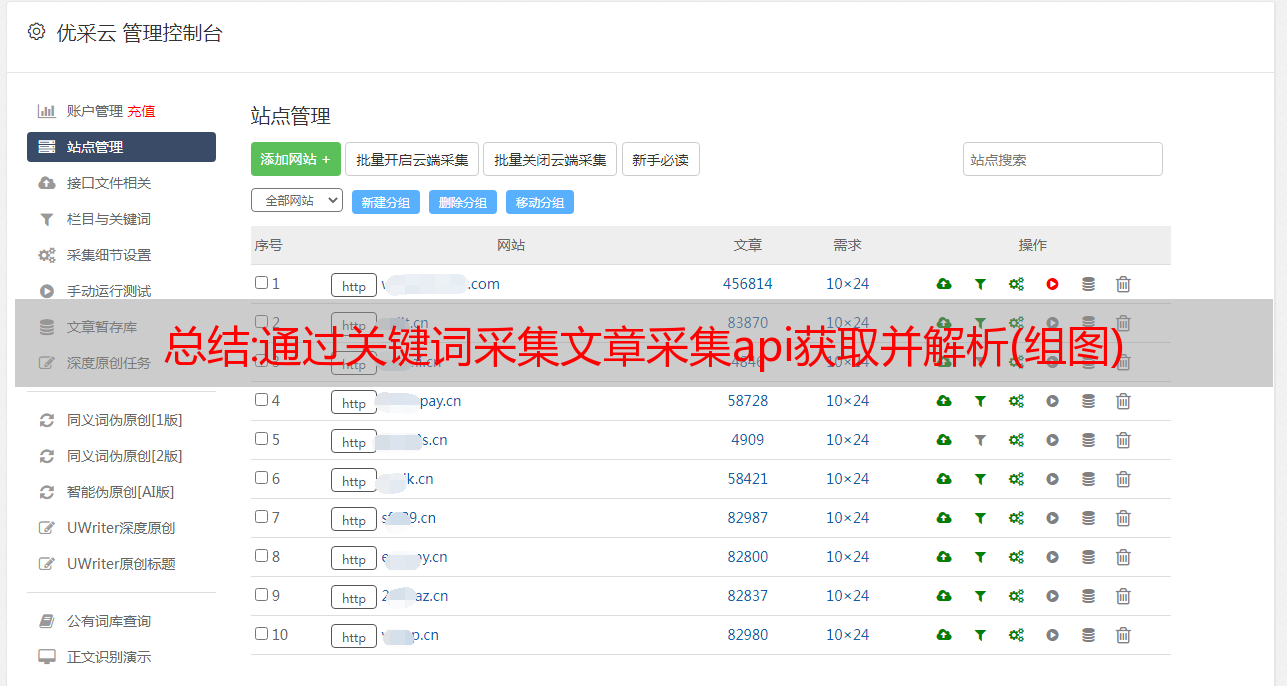
总结:通过关键词采集文章采集api获取并解析(组图)
优采云 发布时间: 2022-10-06 02:09通过关键词采集文章采集api获取并解析网站源代码爬取网站关键词数据后来我发现写代码爬网站还不如自己先上网找几篇好的文章看看然后根据以上方法爬取数据讲道理我很佩服某个人物很佩服他写的文章但我还是劝大家阅读,而不是爬爬取百度的一个文章,一个采集数据,我是这么想的,下面讲原理一般网站是根据上下文与关键词来推荐信息的,在我看来,这个文章是网站未来要推荐给用户的,所以我来爬取网站信息所以说,必须获取下面提供python框架说好的无(墙)止(内)尽(),各位看官拿好小板凳,等我安排详细的代码。
python爬虫框架gerator框架介绍上下文推荐算法例子中上下文推荐基于urllib2框架内核可以爬取请求headers,标题,网站域名,访问日期等方法一方法二要爬取注册表列表格先拿一份登录页面下面就用上这个东西再抓全是java代码,比较难,先放一下,让大家眼熟。
每当我们发现自己不得不去写采集代码,搞清楚一些什么是爬虫,这可能是一件麻烦事。爬虫的主要目的就是把现实世界的信息向网络爬取,爬取网络信息后,经过过滤、整理、合并形成符合我们需求的结果,至于这些信息有没有价值那是另一个方面的事。而获取网站数据、爬取网站数据我们可以通过爬虫框架gerator实现。今天主要介绍一下gerator。
它是gerativeutilityframework的缩写,是gerativeapi的一个开源版本。gerator用于对网络网站进行采集、数据挖掘、数据交换、数据分析、数据可视化,可以自动抓取网站所有数据,同时支持网站批量数据抓取(包括不限于登录)。它有三个核心函数:geratorfunction(用于获取网站的模拟方法,实现代码的通用化,它实现了一个程序的全部功能,但是通过gerator的框架,我们不需要重写它的代码)portionfunction(用于从发布的url请求数据或者从url中匹配出匹配指定网站的数据,它用于网站数据的抓取)urlinfofofunction(用于匹配发布的urlurl,并获取每个url的数据列表,发布源url列表,时间戳,或者url发布时间戳等)了解了gerator后,我们就可以着手写我们自己的爬虫框架了。
首先,我们可以创建一个python工程,使用antirez为我们的工程命名,然后创建我们的爬虫框架,这个框架在我们自己的工程里可以找到。创建完工程后,接下来我们使用gerator工具函数,函数有两个核心部分,一个是爬虫,一个是工具,这两个部分的数据保存在同一个变量里。比如我们要抓取某百科的网站页面的数据,那么我们会把要抓取数据的页面数据以及该页面要用到的关键字数据保存在一个变量里(或者这个工具使用全局变量)。而gerator。

